 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Apr 10, 2025Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
ContrastScore: Towards Higher Quality, Less Biased, More Efficient Evaluation Metrics with Contrastive Evaluation
Apr 02, 2025Evaluating the quality of generated text automatically remains a significant challenge. Conventional reference-based metrics have been shown to exhibit relatively weak correlation with human evaluations. Recent research advocates the use of large language models (LLMs) as source-based metrics for natural language generation (NLG) assessment. While promising, LLM-based metrics, particularly those using smaller models, still fall short in aligning with human judgments. In this work, we introduce ContrastScore, a contrastive evaluation metric designed to enable higher-quality, less biased, and more efficient assessment of generated text. We evaluate ContrastScore on two NLG tasks: machine translation and summarization. Experimental results show that ContrastScore consistently achieves stronger correlation with human judgments than both single-model and ensemble-based baselines. Notably, ContrastScore based on Qwen 3B and 0.5B even outperforms Qwen 7B, despite having only half as many parameters, demonstrating its efficiency. Furthermore, it effectively mitigates common evaluation biases such as length and likelihood preferences, resulting in more robust automatic evaluation.
BatchGEMBA: Token-Efficient Machine Translation Evaluation with Batched Prompting and Prompt Compression
Mar 04, 2025Recent advancements in Large Language Model (LLM)-based Natural Language Generation evaluation have largely focused on single-example prompting, resulting in significant token overhead and computational inefficiencies. In this work, we introduce BatchGEMBA-MQM, a framework that integrates batched prompting with the GEMBA-MQM metric for machine translation evaluation. Our approach aggregates multiple translation examples into a single prompt, reducing token usage by 2-4 times (depending on the batch size) relative to single-example prompting. Furthermore, we propose a batching-aware prompt compression model that achieves an additional token reduction of 13-15% on average while also showing ability to help mitigate batching-induced quality degradation. Evaluations across several LLMs (GPT-4o, GPT-4o-mini, Mistral Small, Phi4, and CommandR7B) and varying batch sizes reveal that while batching generally negatively affects quality (but sometimes not substantially), prompt compression does not degrade further, and in some cases, recovers quality loss. For instance, GPT-4o retains over 90% of its baseline performance at a batch size of 4 when compression is applied, compared to a 44.6% drop without compression. We plan to release our code and trained models at https://github.com/NL2G/batchgemba to support future research in this domain.
PromptOptMe: Error-Aware Prompt Compression for LLM-based MT Evaluation Metrics
Dec 20, 2024Evaluating the quality of machine-generated natural language content is a challenging task in Natural Language Processing (NLP). Recently, large language models (LLMs) like GPT-4 have been employed for this purpose, but they are computationally expensive due to the extensive token usage required by complex evaluation prompts. In this paper, we propose a prompt optimization approach that uses a smaller, fine-tuned language model to compress input data for evaluation prompt, thus reducing token usage and computational cost when using larger LLMs for downstream evaluation. Our method involves a two-stage fine-tuning process: supervised fine-tuning followed by preference optimization to refine the model's outputs based on human preferences. We focus on Machine Translation (MT) evaluation and utilize the GEMBA-MQM metric as a starting point. Our results show a $2.37\times$ reduction in token usage without any loss in evaluation quality. This work makes state-of-the-art LLM-based metrics like GEMBA-MQM more cost-effective and efficient, enhancing their accessibility for broader use.
xCOMET-lite: Bridging the Gap Between Efficiency and Quality in Learned MT Evaluation Metrics
Jun 20, 2024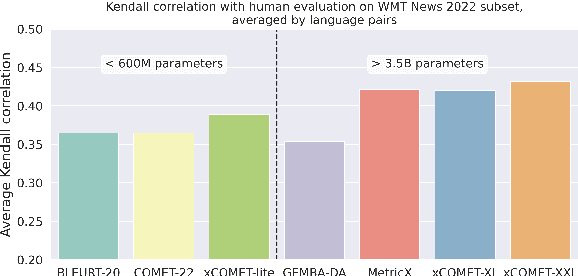
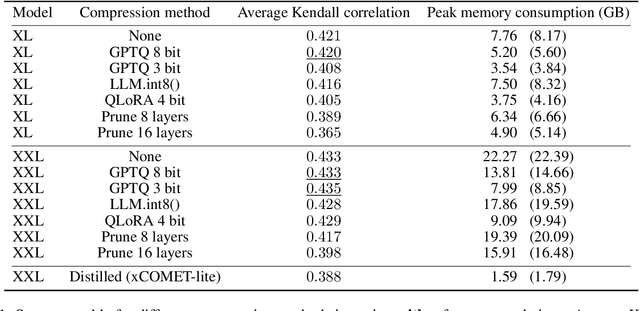
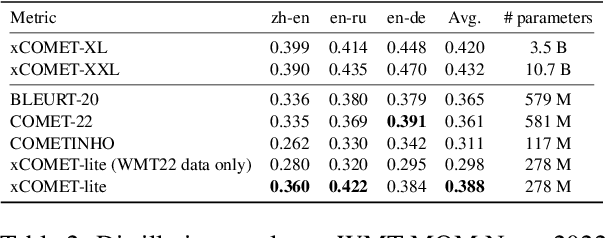
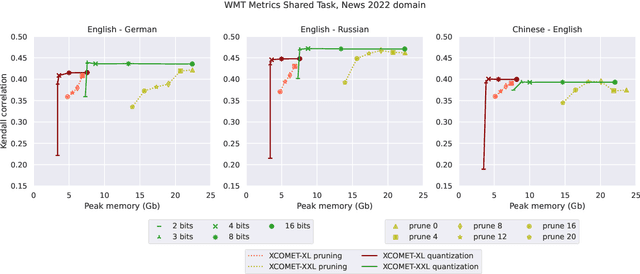
State-of-the-art trainable machine translation evaluation metrics like xCOMET achieve high correlation with human judgment but rely on large encoders (up to 10.7B parameters), making them computationally expensive and inaccessible to researchers with limited resources. To address this issue, we investigate whether the knowledge stored in these large encoders can be compressed while maintaining quality. We employ distillation, quantization, and pruning techniques to create efficient xCOMET alternatives and introduce a novel data collection pipeline for efficient black-box distillation. Our experiments show that, using quantization, xCOMET can be compressed up to three times with no quality degradation. Additionally, through distillation, we create an xCOMET-lite metric, which has only 2.6% of xCOMET-XXL parameters, but retains 92.1% of its quality. Besides, it surpasses strong small-scale metrics like COMET-22 and BLEURT-20 on the WMT22 metrics challenge dataset by 6.4%, despite using 50% fewer parameters. All code, dataset, and models are available online.
NLLG Quarterly arXiv Report 09/23: What are the most influential current AI Papers?
Dec 09, 2023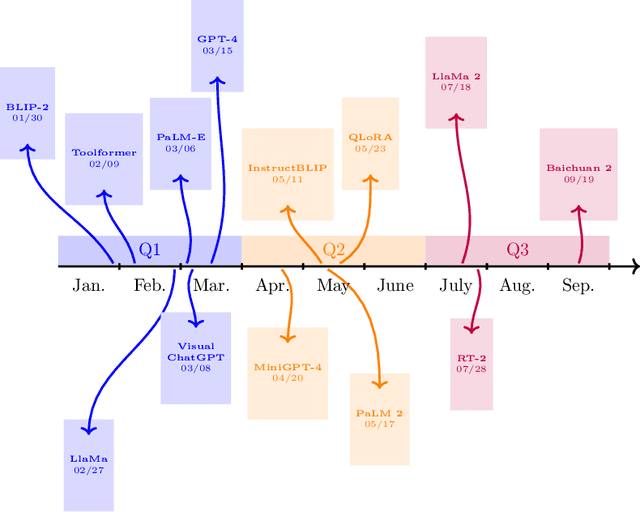

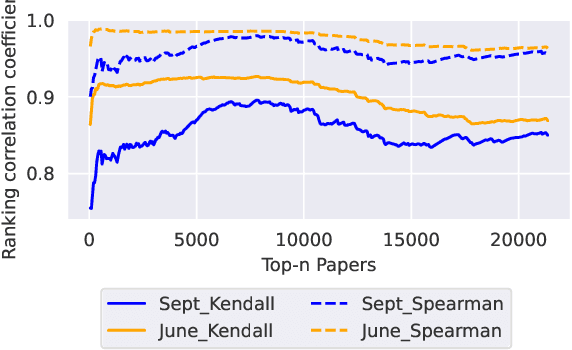
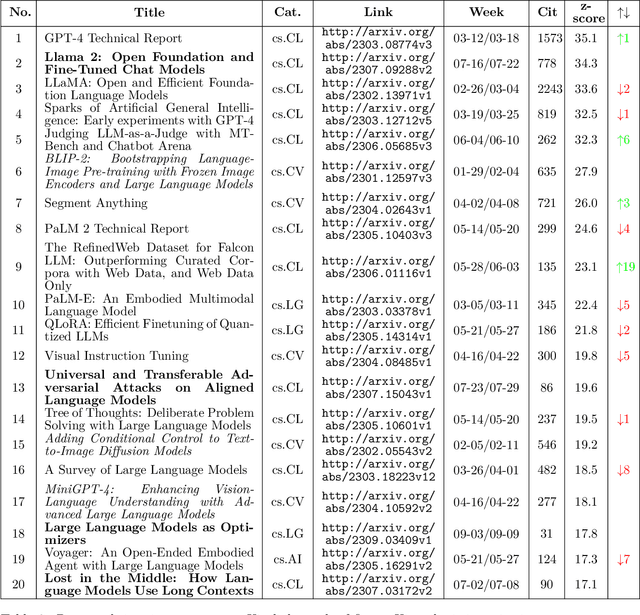
Artificial Intelligence (AI) has witnessed rapid growth, especially in the subfields Natural Language Processing (NLP), Machine Learning (ML) and Computer Vision (CV). Keeping pace with this rapid progress poses a considerable challenge for researchers and professionals in the field. In this arXiv report, the second of its kind, which covers the period from January to September 2023, we aim to provide insights and analysis that help navigate these dynamic areas of AI. We accomplish this by 1) identifying the top-40 most cited papers from arXiv in the given period, comparing the current top-40 papers to the previous report, which covered the period January to June; 2) analyzing dataset characteristics and keyword popularity; 3) examining the global sectoral distribution of institutions to reveal differences in engagement across geographical areas. Our findings highlight the continued dominance of NLP: while only 16% of all submitted papers have NLP as primary category (more than 25% have CV and ML as primary category), 50% of the most cited papers have NLP as primary category, 90% of which target LLMs. Additionally, we show that i) the US dominates among both top-40 and top-9k papers, followed by China; ii) Europe clearly lags behind and is hardly represented in the top-40 most cited papers; iii) US industry is largely overrepresented in the top-40 most influential papers.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
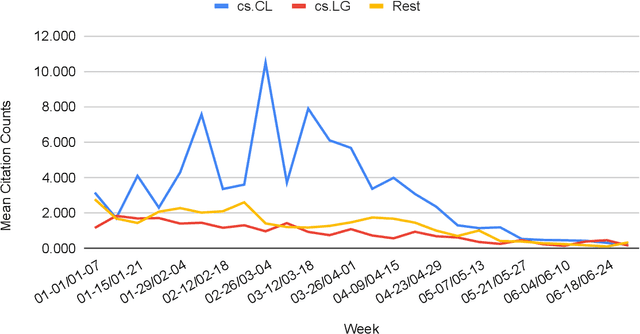
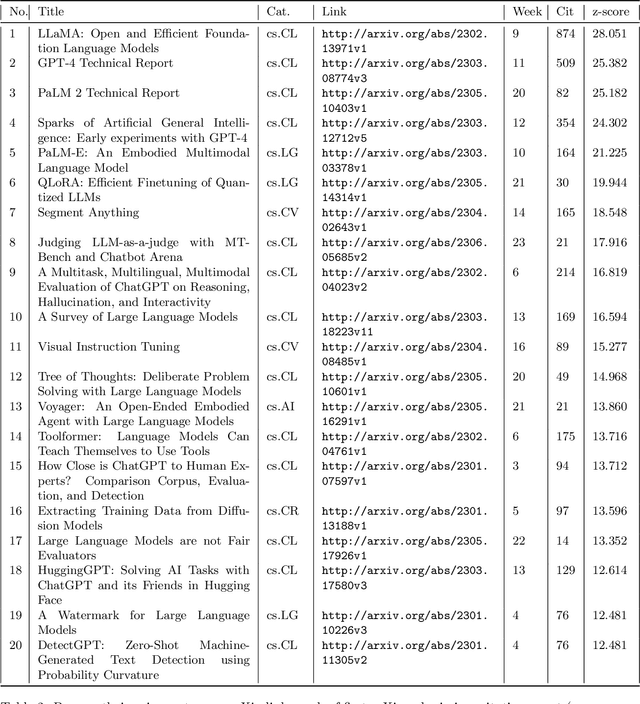
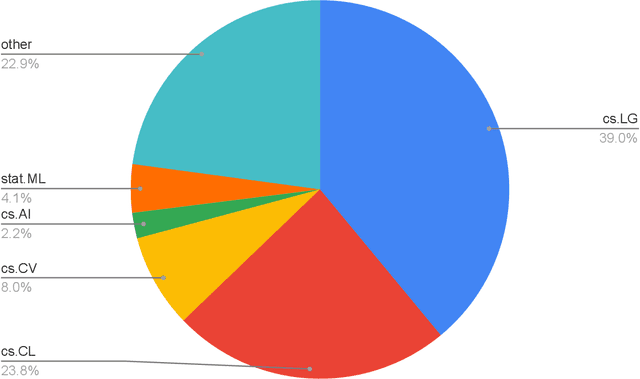
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
ChatGPT: A Meta-Analysis after 2.5 Months
Feb 20, 2023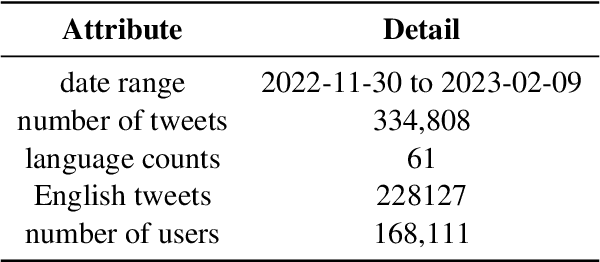
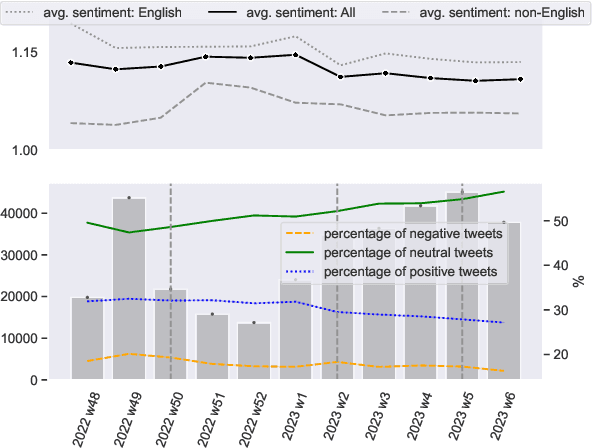
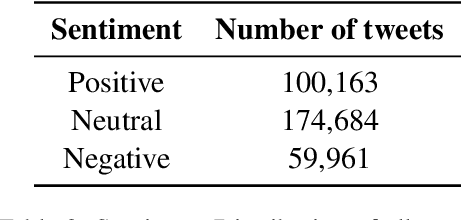
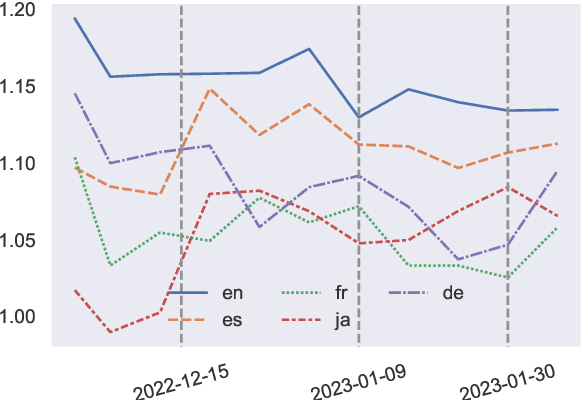
ChatGPT, a chatbot developed by OpenAI, has gained widespread popularity and media attention since its release in November 2022. However, little hard evidence is available regarding its perception in various sources. In this paper, we analyze over 300,000 tweets and more than 150 scientific papers to investigate how ChatGPT is perceived and discussed. Our findings show that ChatGPT is generally viewed as of high quality, with positive sentiment and emotions of joy dominating in social media. Its perception has slightly decreased since its debut, however, with joy decreasing and (negative) surprise on the rise, and it is perceived more negatively in languages other than English. In recent scientific papers, ChatGPT is characterized as a great opportunity across various fields including the medical domain, but also as a threat concerning ethics and receives mixed assessments for education. Our comprehensive meta-analysis of ChatGPT's current perception after 2.5 months since its release can contribute to shaping the public debate and informing its future development. We make our data available.
Towards Computationally Feasible Deep Active Learning
May 07, 2022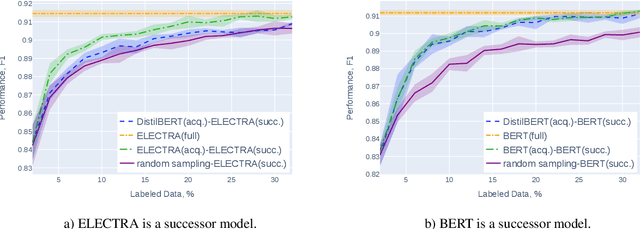
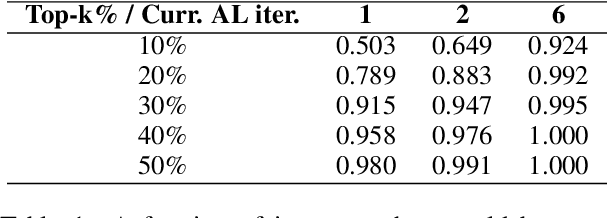
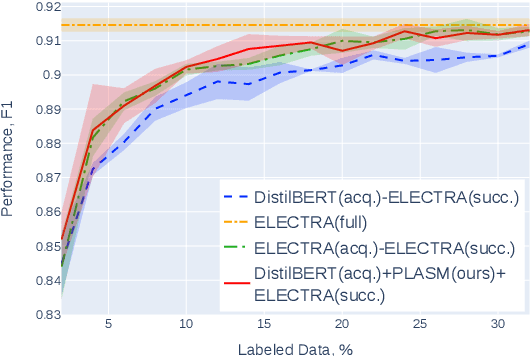
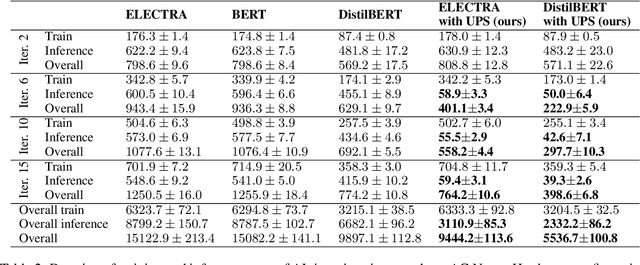
Active learning (AL) is a prominent technique for reducing the annotation effort required for training machine learning models. Deep learning offers a solution for several essential obstacles to deploying AL in practice but introduces many others. One of such problems is the excessive computational resources required to train an acquisition model and estimate its uncertainty on instances in the unlabeled pool. We propose two techniques that tackle this issue for text classification and tagging tasks, offering a substantial reduction of AL iteration duration and the computational overhead introduced by deep acquisition models in AL. We also demonstrate that our algorithm that leverages pseudo-labeling and distilled models overcomes one of the essential obstacles revealed previously in the literature. Namely, it was shown that due to differences between an acquisition model used to select instances during AL and a successor model trained on the labeled data, the benefits of AL can diminish. We show that our algorithm, despite using a smaller and faster acquisition model, is capable of training a more expressive successor model with higher performance.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Feb 18, 2021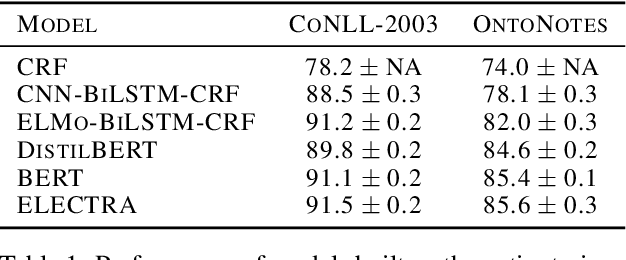
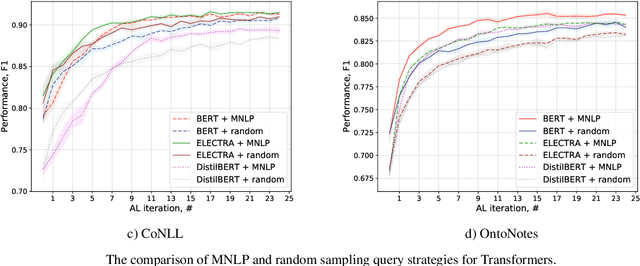
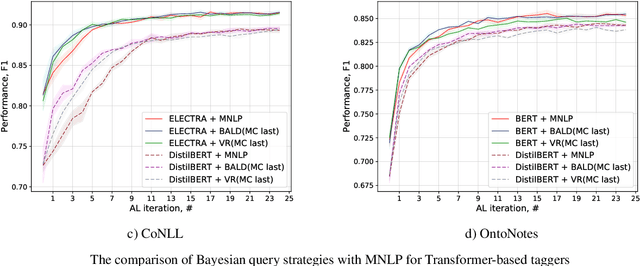
Annotating training data for sequence tagging of texts is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination for the sequence tagging task. We conduct an extensive empirical study of various Bayesian uncertainty estimation methods and Monte Carlo dropout options for deep pre-trained models in the active learning framework and find the best combinations for different types of models. Besides, we also demonstrate that to acquire instances during active learning, a full-size Transformer can be substituted with a distilled version, which yields better computational performance and reduces obstacles for applying deep active learning in practice.