 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAME: Flexible LLM-Assisted Moderation Engine
Feb 13, 2025The rapid advancement of Large Language Models (LLMs) has introduced significant challenges in moderating user-model interactions. While LLMs demonstrate remarkable capabilities, they remain vulnerable to adversarial attacks, particularly ``jailbreaking'' techniques that bypass content safety measures. Current content moderation systems, which primarily rely on input prompt filtering, have proven insufficient, with techniques like Best-of-N (BoN) jailbreaking achieving success rates of 80% or more against popular LLMs. In this paper, we introduce Flexible LLM-Assisted Moderation Engine (FLAME): a new approach that shifts the focus from input filtering to output moderation. Unlike traditional circuit-breaking methods that analyze user queries, FLAME evaluates model responses, offering several key advantages: (1) computational efficiency in both training and inference, (2) enhanced resistance to BoN jailbreaking attacks, and (3) flexibility in defining and updating safety criteria through customizable topic filtering. Our experiments demonstrate that FLAME significantly outperforms current moderation systems. For example, FLAME reduces attack success rate in GPT-4o-mini and DeepSeek-v3 by a factor of ~9, while maintaining low computational overhead. We provide comprehensive evaluation on various LLMs and analyze the engine's efficiency against the state-of-the-art jailbreaking. This work contributes to the development of more robust and adaptable content moderation systems for LLMs.
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022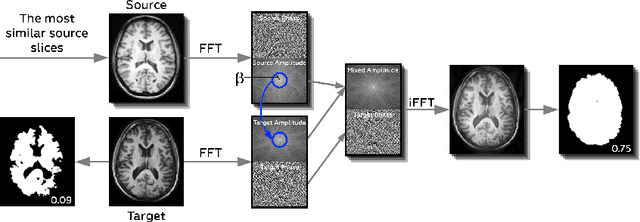

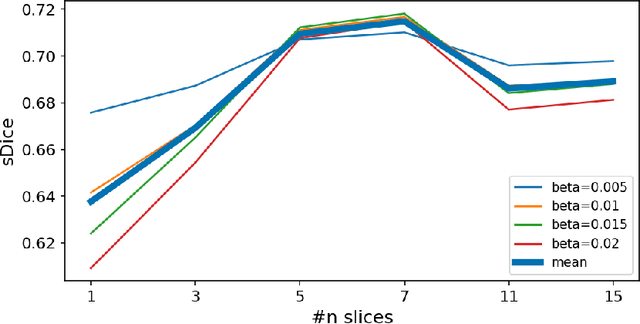

Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.
Data Augmentation with Manifold Barycenters
Apr 02, 2021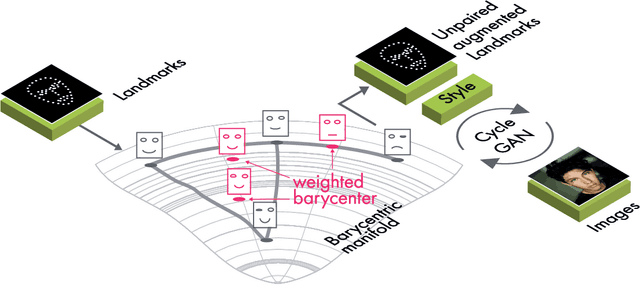

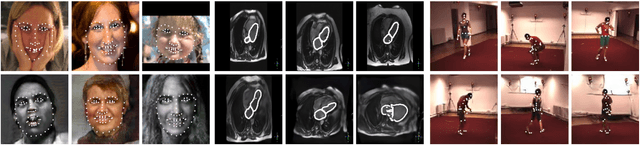

The training of Generative Adversarial Networks (GANs) requires a large amount of data, stimulating the development of new data augmentation methods to alleviate the challenge. Oftentimes, these methods either fail to produce enough new data or expand the dataset beyond the original knowledge domain. In this paper, we propose a new way of representing the available knowledge in the manifold of data barycenters. Such a representation allows performing data augmentation based on interpolation between the nearest data elements using Wasserstein distance. The proposed method finds cliques in the nearest-neighbors graph and, at each sampling iteration, randomly draws one clique to compute the Wasserstein barycenter with random uniform weights. These barycenters then become the new natural-looking elements that one could add to the dataset. We apply this approach to the problem of landmarks detection and augment the available landmarks data within the dataset. Additionally, the idea is validated on cardiac data for the task of medical segmentation. Our approach reduces the overfitting and improves the quality metrics both beyond the original data outcome and beyond the result obtained with classical augmentation methods.
Adaptive Neural Layer for Globally Filtered Segmentation
Oct 02, 2020
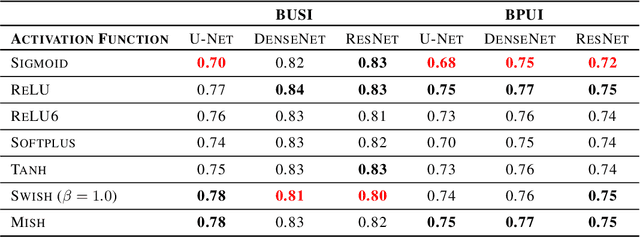

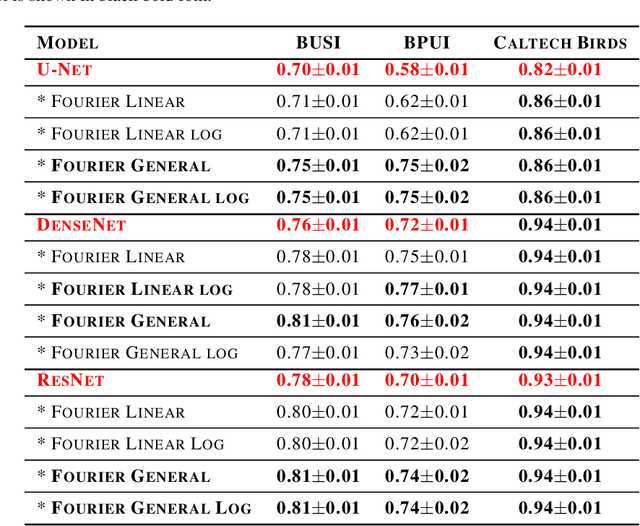
This study is motivated by typical images taken during ultrasonic examinations in the clinic. Their grainy appearance, low resolution, and poor contrast demand an eye of a very qualified expert to discern targets and to spot pathologies. Training a segmentation model on such data is frequently accompanied by excessive pre-processing and image adjustments, with an accumulation of the localization error emerging due to the digital post-filtering artifacts and due to the annotation uncertainty. Each patient case generally requires an individually tuned frequency filter to obtain optimal image contrast and to optimize the segmentation quality. Thus, we aspired to invent an adaptive global frequency-filtering neural layer to "learn" optimal frequency filter for each image together with the weights of the segmentation network itself. Specifically, our model receives the source image in the spatial domain, automatically selects the necessary frequencies from the frequency domain, and transmits the inverse-transform image to the convolutional neural network for concurrent segmentation. In our experiments, such "learnable" filters boosted typical U-Net segmentation performance by 10% and made the training of other popular models (DenseNet and ResNet) almost twice faster. In our experiments, this trait holds both for two public datasets with ultrasonic images (breast and nerves), and for natural images (Caltech birds).
BRULÉ: Barycenter-Regularized Unsupervised Landmark Extraction
Jun 20, 2020



Unsupervised retrieval of image features is vital for many computer vision tasks where the annotation is missing or scarce. In this work, we propose a new unsupervised approach to detect the landmarks in images, and we validate it on the popular task of human face key-points extraction. The method is based on the idea of auto-encoding the wanted landmarks in the latent space while discarding the non-essential information in the image and effectively preserving the interpretability. The interpretable latent space representation is achieved with the aid of a novel two-step regularization paradigm. The first regularization step evaluates transport distance from a given set of landmarks to the average value (the barycenter by Wasserstein distance). The second regularization step controls deviations from the barycenter by applying random geometric deformations synchronously to the initial image and to the encoded landmarks. During decoding, we add style features generated from the noise and reconstruct the initial image by the generative adversarial network (GAN) with transposed convolutions modulated by this style. We demonstrate the effectiveness of the approach both in unsupervised and in semi-supervised training scenarios using the 300-W and the CelebA datasets. The proposed regularization paradigm is shown to prevent overfitting, and the detection quality is shown to improve beyond the supervised outcome.