 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKidsArtBench: Multi-Dimensional Children's Art Evaluation with Attribute-Aware MLLMs
Dec 14, 2025Multimodal Large Language Models (MLLMs) show remarkable progress across many visual-language tasks; however, their capacity to evaluate artistic expression remains limited. Aesthetic concepts are inherently abstract and open-ended, and multimodal artwork annotations are scarce. We introduce KidsArtBench, a new benchmark of over 1k children's artworks (ages 5-15) annotated by 12 expert educators across 9 rubric-aligned dimensions, together with expert comments for feedback. Unlike prior aesthetic datasets that provide single scalar scores on adult imagery, KidsArtBench targets children's artwork and pairs multi-dimensional annotations with comment supervision to enable both ordinal assessment and formative feedback. Building on this resource, we propose an attribute-specific multi-LoRA approach, where each attribute corresponds to a distinct evaluation dimension (e.g., Realism, Imagination) in the scoring rubric, with Regression-Aware Fine-Tuning (RAFT) to align predictions with ordinal scales. On Qwen2.5-VL-7B, our method increases correlation from 0.468 to 0.653, with the largest gains on perceptual dimensions and narrowed gaps on higher-order attributes. These results show that educator-aligned supervision and attribute-aware training yield pedagogically meaningful evaluations and establish a rigorous testbed for sustained progress in educational AI. We release data and code with ethics documentation.
Position: On the Methodological Pitfalls of Evaluating Base LLMs for Reasoning
Nov 13, 2025Existing work investigates the reasoning capabilities of large language models (LLMs) to uncover their limitations, human-like biases and underlying processes. Such studies include evaluations of base LLMs (pre-trained on unlabeled corpora only) for this purpose. Our position paper argues that evaluating base LLMs' reasoning capabilities raises inherent methodological concerns that are overlooked in such existing studies. We highlight the fundamental mismatch between base LLMs' pretraining objective and normative qualities, such as correctness, by which reasoning is assessed. In particular, we show how base LLMs generate logically valid or invalid conclusions as coincidental byproducts of conforming to purely linguistic patterns of statistical plausibility. This fundamental mismatch challenges the assumptions that (a) base LLMs' outputs can be assessed as their bona fide attempts at correct answers or conclusions; and (b) conclusions about base LLMs' reasoning can generalize to post-trained LLMs optimized for successful instruction-following. We call for a critical re-examination of existing work that relies implicitly on these assumptions, and for future work to account for these methodological pitfalls.
Quantifying Edits Decay in Fine-tuned LLMs
Nov 12, 2025Knowledge editing has emerged as a lightweight alternative to retraining for correcting or injecting specific facts in large language models (LLMs). Meanwhile, fine-tuning remains the default operation for adapting LLMs to new domains and tasks. Despite their widespread adoption, these two post-training interventions have been studied in isolation, leaving open a crucial question: if we fine-tune an edited model, do the edits survive? This question is motivated by two practical scenarios: removing covert or malicious edits, and preserving beneficial edits. If fine-tuning impairs edits as shown in Figure 1, current KE methods become less useful, as every fine-tuned model would require re-editing, which significantly increases the cost; if edits persist, fine-tuned models risk propagating hidden malicious edits, raising serious safety concerns. To this end, we systematically quantify edits decay after fine-tuning, investigating how fine-tuning affects knowledge editing. We evaluate two state-of-the-art editing methods (MEMIT, AlphaEdit) and three fine-tuning approaches (full-parameter, LoRA, DoRA) across five LLMs and three datasets, yielding 232 experimental configurations. Our results show that edits decay after fine-tuning, with survival varying across configurations, e.g., AlphaEdit edits decay more than MEMIT edits. Further, we propose selective-layer fine-tuning and find that fine-tuning edited layers only can effectively remove edits, though at a slight cost to downstream performance. Surprisingly, fine-tuning non-edited layers impairs more edits than full fine-tuning. Overall, our study establishes empirical baselines and actionable strategies for integrating knowledge editing with fine-tuning, and underscores that evaluating model editing requires considering the full LLM application pipeline.
Analysing Chain of Thought Dynamics: Active Guidance or Unfaithful Post-hoc Rationalisation?
Aug 27, 2025Recent work has demonstrated that Chain-of-Thought (CoT) often yields limited gains for soft-reasoning problems such as analytical and commonsense reasoning. CoT can also be unfaithful to a model's actual reasoning. We investigate the dynamics and faithfulness of CoT in soft-reasoning tasks across instruction-tuned, reasoning and reasoning-distilled models. Our findings reveal differences in how these models rely on CoT, and show that CoT influence and faithfulness are not always aligned.
It's All About In-Context Learning! Teaching Extremely Low-Resource Languages to LLMs
Aug 26, 2025



Extremely low-resource languages, especially those written in rare scripts, as shown in Figure 1, remain largely unsupported by large language models (LLMs). This is due in part to compounding factors such as the lack of training data. This paper delivers the first comprehensive analysis of whether LLMs can acquire such languages purely via in-context learning (ICL), with or without auxiliary alignment signals, and how these methods compare to parameter-efficient fine-tuning (PEFT). We systematically evaluate 20 under-represented languages across three state-of-the-art multilingual LLMs. Our findings highlight the limitation of PEFT when both language and its script are extremely under-represented by the LLM. In contrast, zero-shot ICL with language alignment is impressively effective on extremely low-resource languages, while few-shot ICL or PEFT is more beneficial for languages relatively better represented by LLMs. For LLM practitioners working on extremely low-resource languages, we summarise guidelines grounded by our results on adapting LLMs to low-resource languages, e.g., avoiding fine-tuning a multilingual model on languages of unseen scripts.
Bridging the Gap: In-Context Learning for Modeling Human Disagreement
Jun 06, 2025Large Language Models (LLMs) have shown strong performance on NLP classification tasks. However, they typically rely on aggregated labels-often via majority voting-which can obscure the human disagreement inherent in subjective annotations. This study examines whether LLMs can capture multiple perspectives and reflect annotator disagreement in subjective tasks such as hate speech and offensive language detection. We use in-context learning (ICL) in zero-shot and few-shot settings, evaluating four open-source LLMs across three label modeling strategies: aggregated hard labels, and disaggregated hard and soft labels. In few-shot prompting, we assess demonstration selection methods based on textual similarity (BM25, PLM-based), annotation disagreement (entropy), a combined ranking, and example ordering strategies (random vs. curriculum-based). Results show that multi-perspective generation is viable in zero-shot settings, while few-shot setups often fail to capture the full spectrum of human judgments. Prompt design and demonstration selection notably affect performance, though example ordering has limited impact. These findings highlight the challenges of modeling subjectivity with LLMs and the importance of building more perspective-aware, socially intelligent models.
Tracing and Reversing Rank-One Model Edits
May 27, 2025Knowledge editing methods (KEs) are a cost-effective way to update the factual content of large language models (LLMs), but they pose a dual-use risk. While KEs are beneficial for updating outdated or incorrect information, they can be exploited maliciously to implant misinformation or bias. In order to defend against these types of malicious manipulation, we need robust techniques that can reliably detect, interpret, and mitigate adversarial edits. This work investigates the traceability and reversibility of knowledge edits, focusing on the widely used Rank-One Model Editing (ROME) method. We first show that ROME introduces distinctive distributional patterns in the edited weight matrices, which can serve as effective signals for locating the edited weights. Second, we show that these altered weights can reliably be used to predict the edited factual relation, enabling partial reconstruction of the modified fact. Building on this, we propose a method to infer the edited object entity directly from the modified weights, without access to the editing prompt, achieving over 95% accuracy. Finally, we demonstrate that ROME edits can be reversed, recovering the model's original outputs with $\geq$ 80% accuracy. Our findings highlight the feasibility of detecting, tracing, and reversing edits based on the edited weights, offering a robust framework for safeguarding LLMs against adversarial manipulations.
SCRum-9: Multilingual Stance Classification over Rumours on Social Media
May 25, 2025We introduce SCRum-9, a multilingual dataset for Rumour Stance Classification, containing 7,516 tweet-reply pairs from X. SCRum-9 goes beyond existing stance classification datasets by covering more languages (9), linking examples to more fact-checked claims (2.1k), and including complex annotations from multiple annotators to account for intra- and inter-annotator variability. Annotations were made by at least three native speakers per language, totalling around 405 hours of annotation and 8,150 dollars in compensation. Experiments on SCRum-9 show that it is a challenging benchmark for both state-of-the-art LLMs (e.g. Deepseek) as well as fine-tuned pre-trained models, motivating future work in this area.
Mitigating Content Effects on Reasoning in Language Models through Fine-Grained Activation Steering
May 18, 2025Large language models (LLMs) frequently demonstrate reasoning limitations, often conflating content plausibility (i.e., material inference) with logical validity (i.e., formal inference). This can result in biased inferences, where plausible arguments are incorrectly deemed logically valid or vice versa. Mitigating this limitation is critical, as it undermines the trustworthiness and generalizability of LLMs in applications that demand rigorous logical consistency. This paper investigates the problem of mitigating content biases on formal reasoning through activation steering. Specifically, we curate a controlled syllogistic reasoning dataset to disentangle formal validity from content plausibility. After localising the layers responsible for formal and material inference, we investigate contrastive activation steering methods for test-time interventions. An extensive empirical analysis on different LLMs reveals that contrastive steering consistently supports linear control over content biases. However, we observe that a static approach is insufficient for improving all the tested models. We then leverage the possibility to control content effects by dynamically determining the value of the steering parameters via fine-grained conditional methods. We found that conditional steering is effective on unresponsive models, achieving up to 15% absolute improvement in formal reasoning accuracy with a newly introduced kNN-based method (K-CAST). Finally, additional experiments reveal that steering for content effects is robust to prompt variations, incurs minimal side effects on language modeling capabilities, and can partially generalize to out-of-distribution reasoning tasks. Practically, this paper demonstrates that activation-level interventions can offer a scalable strategy for enhancing the robustness of LLMs, contributing towards more systematic and unbiased formal reasoning.
Position: Editing Large Language Models Poses Serious Safety Risks
Feb 05, 2025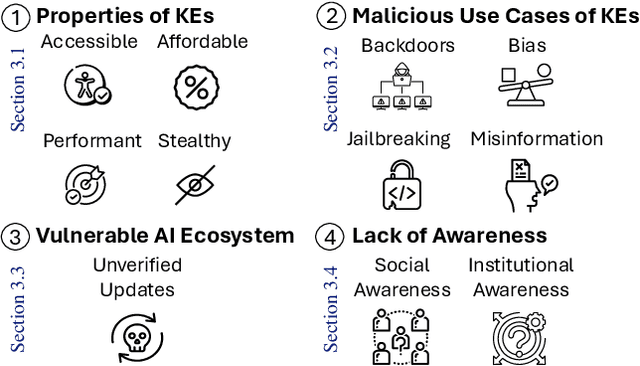



Large Language Models (LLMs) contain large amounts of facts about the world. These facts can become outdated over time, which has led to the development of knowledge editing methods (KEs) that can change specific facts in LLMs with limited side effects. This position paper argues that editing LLMs poses serious safety risks that have been largely overlooked. First, we note the fact that KEs are widely available, computationally inexpensive, highly performant, and stealthy makes them an attractive tool for malicious actors. Second, we discuss malicious use cases of KEs, showing how KEs can be easily adapted for a variety of malicious purposes. Third, we highlight vulnerabilities in the AI ecosystem that allow unrestricted uploading and downloading of updated models without verification. Fourth, we argue that a lack of social and institutional awareness exacerbates this risk, and discuss the implications for different stakeholders. We call on the community to (i) research tamper-resistant models and countermeasures against malicious model editing, and (ii) actively engage in securing the AI ecosystem.