 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChexFract: From General to Specialized -- Enhancing Fracture Description Generation
Nov 11, 2025Generating accurate and clinically meaningful radiology reports from chest X-ray images remains a significant challenge in medical AI. While recent vision-language models achieve strong results in general radiology report generation, they often fail to adequately describe rare but clinically important pathologies like fractures. This work addresses this gap by developing specialized models for fracture pathology detection and description. We train fracture-specific vision-language models with encoders from MAIRA-2 and CheXagent, demonstrating significant improvements over general-purpose models in generating accurate fracture descriptions. Analysis of model outputs by fracture type, location, and age reveals distinct strengths and limitations of current vision-language model architectures. We publicly release our best-performing fracture-reporting model, facilitating future research in accurate reporting of rare pathologies.
HOTA: Hamiltonian framework for Optimal Transport Advection
Jul 23, 2025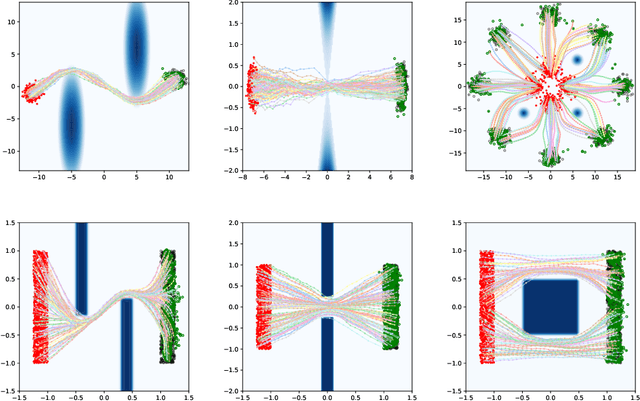
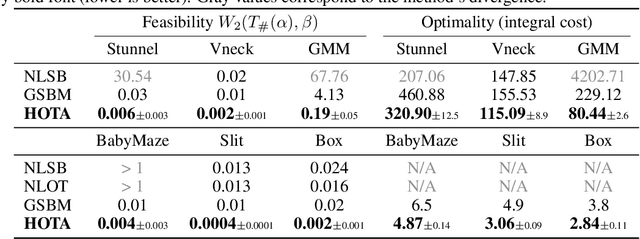
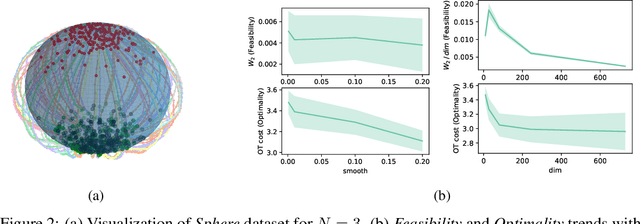
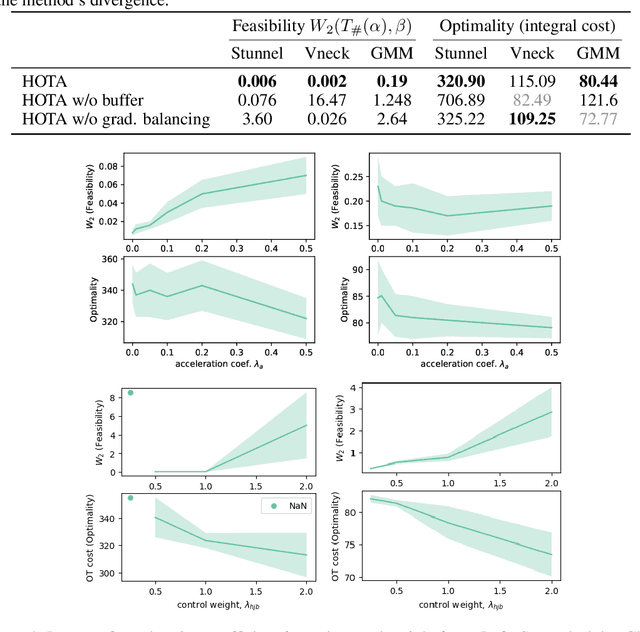
Optimal transport (OT) has become a natural framework for guiding the probability flows. Yet, the majority of recent generative models assume trivial geometry (e.g., Euclidean) and rely on strong density-estimation assumptions, yielding trajectories that do not respect the true principles of optimality in the underlying manifold. We present Hamiltonian Optimal Transport Advection (HOTA), a Hamilton-Jacobi-Bellman based method that tackles the dual dynamical OT problem explicitly through Kantorovich potentials, enabling efficient and scalable trajectory optimization. Our approach effectively evades the need for explicit density modeling, performing even when the cost functionals are non-smooth. Empirically, HOTA outperforms all baselines in standard benchmarks, as well as in custom datasets with non-differentiable costs, both in terms of feasibility and optimality.
Suppressing Modulation Instability with Reinforcement Learning
Apr 05, 2024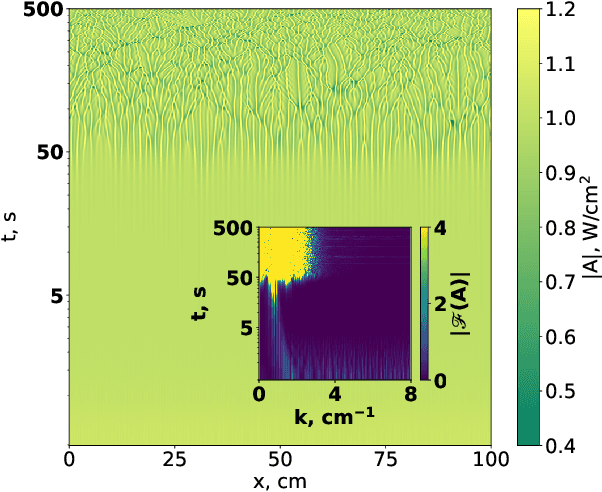
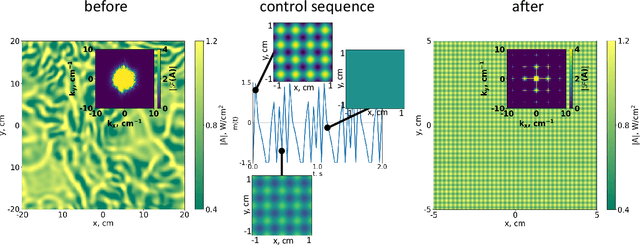
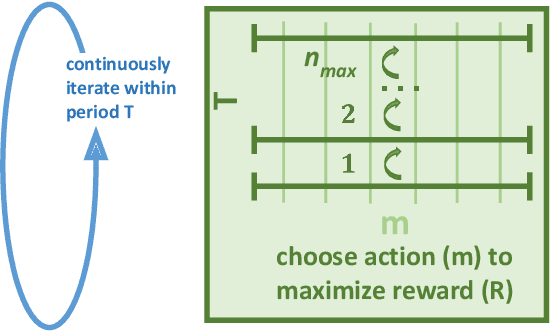
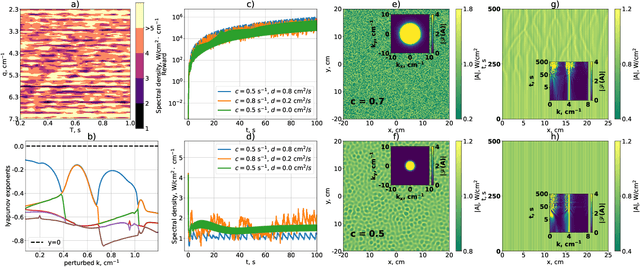
Modulation instability is a phenomenon of spontaneous pattern formation in nonlinear media, oftentimes leading to an unpredictable behaviour and a degradation of a signal of interest. We propose an approach based on reinforcement learning to suppress the unstable modes by optimizing the parameters for the time modulation of the potential in the nonlinear system. We test our approach in 1D and 2D cases and propose a new class of physically-meaningful reward functions to guarantee tamed instability.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024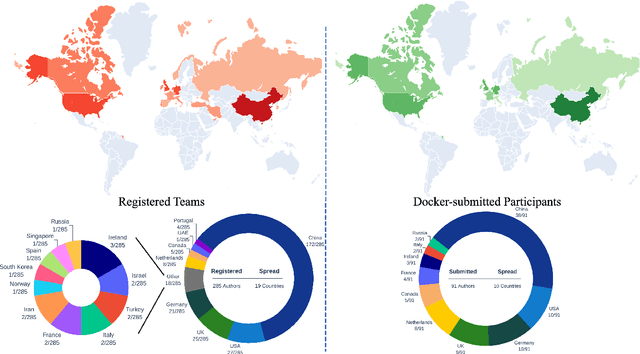
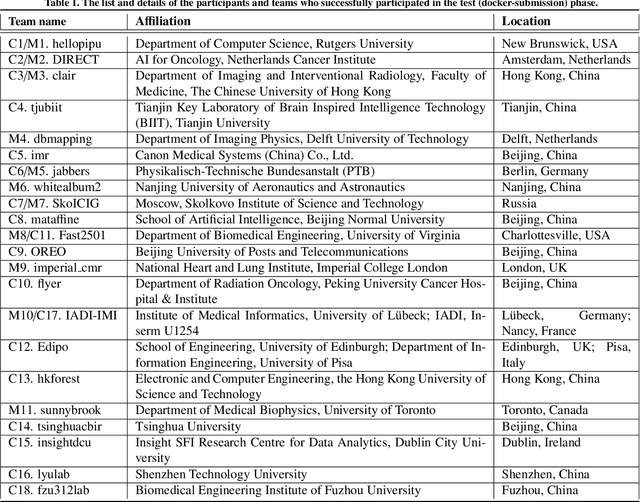
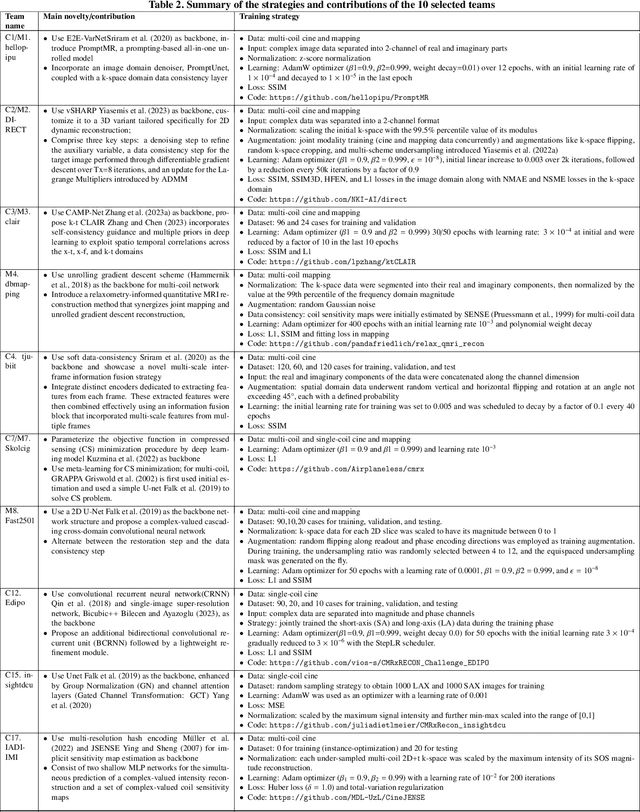
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024



This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
ENOT: Expectile Regularization for Fast and Accurate Training of Neural Optimal Transport
Mar 06, 2024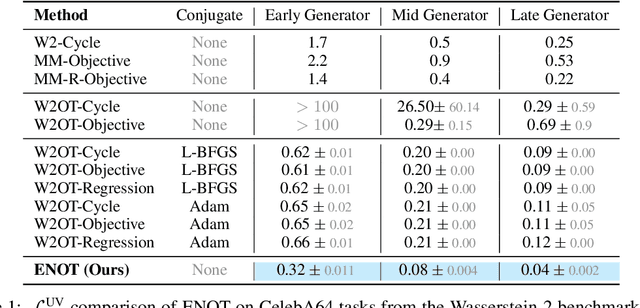

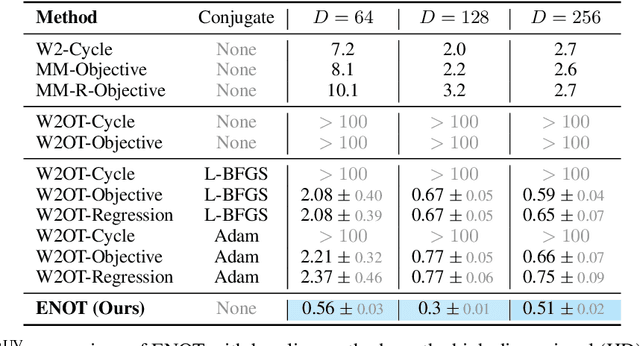
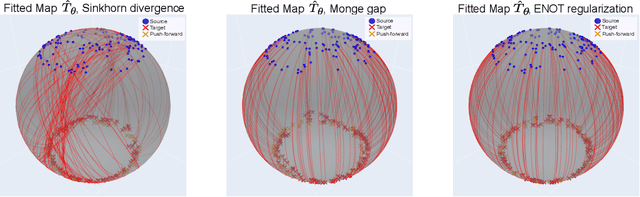
We present a new extension for Neural Optimal Transport (NOT) training procedure, capable of accurately and efficiently estimating optimal transportation plan via specific regularisation on conjugate potentials. The main bottleneck of existing NOT solvers is associated with the procedure of finding a near-exact approximation of the conjugate operator (i.e., the c-transform), which is done either by optimizing over maximin objectives or by the computationally-intensive fine-tuning of the initial approximated prediction. We resolve both issues by proposing a new, theoretically justified loss in the form of expectile regularization that enforces binding conditions on the learning dual potentials. Such a regularization provides the upper bound estimation over the distribution of possible conjugate potentials and makes the learning stable, eliminating the need for additional extensive finetuning. We formally justify the efficiency of our method, called Expectile-Regularised Neural Optimal Transport (ENOT). ENOT outperforms previous state-of-the-art approaches on the Wasserstein-2 benchmark tasks by a large margin (up to a 3-fold improvement in quality and up to a 10-fold improvement in runtime).
Align Your Intents: Offline Imitation Learning via Optimal Transport
Feb 20, 2024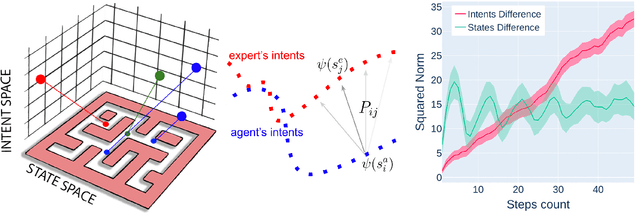



Offline reinforcement learning (RL) addresses the problem of sequential decision-making by learning optimal policy through pre-collected data, without interacting with the environment. As yet, it has remained somewhat impractical, because one rarely knows the reward explicitly and it is hard to distill it retrospectively. Here, we show that an imitating agent can still learn the desired behavior merely from observing the expert, despite the absence of explicit rewards or action labels. In our method, AILOT (Aligned Imitation Learning via Optimal Transport), we involve special representation of states in a form of intents that incorporate pairwise spatial distances within the data. Given such representations, we define intrinsic reward function via optimal transport distance between the expert's and the agent's trajectories. We report that AILOT outperforms state-of-the art offline imitation learning algorithms on D4RL benchmarks and improves the performance of other offline RL algorithms in the sparse-reward tasks.
FS-Net: Full Scale Network and Adaptive Threshold for Improving Extraction of Micro-Retinal Vessel Structures
Nov 19, 2023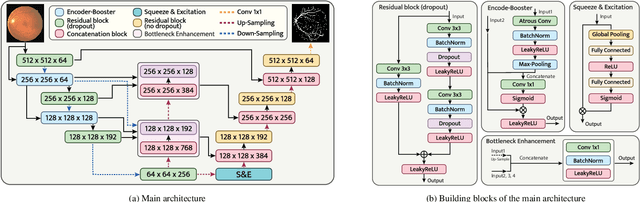

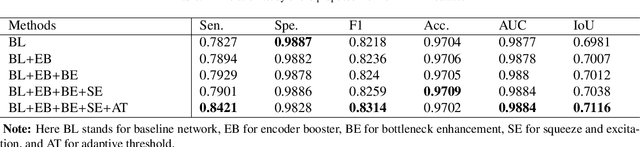
Retinal vascular segmentation, is a widely researched subject in biomedical image processing, aims to relieve ophthalmologists' workload when treating and detecting retinal disorders. However, segmenting retinal vessels has its own set of challenges, with prior techniques failing to generate adequate results when segmenting branches and microvascular structures. The neural network approaches used recently are characterized by the inability to keep local and global properties together and the failure to capture tiny end vessels make it challenging to attain the desired result. To reduce this retinal vessel segmentation problem, we propose a full-scale micro-vessel extraction mechanism based on an encoder-decoder neural network architecture, sigmoid smoothing, and an adaptive threshold method. The network consists of of residual, encoder booster, bottleneck enhancement, squeeze, and excitation building blocks. All of these blocks together help to improve the feature extraction and prediction of the segmentation map. The proposed solution has been evaluated using the DRIVE, CHASE-DB1, and STARE datasets, and competitive results are obtained when compared with previous studies. The AUC and accuracy on the DRIVE dataset are 0.9884 and 0.9702, respectively. On the CHASE-DB1 dataset, the scores are 0.9903 and 0.9755, respectively. On the STARE dataset, the scores are 0.9916 and 0.9750, respectively. The performance achieved is one step ahead of what has been done in previous studies, and this results in a higher chance of having this solution in real-life diagnostic centers that seek ophthalmologists attention.
DeepLOC: Deep Learning-based Bone Pathology Localization and Classification in Wrist X-ray Images
Aug 24, 2023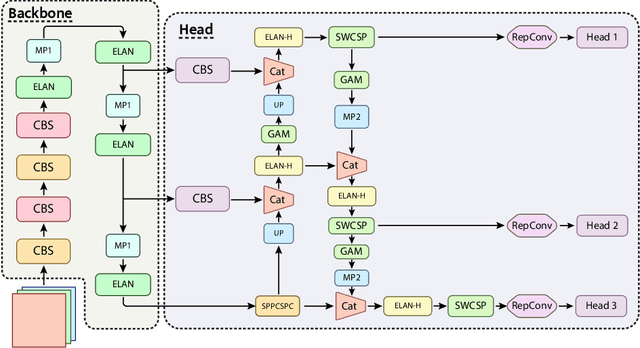
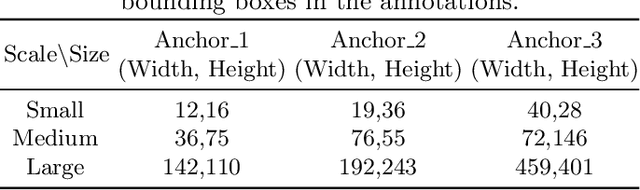
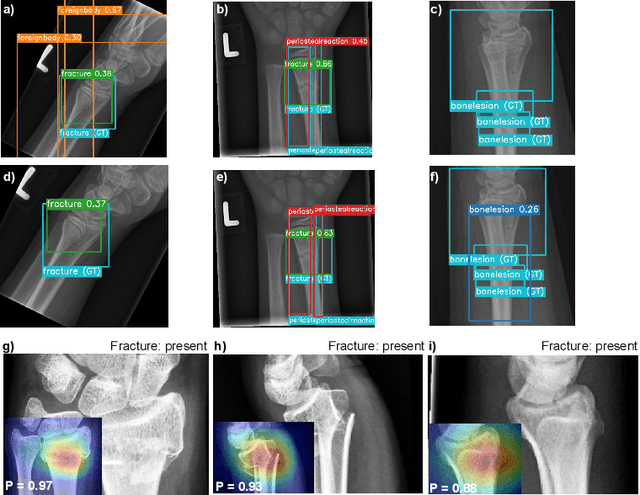
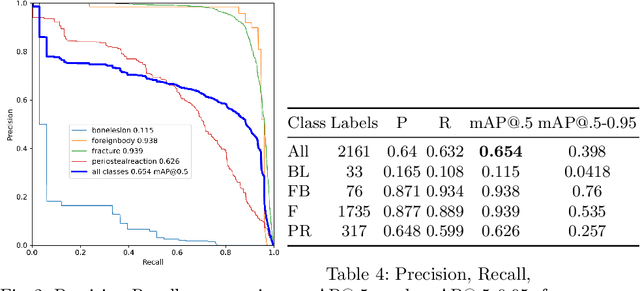
In recent years, computer-aided diagnosis systems have shown great potential in assisting radiologists with accurate and efficient medical image analysis. This paper presents a novel approach for bone pathology localization and classification in wrist X-ray images using a combination of YOLO (You Only Look Once) and the Shifted Window Transformer (Swin) with a newly proposed block. The proposed methodology addresses two critical challenges in wrist X-ray analysis: accurate localization of bone pathologies and precise classification of abnormalities. The YOLO framework is employed to detect and localize bone pathologies, leveraging its real-time object detection capabilities. Additionally, the Swin, a transformer-based module, is utilized to extract contextual information from the localized regions of interest (ROIs) for accurate classification.
Self-supervised Physics-based Denoising for Computed Tomography
Nov 01, 2022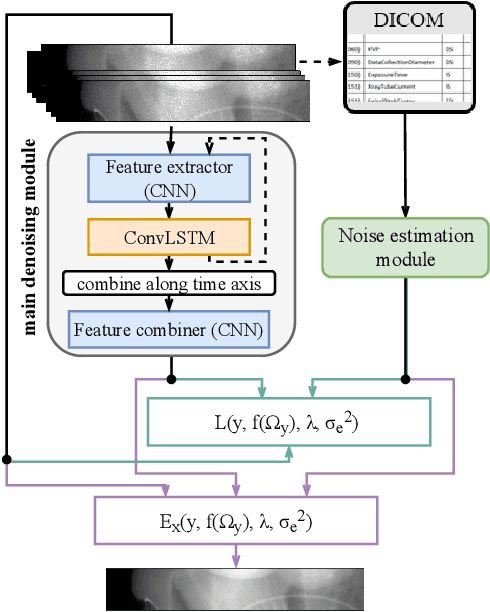


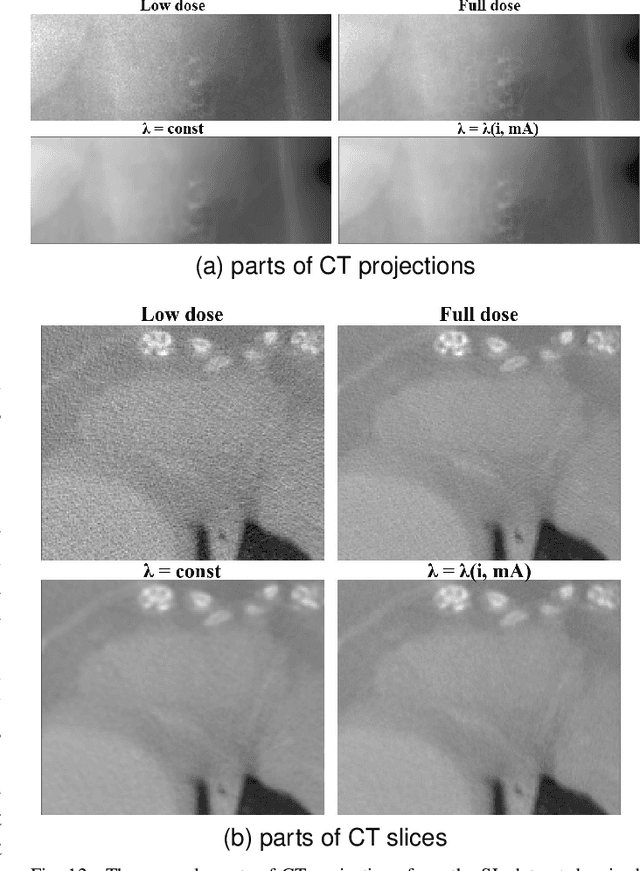
Computed Tomography (CT) imposes risk on the patients due to its inherent X-ray radiation, stimulating the development of low-dose CT (LDCT) imaging methods. Lowering the radiation dose reduces the health risks but leads to noisier measurements, which decreases the tissue contrast and causes artifacts in CT images. Ultimately, these issues could affect the perception of medical personnel and could cause misdiagnosis. Modern deep learning noise suppression methods alleviate the challenge but require low-noise-high-noise CT image pairs for training, rarely collected in regular clinical workflows. In this work, we introduce a new self-supervised approach for CT denoising Noise2NoiseTD-ANM that can be trained without the high-dose CT projection ground truth images. Unlike previously proposed self-supervised techniques, the introduced method exploits the connections between the adjacent projections and the actual model of CT noise distribution. Such a combination allows for interpretable no-reference denoising using nothing but the original noisy LDCT projections. Our experiments with LDCT data demonstrate that the proposed method reaches the level of the fully supervised models, sometimes superseding them, easily generalizes to various noise levels, and outperforms state-of-the-art self-supervised denoising algorithms.