 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLLG Quarterly arXiv Report 09/23: What are the most influential current AI Papers?
Dec 09, 2023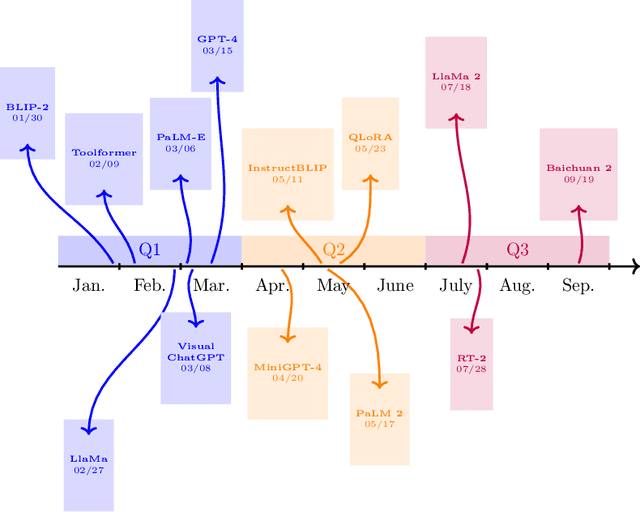

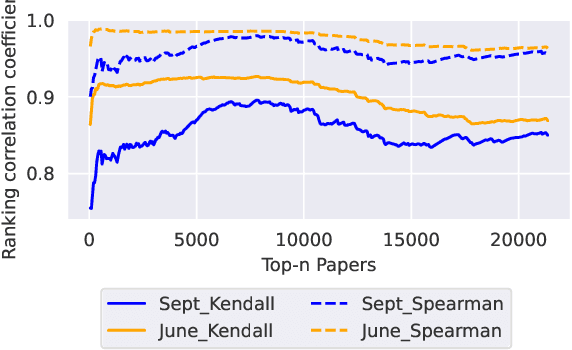
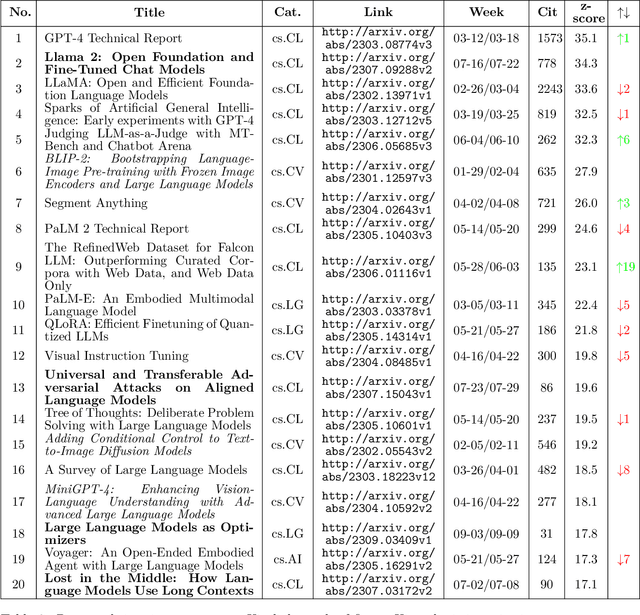
Artificial Intelligence (AI) has witnessed rapid growth, especially in the subfields Natural Language Processing (NLP), Machine Learning (ML) and Computer Vision (CV). Keeping pace with this rapid progress poses a considerable challenge for researchers and professionals in the field. In this arXiv report, the second of its kind, which covers the period from January to September 2023, we aim to provide insights and analysis that help navigate these dynamic areas of AI. We accomplish this by 1) identifying the top-40 most cited papers from arXiv in the given period, comparing the current top-40 papers to the previous report, which covered the period January to June; 2) analyzing dataset characteristics and keyword popularity; 3) examining the global sectoral distribution of institutions to reveal differences in engagement across geographical areas. Our findings highlight the continued dominance of NLP: while only 16% of all submitted papers have NLP as primary category (more than 25% have CV and ML as primary category), 50% of the most cited papers have NLP as primary category, 90% of which target LLMs. Additionally, we show that i) the US dominates among both top-40 and top-9k papers, followed by China; ii) Europe clearly lags behind and is hardly represented in the top-40 most cited papers; iii) US industry is largely overrepresented in the top-40 most influential papers.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
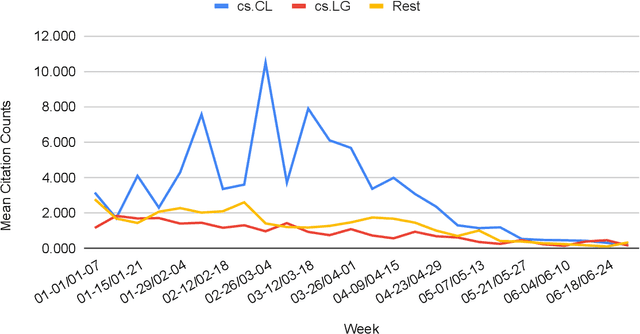
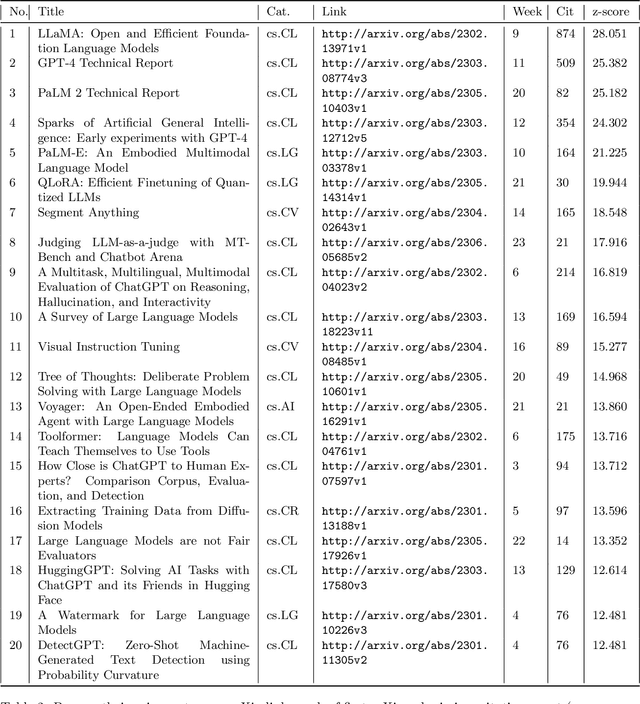
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
ChatGPT: A Meta-Analysis after 2.5 Months
Feb 20, 2023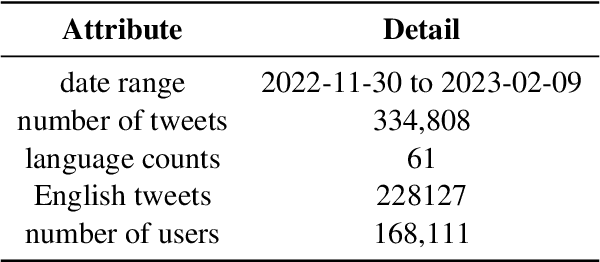
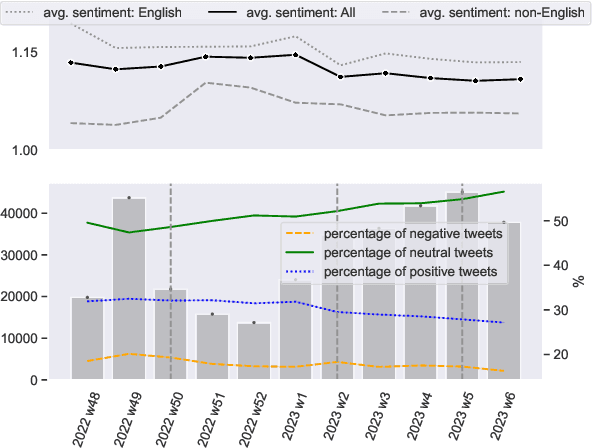
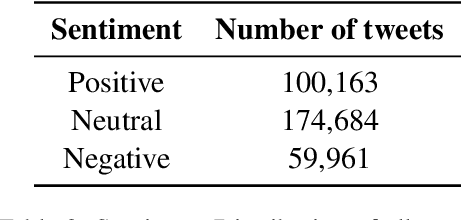
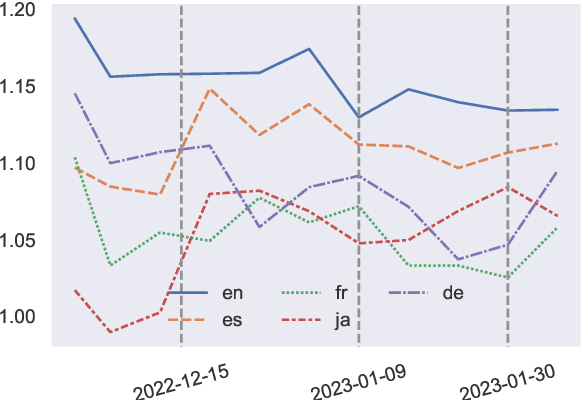
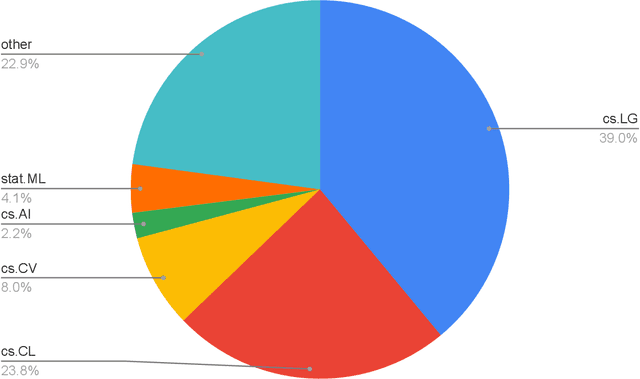
ChatGPT, a chatbot developed by OpenAI, has gained widespread popularity and media attention since its release in November 2022. However, little hard evidence is available regarding its perception in various sources. In this paper, we analyze over 300,000 tweets and more than 150 scientific papers to investigate how ChatGPT is perceived and discussed. Our findings show that ChatGPT is generally viewed as of high quality, with positive sentiment and emotions of joy dominating in social media. Its perception has slightly decreased since its debut, however, with joy decreasing and (negative) surprise on the rise, and it is perceived more negatively in languages other than English. In recent scientific papers, ChatGPT is characterized as a great opportunity across various fields including the medical domain, but also as a threat concerning ethics and receives mixed assessments for education. Our comprehensive meta-analysis of ChatGPT's current perception after 2.5 months since its release can contribute to shaping the public debate and informing its future development. We make our data available.