 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
Dec 03, 2024



Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.
Faithful Knowledge Graph Explanations for Commonsense Reasoning
Oct 07, 2023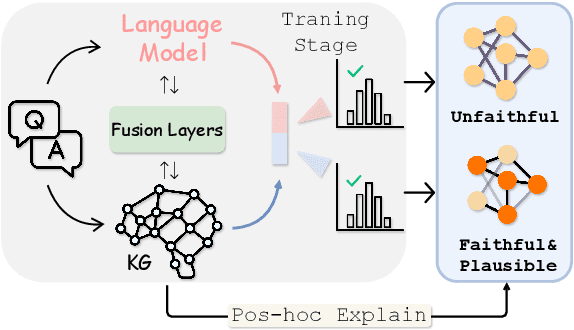


While fusing language models (LMs) and knowledge graphs (KGs) has become common in commonsense question answering research, enabling faithful chain-of-thought explanations in these models remains an open problem. One major weakness of current KG-based explanation techniques is that they overlook the faithfulness of generated explanations during evaluation. To address this gap, we make two main contributions: (1) We propose and validate two quantitative metrics - graph consistency and graph fidelity - to measure the faithfulness of KG-based explanations. (2) We introduce Consistent GNN (CGNN), a novel training method that adds a consistency regularization term to improve explanation faithfulness. Our analysis shows that predictions from KG often diverge from original model predictions. The proposed CGNN approach boosts consistency and fidelity, demonstrating its potential for producing more faithful explanations. Our work emphasises the importance of explicitly evaluating suggest a path forward for developing architectures for faithful graph-based explanations.