 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducibility Issues for BERT-based Evaluation Metrics
Paper and Code
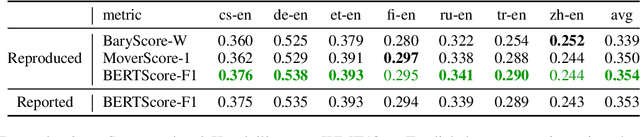
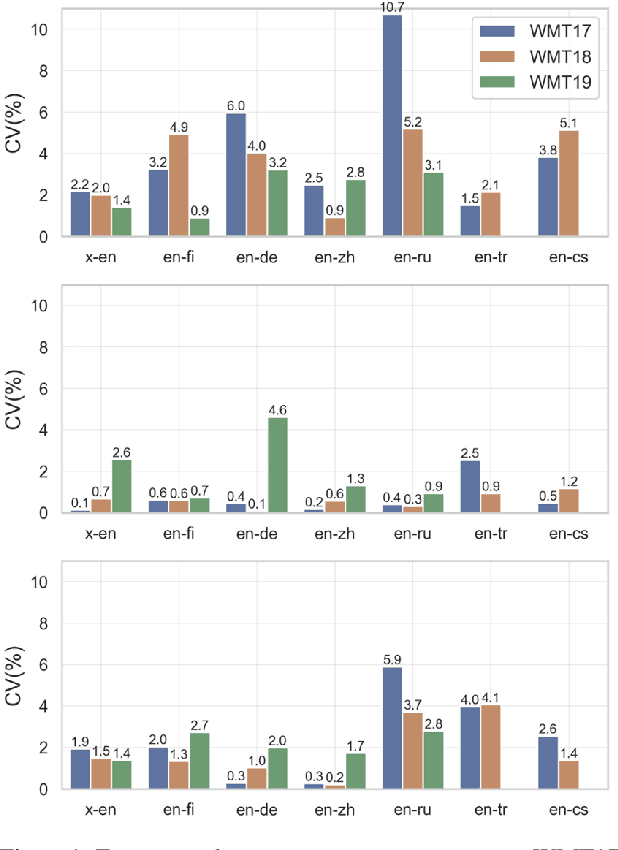
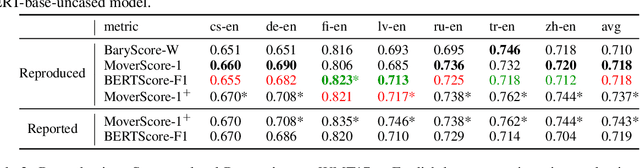
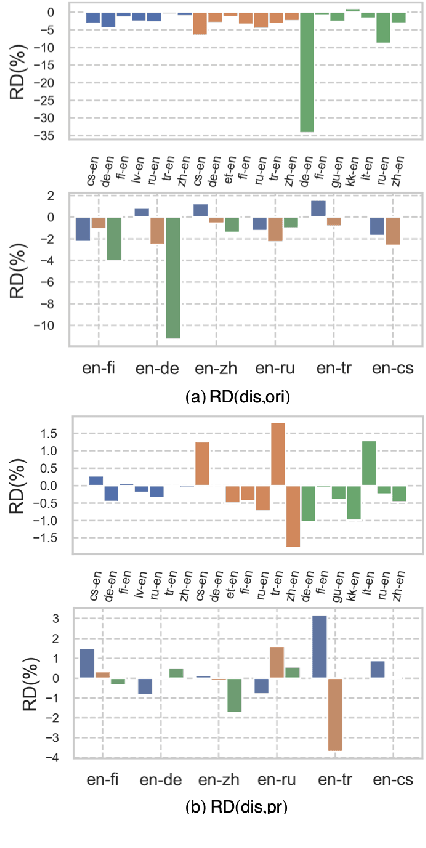
Reproducibility is of utmost concern in machine learning and natural language processing (NLP). In the field of natural language generation (especially machine translation), the seminal paper of Post (2018) has pointed out problems of reproducibility of the dominant metric, BLEU, at the time of publication. Nowadays, BERT-based evaluation metrics considerably outperform BLEU. In this paper, we ask whether results and claims from four recent BERT-based metrics can be reproduced. We find that reproduction of claims and results often fails because of (i) heavy undocumented preprocessing involved in the metrics, (ii) missing code and (iii) reporting weaker results for the baseline metrics. (iv) In one case, the problem stems from correlating not to human scores but to a wrong column in the csv file, inflating scores by 5 points. Motivated by the impact of preprocessing, we then conduct a second study where we examine its effects more closely (for one of the metrics). We find that preprocessing can have large effects, especially for highly inflectional languages. In this case, the effect of preprocessing may be larger than the effect of the aggregation mechanism (e.g., greedy alignment vs. Word Mover Distance).