 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiMat: Multimodal Program Synthesis for Procedural Materials using Large Multimodal Models
Sep 26, 2025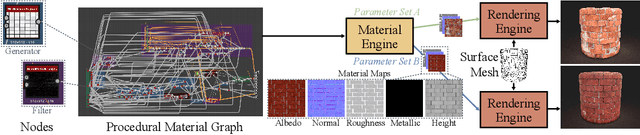

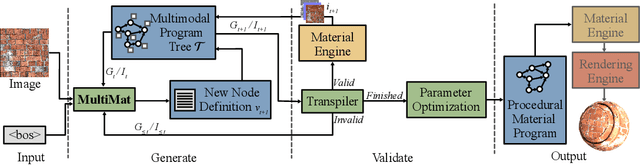

Material node graphs are programs that generate the 2D channels of procedural materials, including geometry such as roughness and displacement maps, and reflectance such as albedo and conductivity maps. They are essential in computer graphics for representing the appearance of virtual 3D objects parametrically and at arbitrary resolution. In particular, their directed acyclic graph structures and intermediate states provide an intuitive understanding and workflow for interactive appearance modeling. Creating such graphs is a challenging task and typically requires professional training. While recent neural program synthesis approaches attempt to simplify this process, they solely represent graphs as textual programs, failing to capture the inherently visual-spatial nature of node graphs that makes them accessible to humans. To address this gap, we present MultiMat, a multimodal program synthesis framework that leverages large multimodal models to process both visual and textual graph representations for improved generation of procedural material graphs. We train our models on a new dataset of production-quality procedural materials and combine them with a constrained tree search inference algorithm that ensures syntactic validity while efficiently navigating the program space. Our experimental results show that our multimodal program synthesis method is more efficient in both unconditional and conditional graph synthesis with higher visual quality and fidelity than text-only baselines, establishing new state-of-the-art performance.
TikZero: Zero-Shot Text-Guided Graphics Program Synthesis
Mar 14, 2025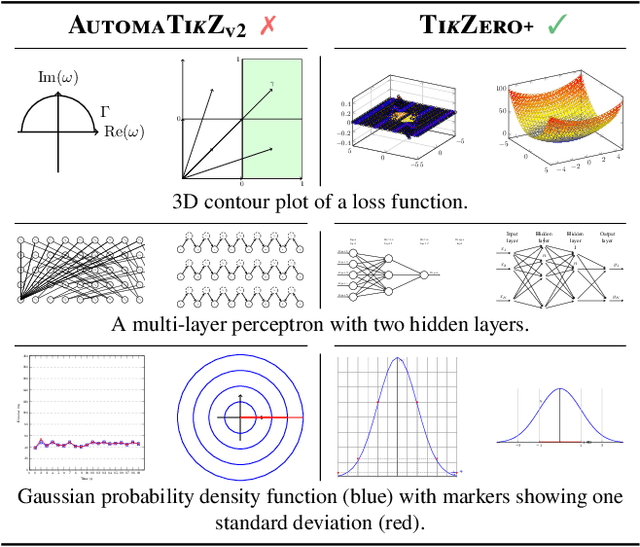
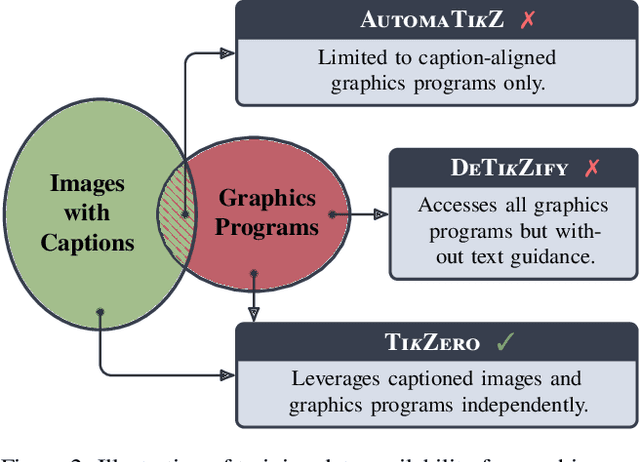

With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like TikZ, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting TikZero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, TikZero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models are publicly available.
ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
Dec 03, 2024



Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ
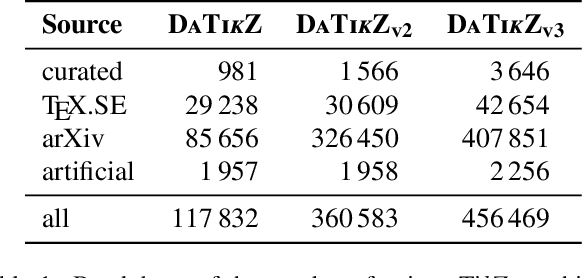
May 28, 2024Creating high-quality scientific figures can be time-consuming and challenging, even though sketching ideas on paper is relatively easy. Furthermore, recreating existing figures that are not stored in formats preserving semantic information is equally complex. To tackle this problem, we introduce DeTikZify, a novel multimodal language model that automatically synthesizes scientific figures as semantics-preserving TikZ graphics programs based on sketches and existing figures. To achieve this, we create three new datasets: DaTikZv2, the largest TikZ dataset to date, containing over 360k human-created TikZ graphics; SketchFig, a dataset that pairs hand-drawn sketches with their corresponding scientific figures; and SciCap++, a collection of diverse scientific figures and associated metadata. We train DeTikZify on SciCap++ and DaTikZv2, along with synthetically generated sketches learned from SketchFig. We also introduce an MCTS-based inference algorithm that enables DeTikZify to iteratively refine its outputs without the need for additional training. Through both automatic and human evaluation, we demonstrate that DeTikZify outperforms commercial Claude 3 and GPT-4V in synthesizing TikZ programs, with the MCTS algorithm effectively boosting its performance. We make our code, models, and datasets publicly available.
NLLG Quarterly arXiv Report 09/23: What are the most influential current AI Papers?
Dec 09, 2023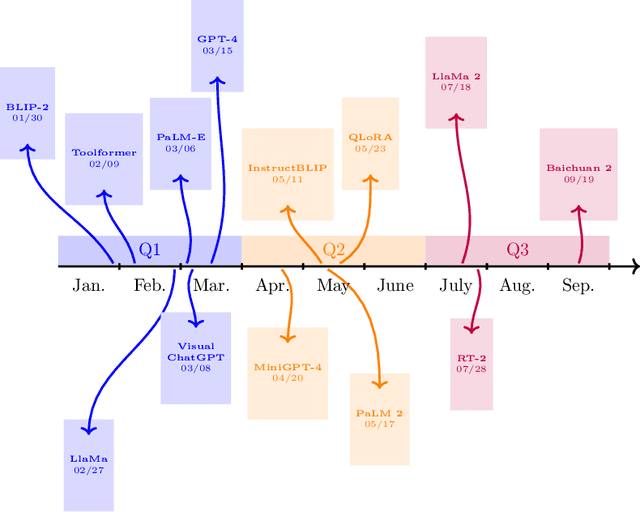

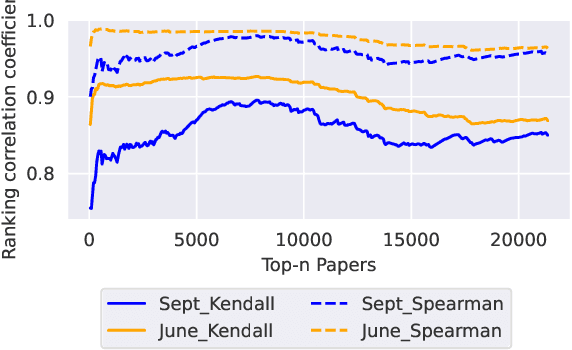
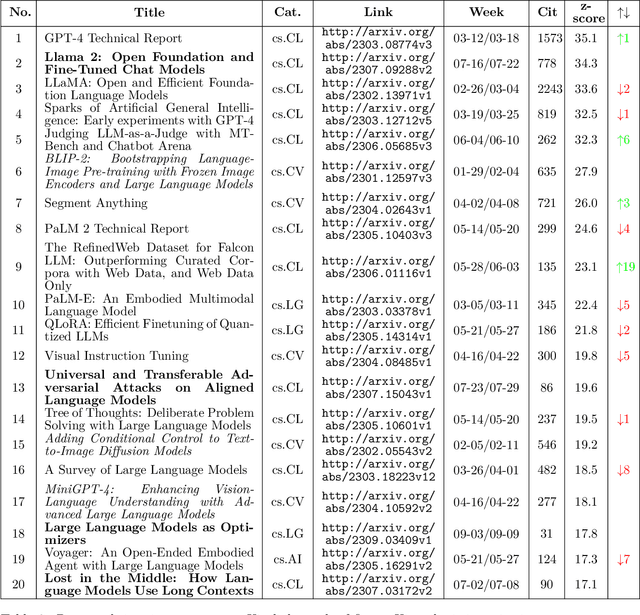
Artificial Intelligence (AI) has witnessed rapid growth, especially in the subfields Natural Language Processing (NLP), Machine Learning (ML) and Computer Vision (CV). Keeping pace with this rapid progress poses a considerable challenge for researchers and professionals in the field. In this arXiv report, the second of its kind, which covers the period from January to September 2023, we aim to provide insights and analysis that help navigate these dynamic areas of AI. We accomplish this by 1) identifying the top-40 most cited papers from arXiv in the given period, comparing the current top-40 papers to the previous report, which covered the period January to June; 2) analyzing dataset characteristics and keyword popularity; 3) examining the global sectoral distribution of institutions to reveal differences in engagement across geographical areas. Our findings highlight the continued dominance of NLP: while only 16% of all submitted papers have NLP as primary category (more than 25% have CV and ML as primary category), 50% of the most cited papers have NLP as primary category, 90% of which target LLMs. Additionally, we show that i) the US dominates among both top-40 and top-9k papers, followed by China; ii) Europe clearly lags behind and is hardly represented in the top-40 most cited papers; iii) US industry is largely overrepresented in the top-40 most influential papers.
AutomaTikZ: Text-Guided Synthesis of Scientific Vector Graphics with TikZ
Sep 30, 2023
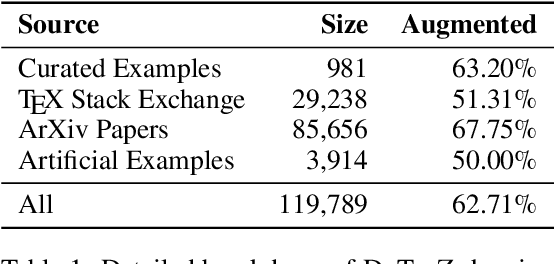
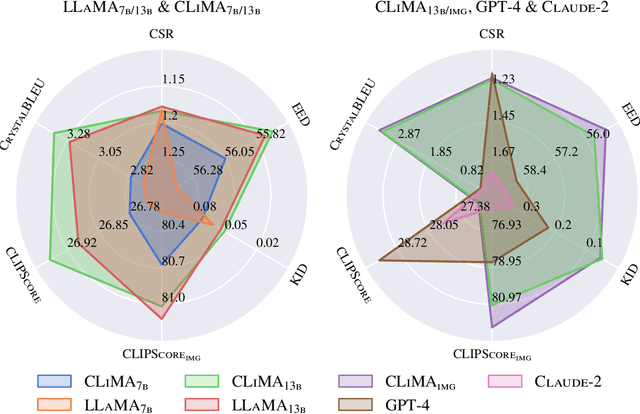
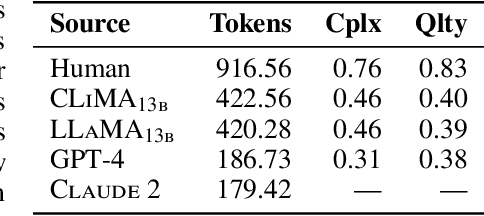
Generating bitmap graphics from text has gained considerable attention, yet for scientific figures, vector graphics are often preferred. Given that vector graphics are typically encoded using low-level graphics primitives, generating them directly is difficult. To address this, we propose the use of TikZ, a well-known abstract graphics language that can be compiled to vector graphics, as an intermediate representation of scientific figures. TikZ offers human-oriented, high-level commands, thereby facilitating conditional language modeling with any large language model. To this end, we introduce DaTikZ the first large-scale TikZ dataset, consisting of 120k TikZ drawings aligned with captions. We fine-tune LLaMA on DaTikZ, as well as our new model CLiMA, which augments LLaMA with multimodal CLIP embeddings. In both human and automatic evaluation, CLiMA and LLaMA outperform commercial GPT-4 and Claude 2 in terms of similarity to human-created figures, with CLiMA additionally improving text-image alignment. Our detailed analysis shows that all models generalize well and are not susceptible to memorization. GPT-4 and Claude 2, however, tend to generate more simplistic figures compared to both humans and our models. We make our framework, AutomaTikZ, along with model weights and datasets, publicly available.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
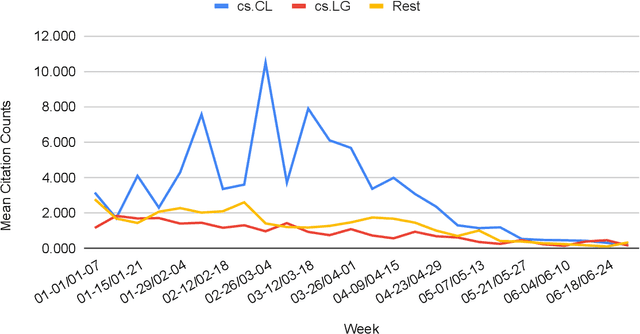
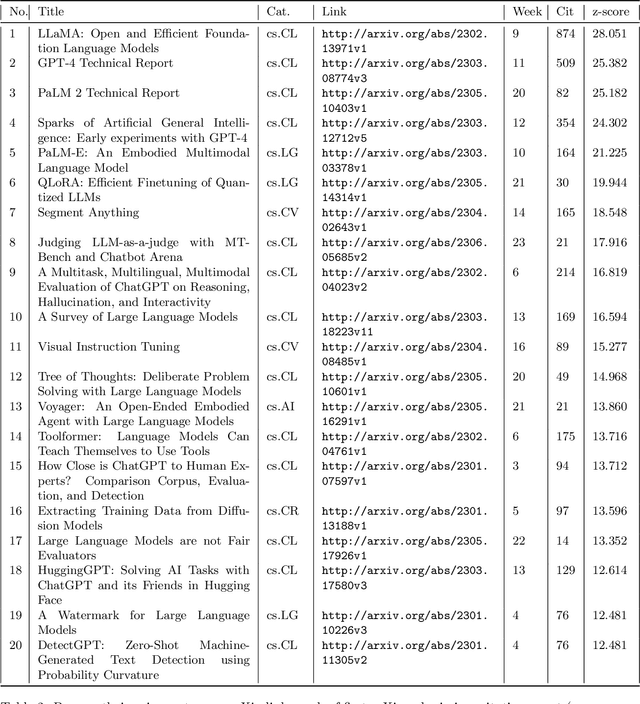
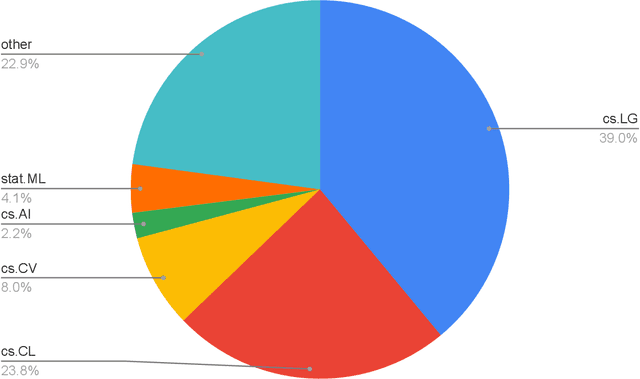
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
Cross-Genre Argument Mining: Can Language Models Automatically Fill in Missing Discourse Markers?
Jun 07, 2023



Available corpora for Argument Mining differ along several axes, and one of the key differences is the presence (or absence) of discourse markers to signal argumentative content. Exploring effective ways to use discourse markers has received wide attention in various discourse parsing tasks, from which it is well-known that discourse markers are strong indicators of discourse relations. To improve the robustness of Argument Mining systems across different genres, we propose to automatically augment a given text with discourse markers such that all relations are explicitly signaled. Our analysis unveils that popular language models taken out-of-the-box fail on this task; however, when fine-tuned on a new heterogeneous dataset that we construct (including synthetic and real examples), they perform considerably better. We demonstrate the impact of our approach on an Argument Mining downstream task, evaluated on different corpora, showing that language models can be trained to automatically fill in discourse markers across different corpora, improving the performance of a downstream model in some, but not all, cases. Our proposed approach can further be employed as an assistive tool for better discourse understanding.
ChatGPT: A Meta-Analysis after 2.5 Months
Feb 20, 2023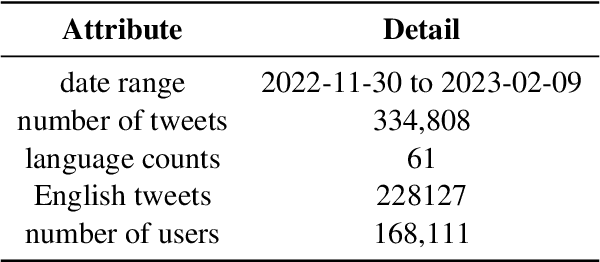
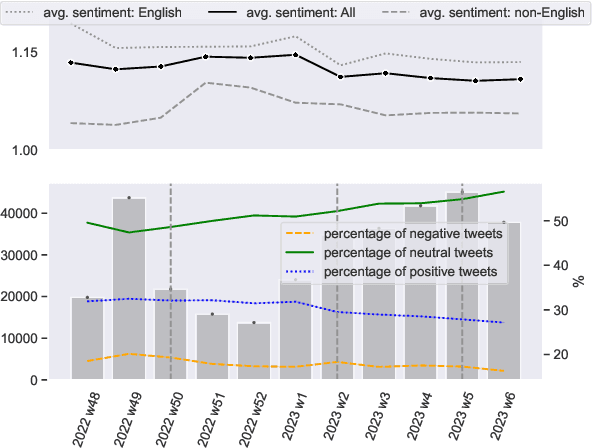
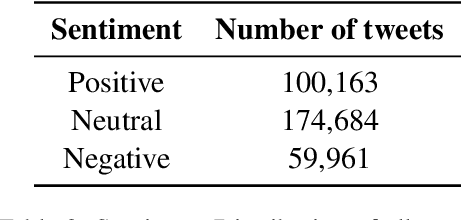
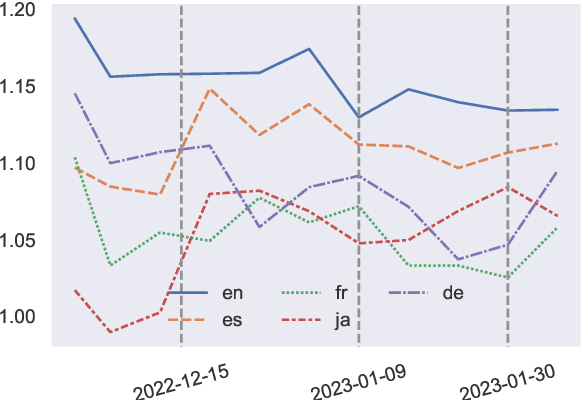
ChatGPT, a chatbot developed by OpenAI, has gained widespread popularity and media attention since its release in November 2022. However, little hard evidence is available regarding its perception in various sources. In this paper, we analyze over 300,000 tweets and more than 150 scientific papers to investigate how ChatGPT is perceived and discussed. Our findings show that ChatGPT is generally viewed as of high quality, with positive sentiment and emotions of joy dominating in social media. Its perception has slightly decreased since its debut, however, with joy decreasing and (negative) surprise on the rise, and it is perceived more negatively in languages other than English. In recent scientific papers, ChatGPT is characterized as a great opportunity across various fields including the medical domain, but also as a threat concerning ethics and receives mixed assessments for education. Our comprehensive meta-analysis of ChatGPT's current perception after 2.5 months since its release can contribute to shaping the public debate and informing its future development. We make our data available.
ByGPT5: End-to-End Style-conditioned Poetry Generation with Token-free Language Models
Dec 20, 2022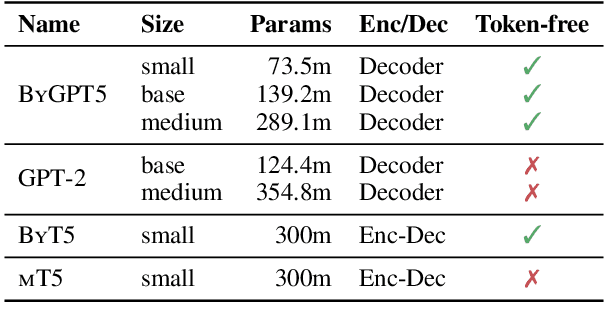
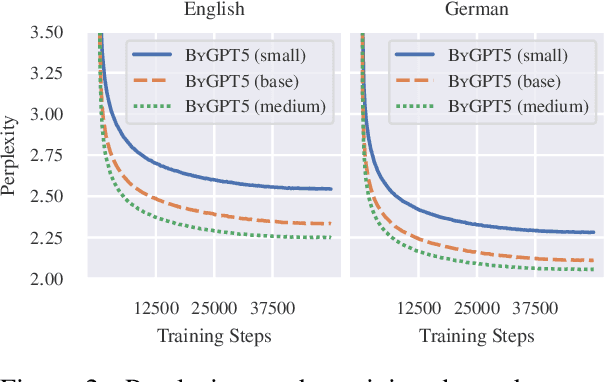
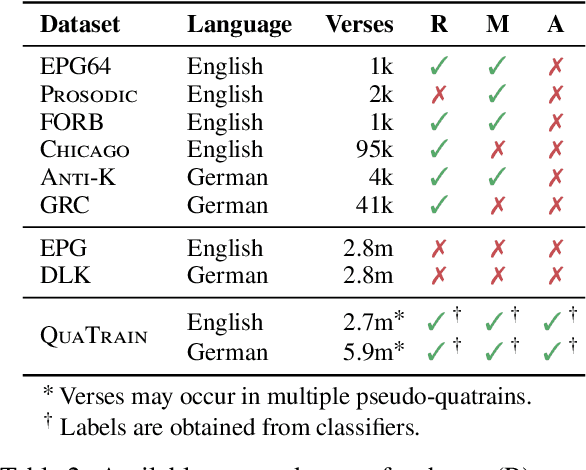
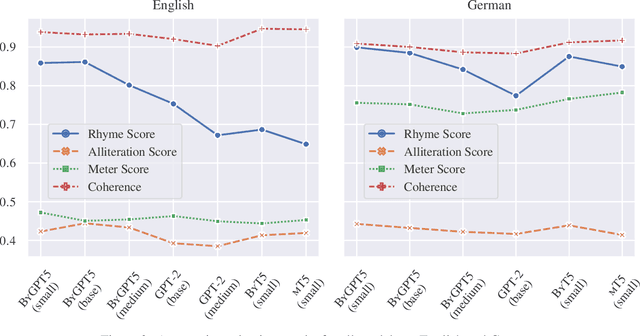
State-of-the-art poetry generation systems are often complex. They either consist of task-specific model pipelines, incorporate prior knowledge in the form of manually created constraints or both. In contrast, end-to-end models would not suffer from the overhead of having to model prior knowledge and could learn the nuances of poetry from data alone, reducing the degree of human supervision required. In this work, we investigate end-to-end poetry generation conditioned on styles such as rhyme, meter, and alliteration. We identify and address lack of training data and mismatching tokenization algorithms as possible limitations of past attempts. In particular, we successfully pre-train and release ByGPT5, a new token-free decoder-only language model, and fine-tune it on a large custom corpus of English and German quatrains annotated with our styles. We show that ByGPT5 outperforms other models such as mT5, ByT5, GPT-2 and ChatGPT, while also being more parameter efficient and performing favorably compared to humans. In addition, we analyze its runtime performance and introspect the model's understanding of style conditions. We make our code, models, and datasets publicly available.