 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Apr 10, 2025Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
Evaluating Diversity in Automatic Poetry Generation
Jun 21, 2024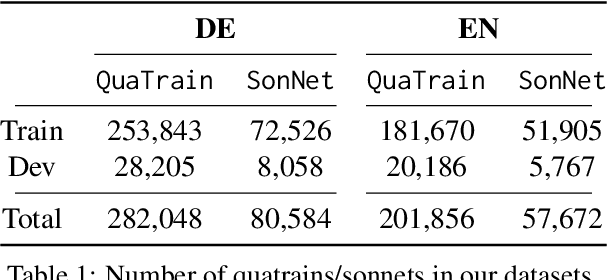
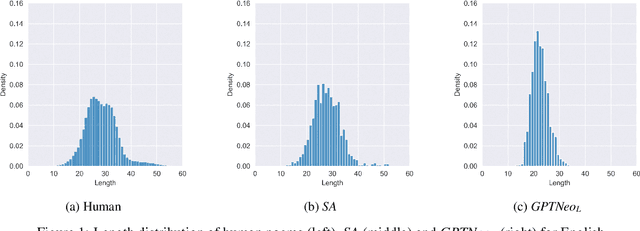
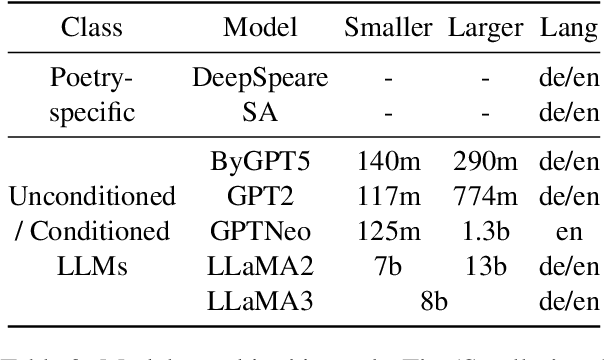
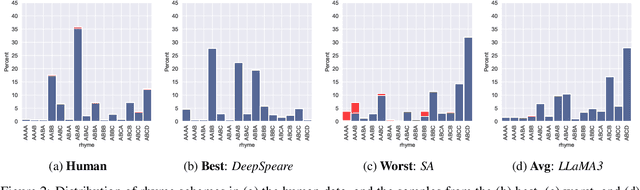
Natural Language Generation (NLG), and more generally generative AI, are among the currently most impactful research fields. Creative NLG, such as automatic poetry generation, is a fascinating niche in this area. While most previous research has focused on forms of the Turing test when evaluating automatic poetry generation - can humans distinguish between automatic and human generated poetry - we evaluate the diversity of automatically generated poetry, by comparing distributions of generated poetry to distributions of human poetry along structural, lexical, semantic and stylistic dimensions, assessing different model types (word vs. character-level, general purpose LLMs vs. poetry-specific models), including the very recent LLaMA3, and types of fine-tuning (conditioned vs. unconditioned). We find that current automatic poetry systems are considerably underdiverse along multiple dimensions - they often do not rhyme sufficiently, are semantically too uniform and even do not match the length distribution of human poetry. Our experiments reveal, however, that style-conditioning and character-level modeling clearly increases diversity across virtually all dimensions we explore. Our identified limitations may serve as the basis for more genuinely diverse future poetry generation models.
Syntactic Language Change in English and German: Metrics, Parsers, and Convergences
Feb 18, 2024



Many studies have shown that human languages tend to optimize for lower complexity and increased communication efficiency. Syntactic dependency distance, which measures the linear distance between dependent words, is often considered a key indicator of language processing difficulty and working memory load. The current paper looks at diachronic trends in syntactic language change in both English and German, using corpora of parliamentary debates from the last c. 160 years. We base our observations on five dependency parsers, including the widely used Stanford CoreNLP as well as 4 newer alternatives. Our analysis of syntactic language change goes beyond linear dependency distance and explores 15 metrics relevant to dependency distance minimization (DDM) and/or based on tree graph properties, such as the tree height and degree variance. Even though we have evidence that recent parsers trained on modern treebanks are not heavily affected by data 'noise' such as spelling changes and OCR errors in our historic data, we find that results of syntactic language change are sensitive to the parsers involved, which is a caution against using a single parser for evaluating syntactic language change as done in previous work. We also show that syntactic language change over the time period investigated is largely similar between English and German across the different metrics explored: only 4% of cases we examine yield opposite conclusions regarding upwards and downtrends of syntactic metrics across German and English. We also show that changes in syntactic measures seem to be more frequent at the tails of sentence length distributions. To our best knowledge, ours is the most comprehensive analysis of syntactic language using modern NLP technology in recent corpora of English and German.
NLLG Quarterly arXiv Report 09/23: What are the most influential current AI Papers?
Dec 09, 2023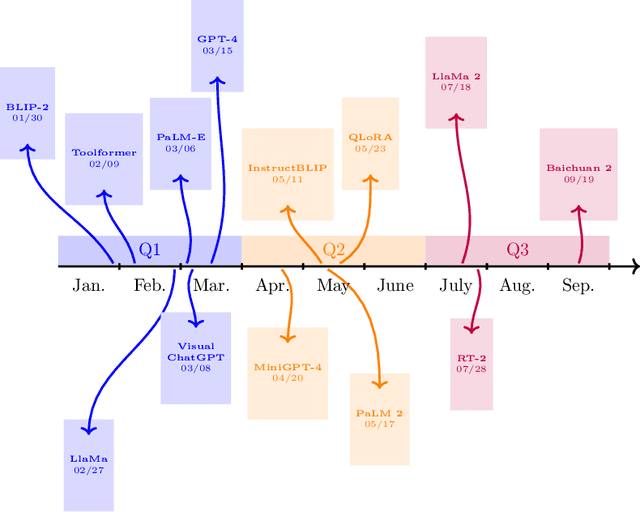

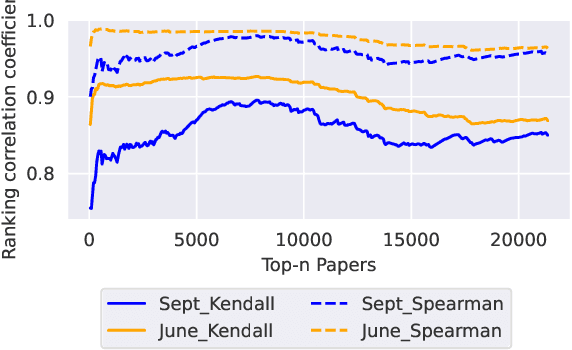
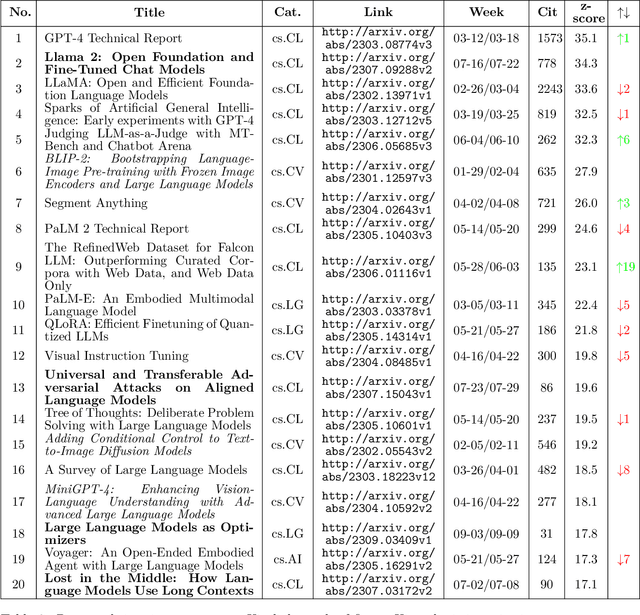
Artificial Intelligence (AI) has witnessed rapid growth, especially in the subfields Natural Language Processing (NLP), Machine Learning (ML) and Computer Vision (CV). Keeping pace with this rapid progress poses a considerable challenge for researchers and professionals in the field. In this arXiv report, the second of its kind, which covers the period from January to September 2023, we aim to provide insights and analysis that help navigate these dynamic areas of AI. We accomplish this by 1) identifying the top-40 most cited papers from arXiv in the given period, comparing the current top-40 papers to the previous report, which covered the period January to June; 2) analyzing dataset characteristics and keyword popularity; 3) examining the global sectoral distribution of institutions to reveal differences in engagement across geographical areas. Our findings highlight the continued dominance of NLP: while only 16% of all submitted papers have NLP as primary category (more than 25% have CV and ML as primary category), 50% of the most cited papers have NLP as primary category, 90% of which target LLMs. Additionally, we show that i) the US dominates among both top-40 and top-9k papers, followed by China; ii) Europe clearly lags behind and is hardly represented in the top-40 most cited papers; iii) US industry is largely overrepresented in the top-40 most influential papers.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
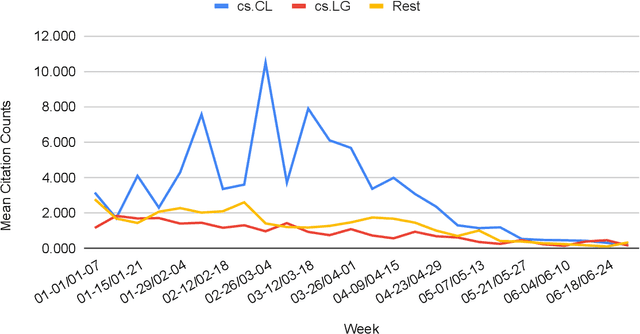
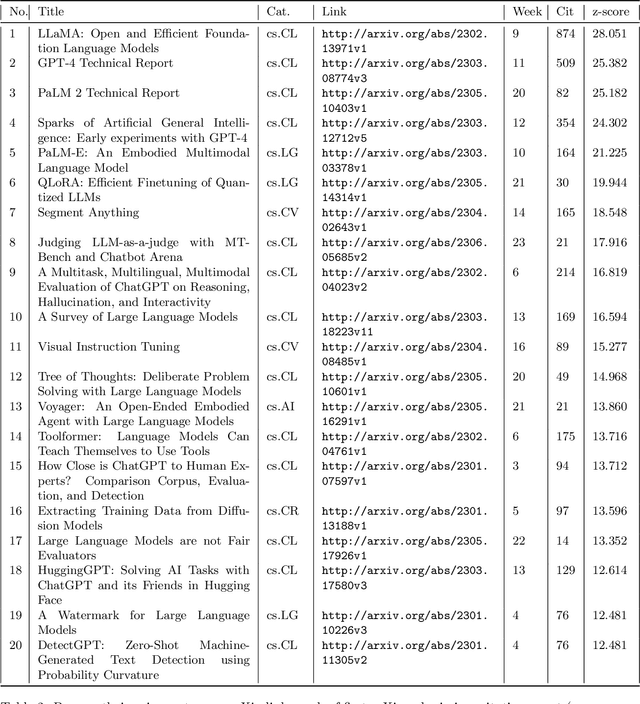
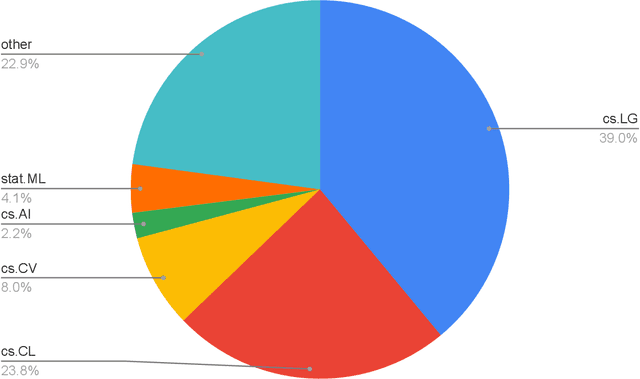
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
ChatGPT: A Meta-Analysis after 2.5 Months
Feb 20, 2023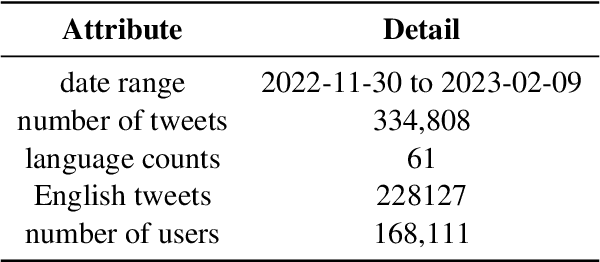
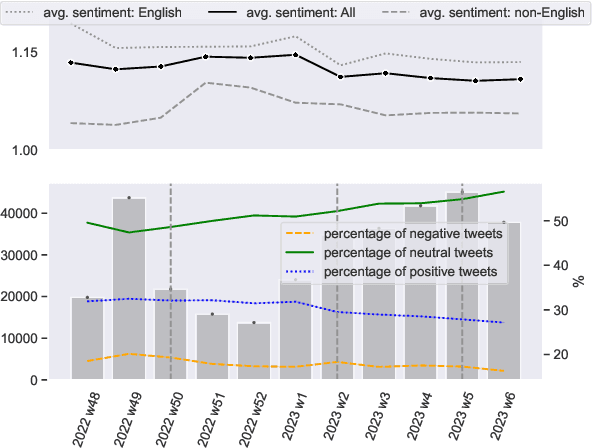
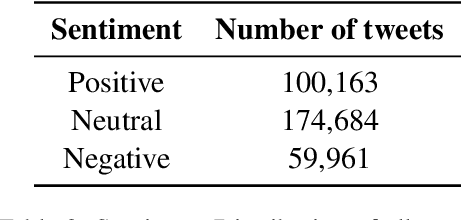
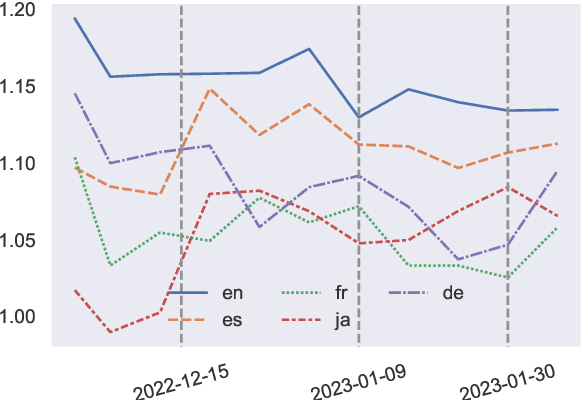
ChatGPT, a chatbot developed by OpenAI, has gained widespread popularity and media attention since its release in November 2022. However, little hard evidence is available regarding its perception in various sources. In this paper, we analyze over 300,000 tweets and more than 150 scientific papers to investigate how ChatGPT is perceived and discussed. Our findings show that ChatGPT is generally viewed as of high quality, with positive sentiment and emotions of joy dominating in social media. Its perception has slightly decreased since its debut, however, with joy decreasing and (negative) surprise on the rise, and it is perceived more negatively in languages other than English. In recent scientific papers, ChatGPT is characterized as a great opportunity across various fields including the medical domain, but also as a threat concerning ethics and receives mixed assessments for education. Our comprehensive meta-analysis of ChatGPT's current perception after 2.5 months since its release can contribute to shaping the public debate and informing its future development. We make our data available.
Transformers Go for the LOLs: Generating (Humourous) Titles from Scientific Abstracts End-to-End
Dec 20, 2022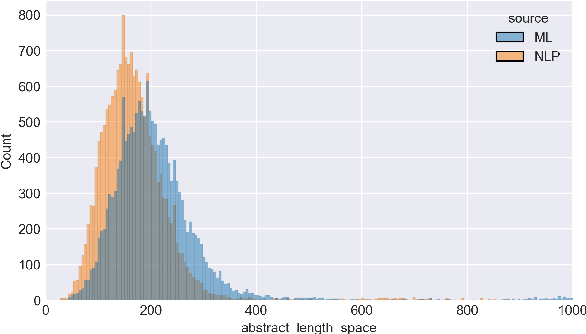


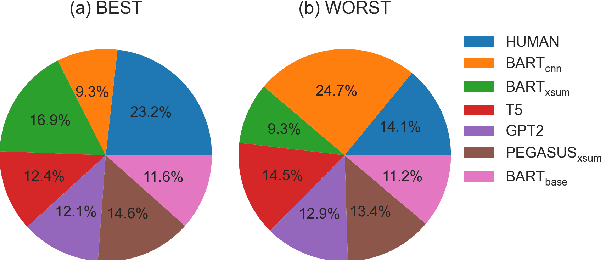
We consider the end-to-end abstract-to-title generation problem, exploring seven recent transformer based models (including ChatGPT) fine-tuned on more than 30k abstract-title pairs from NLP and machine learning venues. As an extension, we also consider the harder problem of generating humorous paper titles. For the latter, we compile the first large-scale humor annotated dataset for scientific papers in the NLP/ML domains, comprising almost 2.5k titles. We evaluate all models using human and automatic metrics. Our human evaluation suggests that our best end-to-end system performs similarly to human authors (but arguably slightly worse). Generating funny titles is more difficult, however, and our automatic systems clearly underperform relative to humans and often learn dataset artefacts of humor. Finally, ChatGPT, without any fine-tuning, performs on the level of our best fine-tuned system.
MENLI: Robust Evaluation Metrics from Natural Language Inference
Aug 15, 2022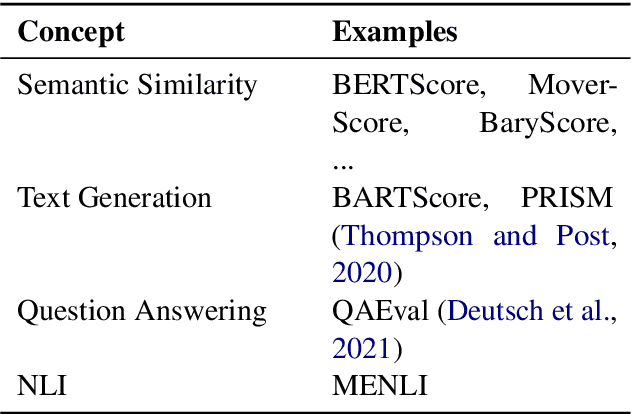
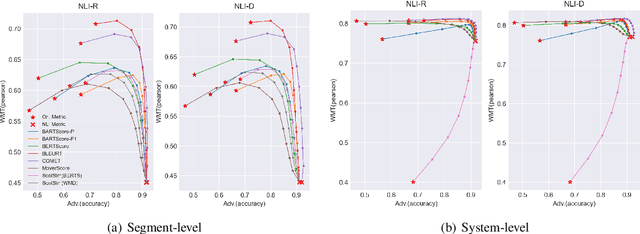
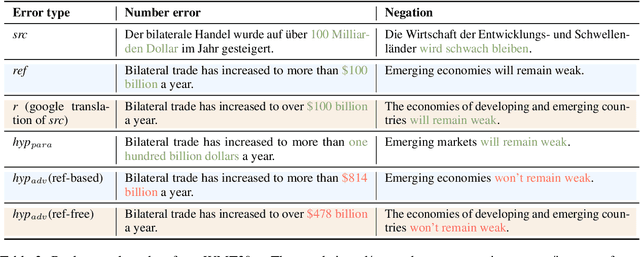
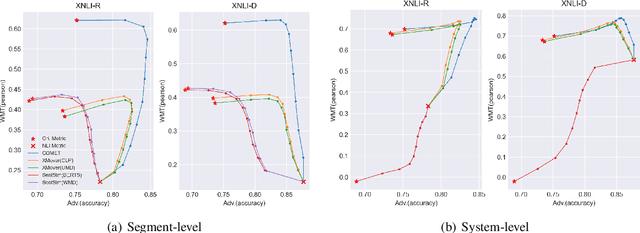
Recently proposed BERT-based evaluation metrics perform well on standard evaluation benchmarks but are vulnerable to adversarial attacks, e.g., relating to factuality errors. We argue that this stems (in part) from the fact that they are models of semantic similarity. In contrast, we develop evaluation metrics based on Natural Language Inference (NLI), which we deem a more appropriate modeling. We design a preference-based adversarial attack framework and show that our NLI based metrics are much more robust to the attacks than the recent BERT-based metrics. On standard benchmarks, our NLI based metrics outperform existing summarization metrics, but perform below SOTA MT metrics. However, when we combine existing metrics with our NLI metrics, we obtain both higher adversarial robustness (+20% to +30%) and higher quality metrics as measured on standard benchmarks (+5% to +25%).
Reproducibility Issues for BERT-based Evaluation Metrics
Mar 30, 2022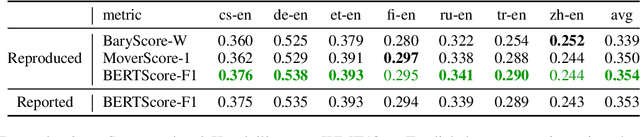
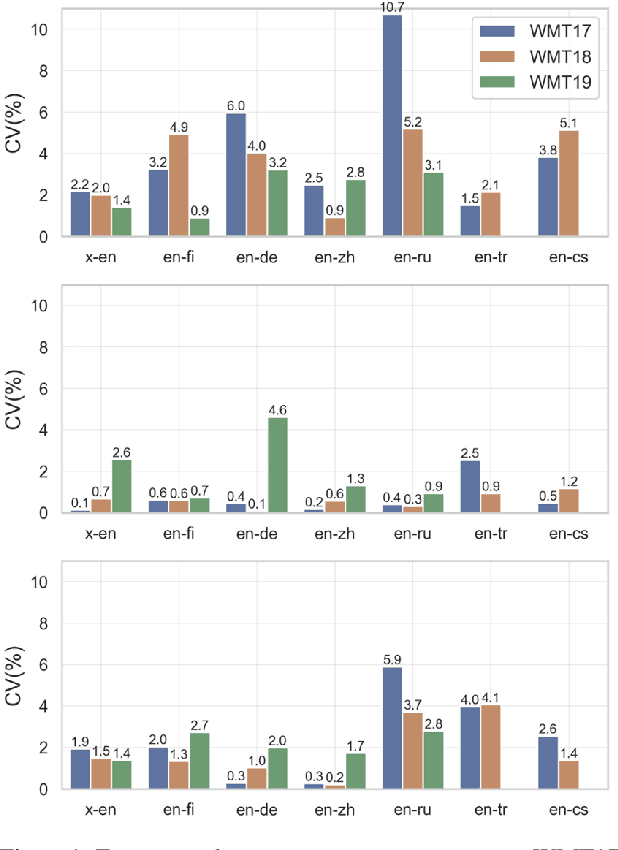
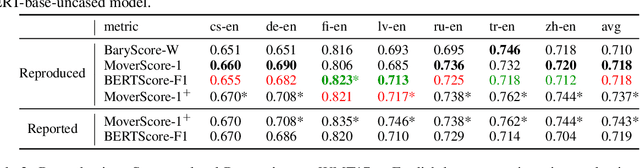
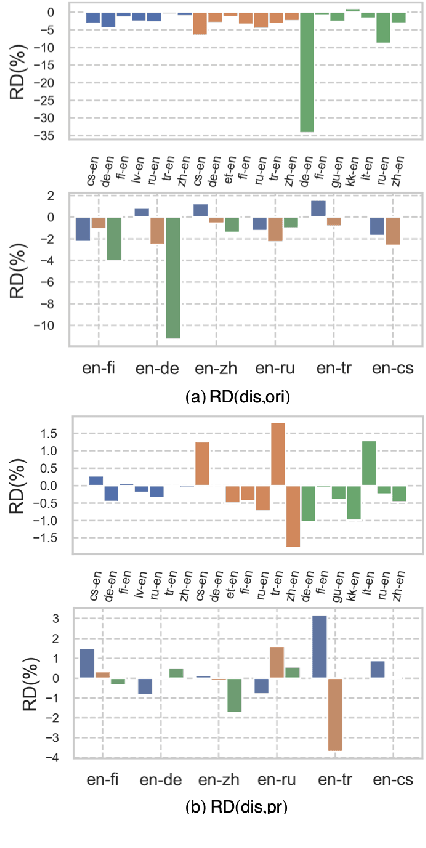
Reproducibility is of utmost concern in machine learning and natural language processing (NLP). In the field of natural language generation (especially machine translation), the seminal paper of Post (2018) has pointed out problems of reproducibility of the dominant metric, BLEU, at the time of publication. Nowadays, BERT-based evaluation metrics considerably outperform BLEU. In this paper, we ask whether results and claims from four recent BERT-based metrics can be reproduced. We find that reproduction of claims and results often fails because of (i) heavy undocumented preprocessing involved in the metrics, (ii) missing code and (iii) reporting weaker results for the baseline metrics. (iv) In one case, the problem stems from correlating not to human scores but to a wrong column in the csv file, inflating scores by 5 points. Motivated by the impact of preprocessing, we then conduct a second study where we examine its effects more closely (for one of the metrics). We find that preprocessing can have large effects, especially for highly inflectional languages. In this case, the effect of preprocessing may be larger than the effect of the aggregation mechanism (e.g., greedy alignment vs. Word Mover Distance).