 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Duality between Flow and Field Matching
Feb 02, 2026Conditional Flow Matching (CFM) unifies conventional generative paradigms such as diffusion models and flow matching. Interaction Field Matching (IFM) is a newer framework that generalizes Electrostatic Field Matching (EFM) rooted in Poisson Flow Generative Models (PFGM). While both frameworks define generative dynamics, they start from different objects: CFM specifies a conditional probability path in data space, whereas IFM specifies a physics-inspired interaction field in an augmented data space. This raises a basic question: are CFM and IFM genuinely different, or are they two descriptions of the same underlying dynamics? We show that they coincide for a natural subclass of IFM that we call forward-only IFM. Specifically, we construct a bijection between CFM and forward-only IFM. We further show that general IFM is strictly more expressive: it includes EFM and other interaction fields that cannot be realized within the standard CFM formulation. Finally, we highlight how this duality can benefit both frameworks: it provides a probabilistic interpretation of forward-only IFM and yields novel, IFM-driven techniques for CFM.
Q-RAG: Long Context Multi-step Retrieval via Value-based Embedder Training
Nov 10, 2025Retrieval-Augmented Generation (RAG) methods enhance LLM performance by efficiently filtering relevant context for LLMs, reducing hallucinations and inference cost. However, most existing RAG methods focus on single-step retrieval, which is often insufficient for answering complex questions that require multi-step search. Recently, multi-step retrieval approaches have emerged, typically involving the fine-tuning of small LLMs to perform multi-step retrieval. This type of fine-tuning is highly resource-intensive and does not enable the use of larger LLMs. In this work, we propose Q-RAG, a novel approach that fine-tunes the Embedder model for multi-step retrieval using reinforcement learning (RL). Q-RAG offers a competitive, resource-efficient alternative to existing multi-step retrieval methods for open-domain question answering and achieves state-of-the-art results on the popular long-context benchmarks Babilong and RULER for contexts up to 10M tokens.
HOTA: Hamiltonian framework for Optimal Transport Advection
Jul 23, 2025Optimal transport (OT) has become a natural framework for guiding the probability flows. Yet, the majority of recent generative models assume trivial geometry (e.g., Euclidean) and rely on strong density-estimation assumptions, yielding trajectories that do not respect the true principles of optimality in the underlying manifold. We present Hamiltonian Optimal Transport Advection (HOTA), a Hamilton-Jacobi-Bellman based method that tackles the dual dynamical OT problem explicitly through Kantorovich potentials, enabling efficient and scalable trajectory optimization. Our approach effectively evades the need for explicit density modeling, performing even when the cost functionals are non-smooth. Empirically, HOTA outperforms all baselines in standard benchmarks, as well as in custom datasets with non-differentiable costs, both in terms of feasibility and optimality.
ENOT: Expectile Regularization for Fast and Accurate Training of Neural Optimal Transport
Mar 06, 2024We present a new extension for Neural Optimal Transport (NOT) training procedure, capable of accurately and efficiently estimating optimal transportation plan via specific regularisation on conjugate potentials. The main bottleneck of existing NOT solvers is associated with the procedure of finding a near-exact approximation of the conjugate operator (i.e., the c-transform), which is done either by optimizing over maximin objectives or by the computationally-intensive fine-tuning of the initial approximated prediction. We resolve both issues by proposing a new, theoretically justified loss in the form of expectile regularization that enforces binding conditions on the learning dual potentials. Such a regularization provides the upper bound estimation over the distribution of possible conjugate potentials and makes the learning stable, eliminating the need for additional extensive finetuning. We formally justify the efficiency of our method, called Expectile-Regularised Neural Optimal Transport (ENOT). ENOT outperforms previous state-of-the-art approaches on the Wasserstein-2 benchmark tasks by a large margin (up to a 3-fold improvement in quality and up to a 10-fold improvement in runtime).
Align Your Intents: Offline Imitation Learning via Optimal Transport
Feb 20, 2024Offline reinforcement learning (RL) addresses the problem of sequential decision-making by learning optimal policy through pre-collected data, without interacting with the environment. As yet, it has remained somewhat impractical, because one rarely knows the reward explicitly and it is hard to distill it retrospectively. Here, we show that an imitating agent can still learn the desired behavior merely from observing the expert, despite the absence of explicit rewards or action labels. In our method, AILOT (Aligned Imitation Learning via Optimal Transport), we involve special representation of states in a form of intents that incorporate pairwise spatial distances within the data. Given such representations, we define intrinsic reward function via optimal transport distance between the expert's and the agent's trajectories. We report that AILOT outperforms state-of-the art offline imitation learning algorithms on D4RL benchmarks and improves the performance of other offline RL algorithms in the sparse-reward tasks.
Explain My Surprise: Learning Efficient Long-Term Memory by Predicting Uncertain Outcomes
Jul 27, 2022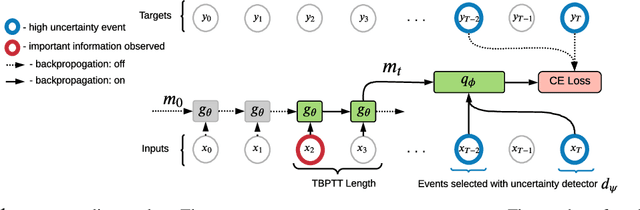
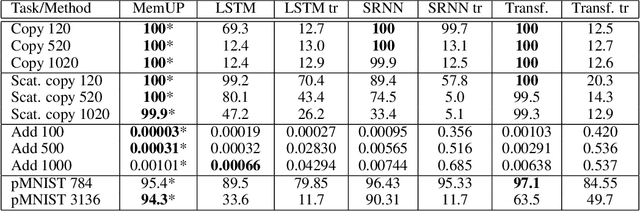
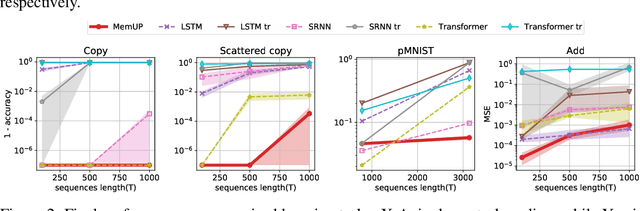
In many sequential tasks, a model needs to remember relevant events from the distant past to make correct predictions. Unfortunately, a straightforward application of gradient based training requires intermediate computations to be stored for every element of a sequence. This requires prohibitively large computing memory if a sequence consists of thousands or even millions elements, and as a result, makes learning of very long-term dependencies infeasible. However, the majority of sequence elements can usually be predicted by taking into account only temporally local information. On the other hand, predictions affected by long-term dependencies are sparse and characterized by high uncertainty given only local information. We propose MemUP, a new training method that allows to learn long-term dependencies without backpropagating gradients through the whole sequence at a time. This method can be potentially applied to any gradient based sequence learning. MemUP implementation for recurrent architectures shows performances better or comparable to baselines while requiring significantly less computing memory.
Data Augmentation with Manifold Barycenters
Apr 02, 2021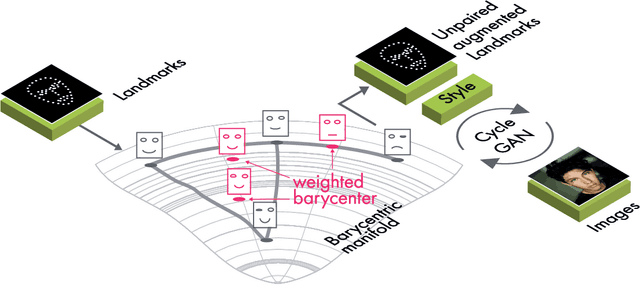

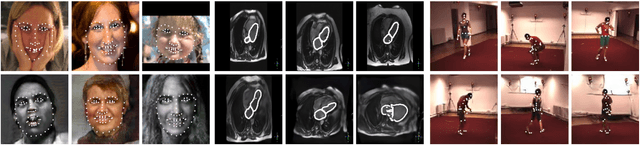

The training of Generative Adversarial Networks (GANs) requires a large amount of data, stimulating the development of new data augmentation methods to alleviate the challenge. Oftentimes, these methods either fail to produce enough new data or expand the dataset beyond the original knowledge domain. In this paper, we propose a new way of representing the available knowledge in the manifold of data barycenters. Such a representation allows performing data augmentation based on interpolation between the nearest data elements using Wasserstein distance. The proposed method finds cliques in the nearest-neighbors graph and, at each sampling iteration, randomly draws one clique to compute the Wasserstein barycenter with random uniform weights. These barycenters then become the new natural-looking elements that one could add to the dataset. We apply this approach to the problem of landmarks detection and augment the available landmarks data within the dataset. Additionally, the idea is validated on cardiac data for the task of medical segmentation. Our approach reduces the overfitting and improves the quality metrics both beyond the original data outcome and beyond the result obtained with classical augmentation methods.
BRULÉ: Barycenter-Regularized Unsupervised Landmark Extraction
Jun 20, 2020



Unsupervised retrieval of image features is vital for many computer vision tasks where the annotation is missing or scarce. In this work, we propose a new unsupervised approach to detect the landmarks in images, and we validate it on the popular task of human face key-points extraction. The method is based on the idea of auto-encoding the wanted landmarks in the latent space while discarding the non-essential information in the image and effectively preserving the interpretability. The interpretable latent space representation is achieved with the aid of a novel two-step regularization paradigm. The first regularization step evaluates transport distance from a given set of landmarks to the average value (the barycenter by Wasserstein distance). The second regularization step controls deviations from the barycenter by applying random geometric deformations synchronously to the initial image and to the encoded landmarks. During decoding, we add style features generated from the noise and reconstruct the initial image by the generative adversarial network (GAN) with transposed convolutions modulated by this style. We demonstrate the effectiveness of the approach both in unsupervised and in semi-supervised training scenarios using the 300-W and the CelebA datasets. The proposed regularization paradigm is shown to prevent overfitting, and the detection quality is shown to improve beyond the supervised outcome.
Unsupervised non-parametric change point detection in quasi-periodic signals
Feb 07, 2020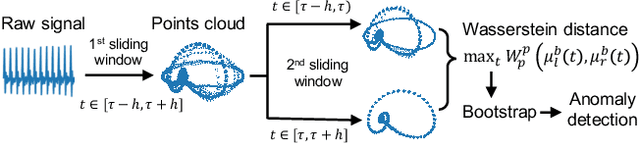


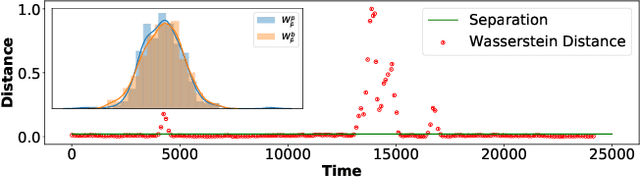
We propose a new unsupervised and non-parametric method to detect change points in intricate quasi-periodic signals. The detection relies on optimal transport theory combined with topological analysis and the bootstrap procedure. The algorithm is designed to detect changes in virtually any harmonic or a partially harmonic signal and is verified on three different sources of physiological data streams. We successfully find abnormal or irregular cardiac cycles in the waveforms for the six of the most frequent types of clinical arrhythmias using a single algorithm. The validation and the efficiency of the method are shown both on synthetic and on real time series. Our unsupervised approach reaches the level of performance of the supervised state-of-the-art techniques. We provide conceptual justification for the efficiency of the method and prove the convergence of the bootstrap procedure theoretically.