 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diversity Paradox revisited: Systemic Effects of Feedback Loops in Recommender Systems
Feb 18, 2026Recommender systems shape individual choices through feedback loops in which user behavior and algorithmic recommendations coevolve over time. The systemic effects of these loops remain poorly understood, in part due to unrealistic assumptions in existing simulation studies. We propose a feedback-loop model that captures implicit feedback, periodic retraining, probabilistic adoption of recommendations, and heterogeneous recommender systems. We apply the framework on online retail and music streaming data and analyze systemic effects of the feedback loop. We find that increasing recommender adoption may lead to a progressive diversification of individual consumption, while collective demand is redistributed in model- and domain-dependent ways, often amplifying popularity concentration. Temporal analyses further reveal that apparent increases in individual diversity observed in static evaluations are illusory: when adoption is fixed and time unfolds, individual diversity consistently decreases across all models. Our results highlight the need to move beyond static evaluations and explicitly account for feedback-loop dynamics when designing recommender systems.
Explanations Go Linear: Interpretable and Individual Latent Encoding for Post-hoc Explainability
Apr 29, 2025



Post-hoc explainability is essential for understanding black-box machine learning models. Surrogate-based techniques are widely used for local and global model-agnostic explanations but have significant limitations. Local surrogates capture non-linearities but are computationally expensive and sensitive to parameters, while global surrogates are more efficient but struggle with complex local behaviors. In this paper, we present ILLUME, a flexible and interpretable framework grounded in representation learning, that can be integrated with various surrogate models to provide explanations for any black-box classifier. Specifically, our approach combines a globally trained surrogate with instance-specific linear transformations learned with a meta-encoder to generate both local and global explanations. Through extensive empirical evaluations, we demonstrate the effectiveness of ILLUME in producing feature attributions and decision rules that are not only accurate but also robust and faithful to the black-box, thus providing a unified explanation framework that effectively addresses the limitations of traditional surrogate methods.
Interpretable and Fair Mechanisms for Abstaining Classifiers
Mar 24, 2025Abstaining classifiers have the option to refrain from providing a prediction for instances that are difficult to classify. The abstention mechanism is designed to trade off the classifier's performance on the accepted data while ensuring a minimum number of predictions. In this setting, often fairness concerns arise when the abstention mechanism solely reduces errors for the majority groups of the data, resulting in increased performance differences across demographic groups. While there exist a bunch of methods that aim to reduce discrimination when abstaining, there is no mechanism that can do so in an explainable way. In this paper, we fill this gap by introducing Interpretable and Fair Abstaining Classifier IFAC, an algorithm that can reject predictions both based on their uncertainty and their unfairness. By rejecting possibly unfair predictions, our method reduces error and positive decision rate differences across demographic groups of the non-rejected data. Since the unfairness-based rejections are based on an interpretable-by-design method, i.e., rule-based fairness checks and situation testing, we create a transparent process that can empower human decision-makers to review the unfair predictions and make more just decisions for them. This explainable aspect is especially important in light of recent AI regulations, mandating that any high-risk decision task should be overseen by human experts to reduce discrimination risks.
A linguistic analysis of undesirable outcomes in the era of generative AI
Oct 16, 2024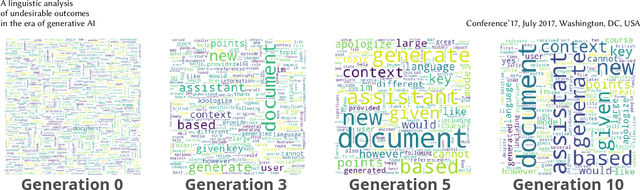
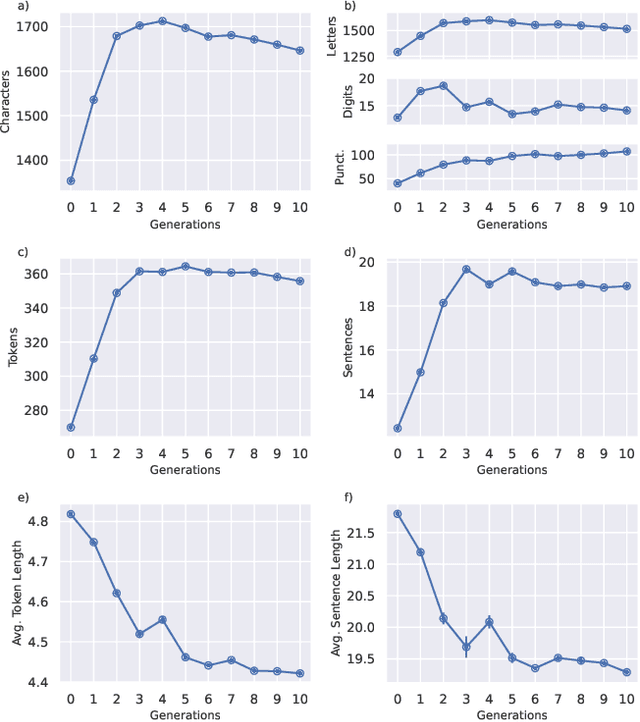
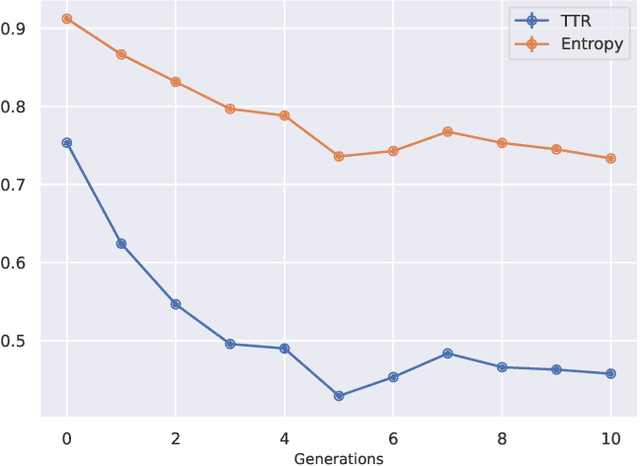
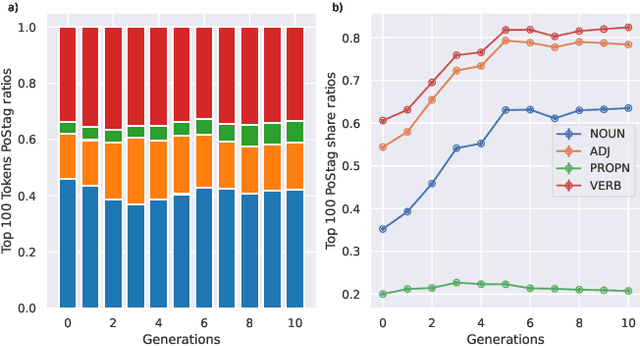
Recent research has focused on the medium and long-term impacts of generative AI, posing scientific and societal challenges mainly due to the detection and reliability of machine-generated information, which is projected to form the major content on the Web soon. Prior studies show that LLMs exhibit a lower performance in generation tasks (model collapse) as they undergo a fine-tuning process across multiple generations on their own generated content (self-consuming loop). In this paper, we present a comprehensive simulation framework built upon the chat version of LLama2, focusing particularly on the linguistic aspects of the generated content, which has not been fully examined in existing studies. Our results show that the model produces less lexical rich content across generations, reducing diversity. The lexical richness has been measured using the linguistic measures of entropy and TTR as well as calculating the POSTags frequency. The generated content has also been examined with an $n$-gram analysis, which takes into account the word order, and semantic networks, which consider the relation between different words. These findings suggest that the model collapse occurs not only by decreasing the content diversity but also by distorting the underlying linguistic patterns of the generated text, which both highlight the critical importance of carefully choosing and curating the initial input text, which can alleviate the model collapse problem. Furthermore, we conduct a qualitative analysis of the fine-tuned models of the pipeline to compare their performances on generic NLP tasks to the original model. We find that autophagy transforms the initial model into a more creative, doubtful and confused one, which might provide inaccurate answers and include conspiracy theories in the model responses, spreading false and biased information on the Web.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024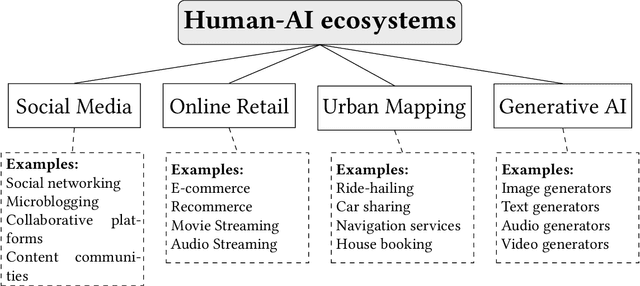
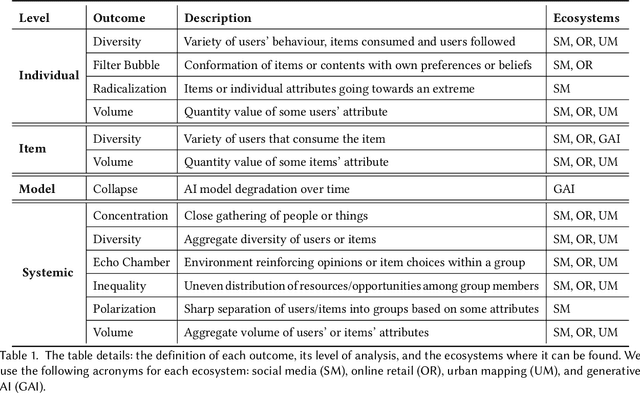
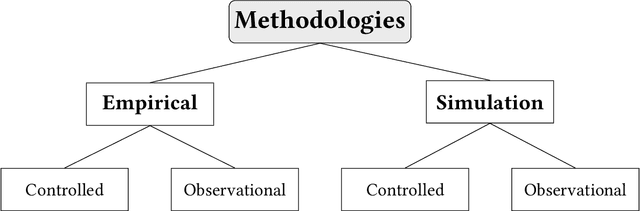
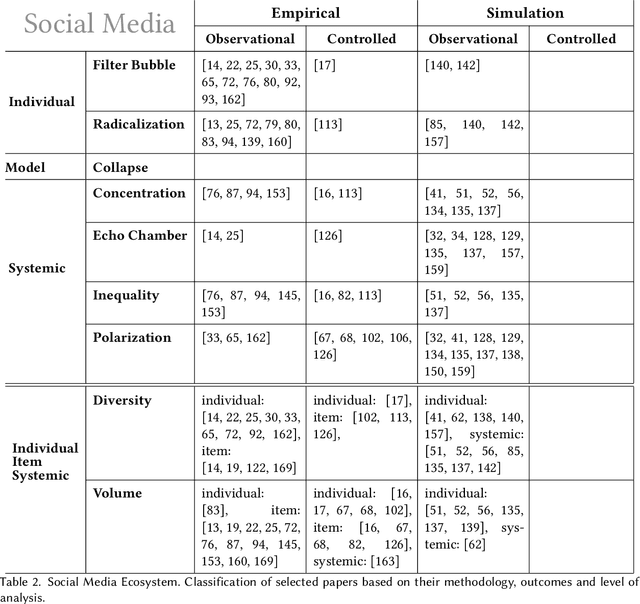
Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
AI, Meet Human: Learning Paradigms for Hybrid Decision Making Systems
Feb 09, 2024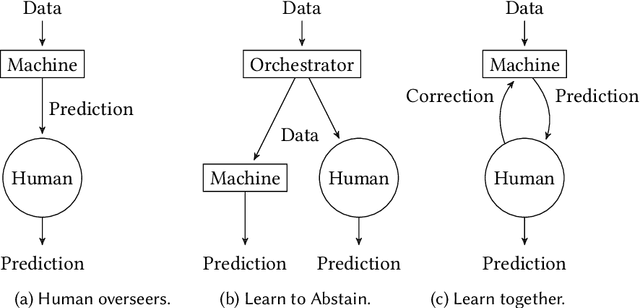



Everyday we increasingly rely on machine learning models to automate and support high-stake tasks and decisions. This growing presence means that humans are now constantly interacting with machine learning-based systems, training and using models everyday. Several different techniques in computer science literature account for the human interaction with machine learning systems, but their classification is sparse and the goals varied. This survey proposes a taxonomy of Hybrid Decision Making Systems, providing both a conceptual and technical framework for understanding how current computer science literature models interaction between humans and machines.
Social AI and the Challenges of the Human-AI Ecosystem
Jun 23, 2023


The rise of large-scale socio-technical systems in which humans interact with artificial intelligence (AI) systems (including assistants and recommenders, in short AIs) multiplies the opportunity for the emergence of collective phenomena and tipping points, with unexpected, possibly unintended, consequences. For example, navigation systems' suggestions may create chaos if too many drivers are directed on the same route, and personalised recommendations on social media may amplify polarisation, filter bubbles, and radicalisation. On the other hand, we may learn how to foster the "wisdom of crowds" and collective action effects to face social and environmental challenges. In order to understand the impact of AI on socio-technical systems and design next-generation AIs that team with humans to help overcome societal problems rather than exacerbate them, we propose to build the foundations of Social AI at the intersection of Complex Systems, Network Science and AI. In this perspective paper, we discuss the main open questions in Social AI, outlining possible technical and scientific challenges and suggesting research avenues.
Dense Hebbian neural networks: a replica symmetric picture of supervised learning
Nov 25, 2022



We consider dense, associative neural-networks trained by a teacher (i.e., with supervision) and we investigate their computational capabilities analytically, via statistical-mechanics of spin glasses, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as quality and quantity of the training dataset, network storage and noise, that is valid in the limit of large network size and structureless datasets: these networks may work in a ultra-storage regime (where they can handle a huge amount of patterns, if compared with shallow neural networks) or in a ultra-detection regime (where they can perform pattern recognition at prohibitive signal-to-noise ratios, if compared with shallow neural networks). Guided by the random theory as a reference framework, we also test numerically learning, storing and retrieval capabilities shown by these networks on structured datasets as MNist and Fashion MNist. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate supervised learning in neural networks, beyond the shallow limit, in general.
Dense Hebbian neural networks: a replica symmetric picture of unsupervised learning
Nov 25, 2022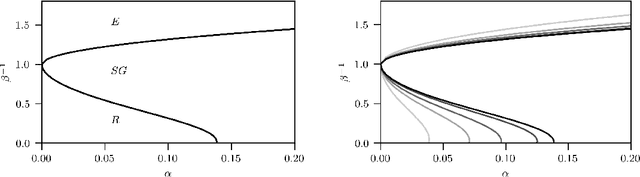
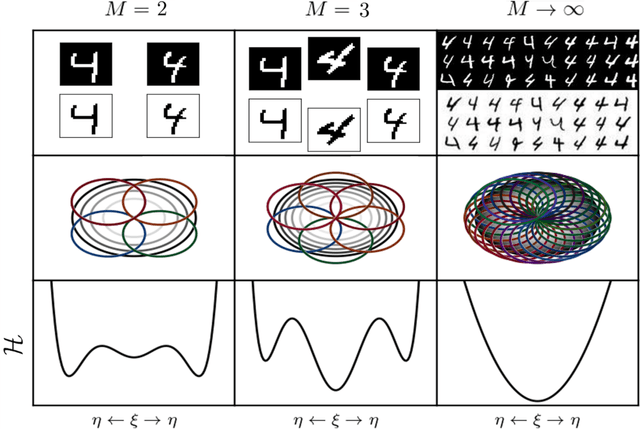
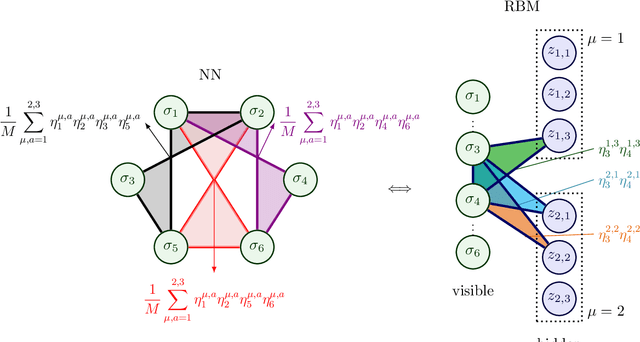
We consider dense, associative neural-networks trained with no supervision and we investigate their computational capabilities analytically, via a statistical-mechanics approach, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as the quality and quantity of the training dataset and the network storage, valid in the limit of large network size and structureless datasets. Moreover, we establish a bridge between macroscopic observables standardly used in statistical mechanics and loss functions typically used in the machine learning. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate neural networks in general.
Benchmarking and Survey of Explanation Methods for Black Box Models
Feb 25, 2021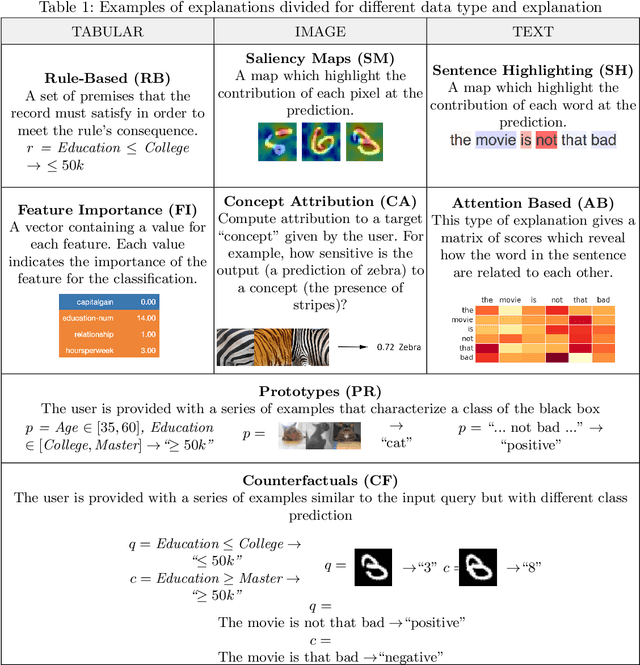

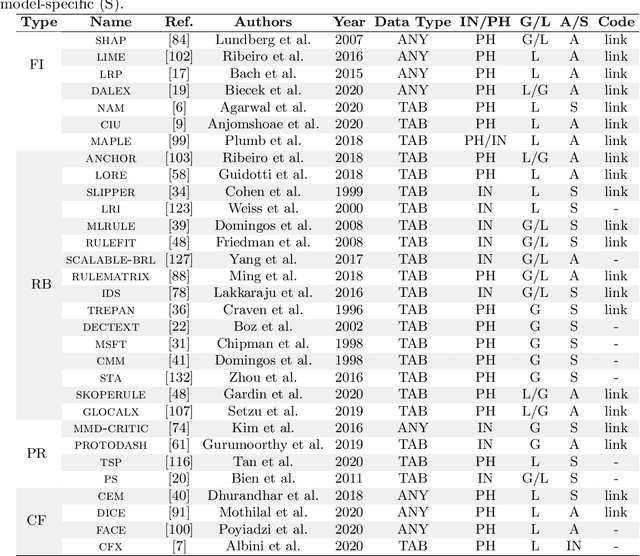
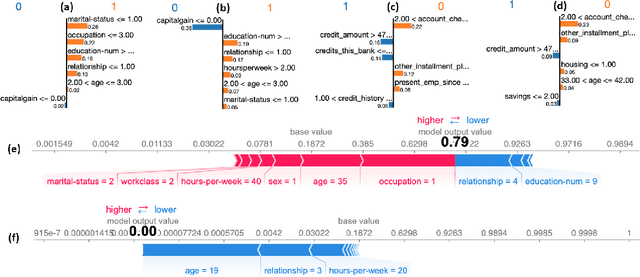
The widespread adoption of black-box models in Artificial Intelligence has enhanced the need for explanation methods to reveal how these obscure models reach specific decisions. Retrieving explanations is fundamental to unveil possible biases and to resolve practical or ethical issues. Nowadays, the literature is full of methods with different explanations. We provide a categorization of explanation methods based on the type of explanation returned. We present the most recent and widely used explainers, and we show a visual comparison among explanations and a quantitative benchmarking.