 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisagreeing Rationales: Rethinking Classification and Explainability Evaluation in Hate Speech Detection
May 29, 2026Human disagreement is ubiquitous and well-known in labeling. However, variation in explanations, captured through token-level human rationales, remains far less explored. At the same time, it is unclear how to best evaluate human labels and rationales -- or even how to best aggregate rationales beyond majority vote -- in light of this variation. Yet, rationales may provide additional insights into the richness of human reasoning, that may differ in style, values and interpretations -- especially in subjective NLP tasks like hate speech detection. In this work, we unify diverse models, training strategies, loss functions, and existing evaluation metrics under a single protocol by systematically re-implementing them across different label and rationale representation spaces. Classification metrics are organized around two key properties -- predictive and distributional -- while explainability metrics through three complementary dimensions: plausibility, faithfulness, and complexity. In this unified supervision framework, we evaluate model behavior across classification and explainability metrics, as well as metric sensitivity to the choice of label (hard and soft) and rationale representation space (hard, intermediate and soft). Results show that both hard and soft metrics favor softer representations, highlighting their effectiveness in capturing variation and the need to rethink evaluation in subjective NLP.
Bridging the Gap: In-Context Learning for Modeling Human Disagreement
Jun 06, 2025Large Language Models (LLMs) have shown strong performance on NLP classification tasks. However, they typically rely on aggregated labels-often via majority voting-which can obscure the human disagreement inherent in subjective annotations. This study examines whether LLMs can capture multiple perspectives and reflect annotator disagreement in subjective tasks such as hate speech and offensive language detection. We use in-context learning (ICL) in zero-shot and few-shot settings, evaluating four open-source LLMs across three label modeling strategies: aggregated hard labels, and disaggregated hard and soft labels. In few-shot prompting, we assess demonstration selection methods based on textual similarity (BM25, PLM-based), annotation disagreement (entropy), a combined ranking, and example ordering strategies (random vs. curriculum-based). Results show that multi-perspective generation is viable in zero-shot settings, while few-shot setups often fail to capture the full spectrum of human judgments. Prompt design and demonstration selection notably affect performance, though example ordering has limited impact. These findings highlight the challenges of modeling subjectivity with LLMs and the importance of building more perspective-aware, socially intelligent models.
Multi-Perspective Stance Detection
Nov 13, 2024

Subjective NLP tasks usually rely on human annotations provided by multiple annotators, whose judgments may vary due to their diverse backgrounds and life experiences. Traditional methods often aggregate multiple annotations into a single ground truth, disregarding the diversity in perspectives that arises from annotator disagreement. In this preliminary study, we examine the effect of including multiple annotations on model accuracy in classification. Our methodology investigates the performance of perspective-aware classification models in stance detection task and further inspects if annotator disagreement affects the model confidence. The results show that multi-perspective approach yields better classification performance outperforming the baseline which uses the single label. This entails that designing more inclusive perspective-aware AI models is not only an essential first step in implementing responsible and ethical AI, but it can also achieve superior results than using the traditional approaches.
A linguistic analysis of undesirable outcomes in the era of generative AI
Oct 16, 2024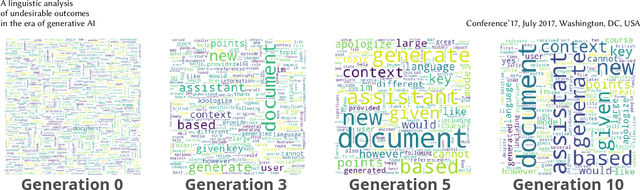
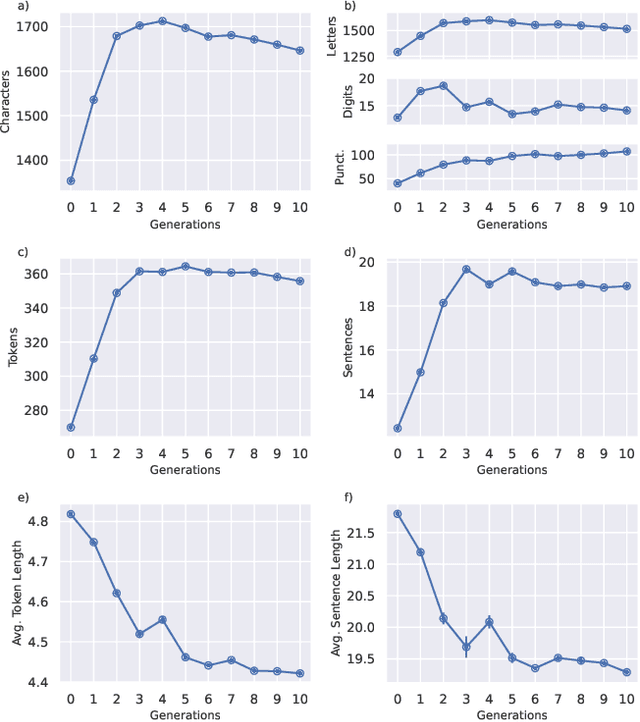
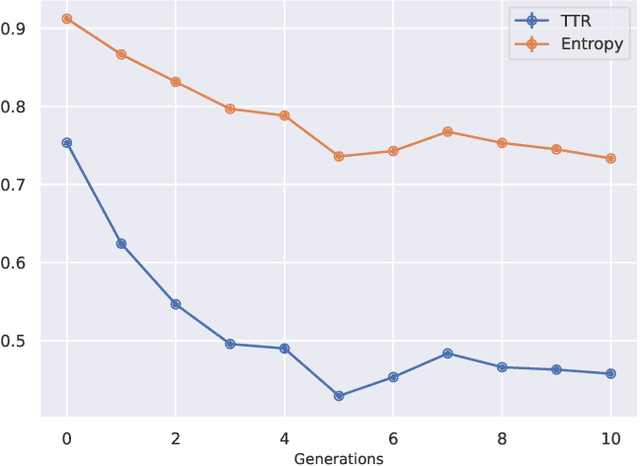
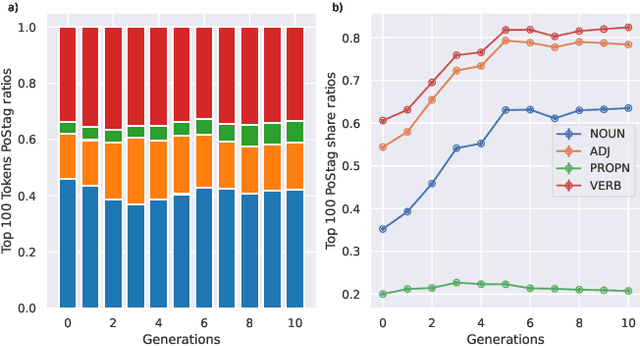
Recent research has focused on the medium and long-term impacts of generative AI, posing scientific and societal challenges mainly due to the detection and reliability of machine-generated information, which is projected to form the major content on the Web soon. Prior studies show that LLMs exhibit a lower performance in generation tasks (model collapse) as they undergo a fine-tuning process across multiple generations on their own generated content (self-consuming loop). In this paper, we present a comprehensive simulation framework built upon the chat version of LLama2, focusing particularly on the linguistic aspects of the generated content, which has not been fully examined in existing studies. Our results show that the model produces less lexical rich content across generations, reducing diversity. The lexical richness has been measured using the linguistic measures of entropy and TTR as well as calculating the POSTags frequency. The generated content has also been examined with an $n$-gram analysis, which takes into account the word order, and semantic networks, which consider the relation between different words. These findings suggest that the model collapse occurs not only by decreasing the content diversity but also by distorting the underlying linguistic patterns of the generated text, which both highlight the critical importance of carefully choosing and curating the initial input text, which can alleviate the model collapse problem. Furthermore, we conduct a qualitative analysis of the fine-tuned models of the pipeline to compare their performances on generic NLP tasks to the original model. We find that autophagy transforms the initial model into a more creative, doubtful and confused one, which might provide inaccurate answers and include conspiracy theories in the model responses, spreading false and biased information on the Web.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024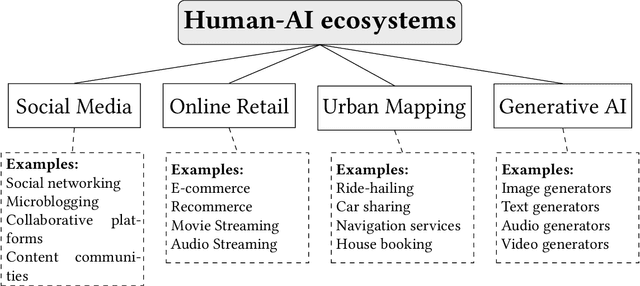
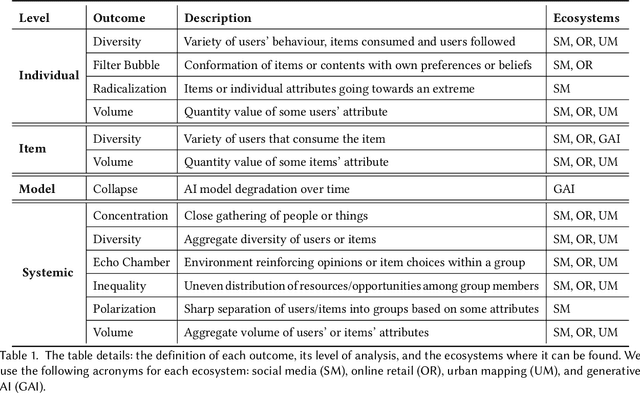
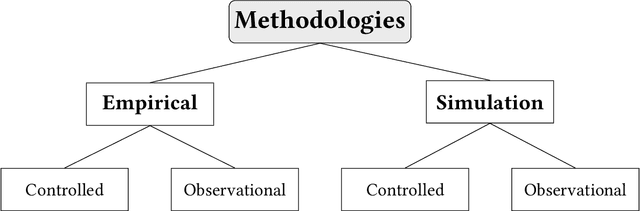
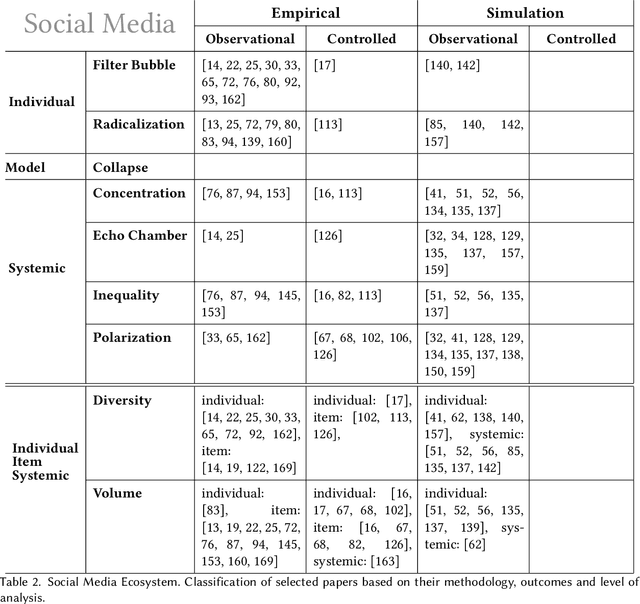
Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
Preliminary Bias Results in Search Engines
Nov 07, 2022



This report aims to report my thesis progress so far. My work attempts to show the differences in the perspectives of two search engines, Bing and Google on several selected controversial topics. In this work, we try to make a distinction on the viewpoints of Bing \& Google by using sentiment as well as the ranking of the document returned from these two search engines on the same queries, these queries are related mainly to controversial topics. You can find the methods we used with experimental results below.
Automated Gender Bias Evaluation in YouTube
Oct 31, 2022


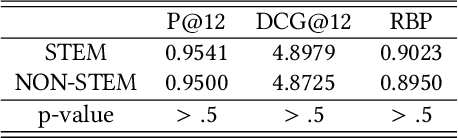
Students are increasingly using online materials to learn new subjects or to supplement their learning process in educational institutions. Issues regarding gender bias have been raised in the context of formal education and some measures have been proposed to mitigate them. In our previous work, we investigate the perceived gender bias in YouTube using manually annotations for detecting the narrators' perceived gender in educational videos. In this work, our goal is to evaluate the perceived gender bias in online education by exploiting an automated annotations. The automated pipeline has already proposed in a recent paper, thus in this paper we only share our empirical results with important findings. Our results show that educational videos are biased towards the male and STEM-related videos are more biased than their NON-STEM counterparts.
Automated Perceived Gender Bias Pipeline in YouTube
Oct 19, 2022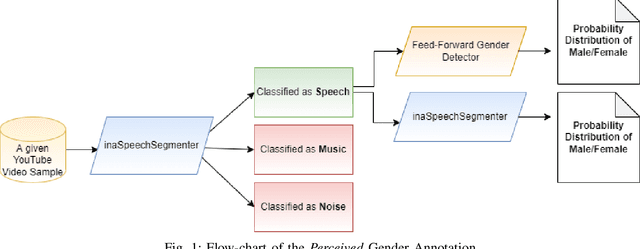

Students are increasingly using online materials to learn new subjects or to supplement their learning process in educational institutions. Issues regarding gender bias have been raised in the context of formal education and some measures have been proposed to mitigate them. However, online educational materials in terms of possible gender bias and stereotypes which may appear in different forms are yet to be investigated in the context of search bias in a widely-used search platform. As a first step towards measuring possible gender bias in online platforms, we have investigated YouTube educational videos in terms of the perceived gender of their narrators. We adopted bias measures for ranked search results to evaluate educational videos returned by YouTube in response to queries related to STEM (Science, Technology, Engineering, and Mathematics) and NON-STEM fields of education. For this, we propose automated pipeline to annotate narrators' perceived gender in YouTube videos for analysing perceived gender bias in online education.
Automated Search Bias Models & YouTube Gender Bias Analysis
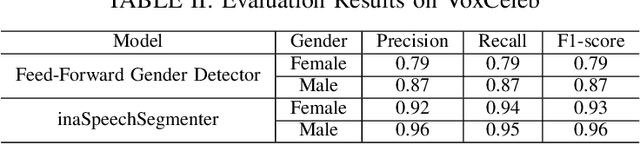
Oct 13, 2022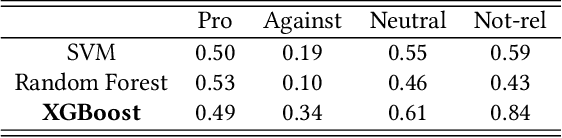
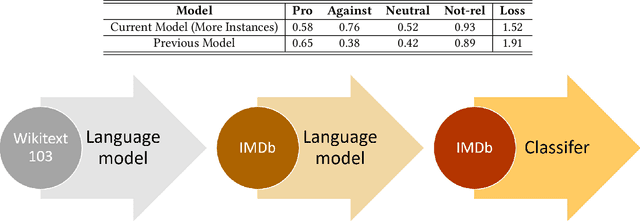
This work first presents our attempts to establish an automated model using state-of-the-art approaches for analysing bias in search results of Bing and Google. Secondly, in this paper we also aim to analyse YouTube video search results in terms of perceived gender bias, i.e. narrator's gender from the viewer's perspective. Experimental results indicate that the current class-wise F1-scores of our best model are not sufficient to establish an automated model for bias analysis. Thus, to evaluate YouTube video search results in terms of perceived gender bias, we use manual annotations.
Quantifying Political Bias in News Articles
Oct 07, 2022


Search bias analysis is getting more attention in recent years since search results could affect In this work, we aim to establish an automated model for evaluating ideological bias in online news articles. The dataset is composed of news articles in search results as well as the newspaper articles. The current automated model results show that model capability is not sufficient to be exploited for annotating the documents automatically, thereby computing bias in search results.