 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Human Perspectives with Socio-Demographic Representations
Apr 20, 2026Humans often hold different perspectives on the same issues. In many NLP tasks, annotation disagreement can reflect valid subjective perspectives. Modeling annotator perspectives and understanding their relationship with other human factors, such as socio-demographic attributes, have received increasing attention. Prior work typically focuses on single demographic factors or limited combinations. However, in real-world settings, annotator perspectives are shaped by complex social contexts, and finer-grained socio-demographic attributes can better explain human perspectives. In this work, we propose Socio-Contrastive Learning, a method that jointly models annotator perspectives while learning socio-demographic representations. Our method provides an effective approach for the fusion of socio-demographic features and textual representations to predict annotator perspectives, outperforming standard concatenation-based methods. The learned representations further enable analysis and visualization of how demographic factors relate to variation in annotator perspectives. Our code is available at GitHub: https://github.com/Leixin-Zhang/Socio_Contrastive_Learning
ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
Dec 03, 2024



Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.
Tübingen-CL at SemEval-2024 Task 1:Ensemble Learning for Semantic Relatedness Estimation
Oct 14, 2024

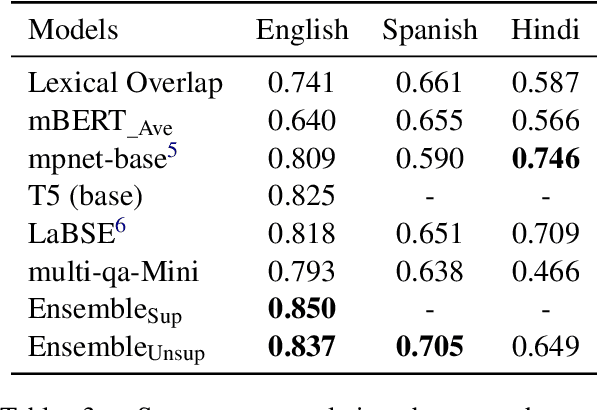
The paper introduces our system for SemEval-2024 Task 1, which aims to predict the relatedness of sentence pairs. Operating under the hypothesis that semantic relatedness is a broader concept that extends beyond mere similarity of sentences, our approach seeks to identify useful features for relatedness estimation. We employ an ensemble approach integrating various systems, including statistical textual features and outputs of deep learning models to predict relatedness scores. The findings suggest that semantic relatedness can be inferred from various sources and ensemble models outperform many individual systems in estimating semantic relatedness.
* 5 pages