 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAME: Flexible LLM-Assisted Moderation Engine
Feb 13, 2025The rapid advancement of Large Language Models (LLMs) has introduced significant challenges in moderating user-model interactions. While LLMs demonstrate remarkable capabilities, they remain vulnerable to adversarial attacks, particularly ``jailbreaking'' techniques that bypass content safety measures. Current content moderation systems, which primarily rely on input prompt filtering, have proven insufficient, with techniques like Best-of-N (BoN) jailbreaking achieving success rates of 80% or more against popular LLMs. In this paper, we introduce Flexible LLM-Assisted Moderation Engine (FLAME): a new approach that shifts the focus from input filtering to output moderation. Unlike traditional circuit-breaking methods that analyze user queries, FLAME evaluates model responses, offering several key advantages: (1) computational efficiency in both training and inference, (2) enhanced resistance to BoN jailbreaking attacks, and (3) flexibility in defining and updating safety criteria through customizable topic filtering. Our experiments demonstrate that FLAME significantly outperforms current moderation systems. For example, FLAME reduces attack success rate in GPT-4o-mini and DeepSeek-v3 by a factor of ~9, while maintaining low computational overhead. We provide comprehensive evaluation on various LLMs and analyze the engine's efficiency against the state-of-the-art jailbreaking. This work contributes to the development of more robust and adaptable content moderation systems for LLMs.
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022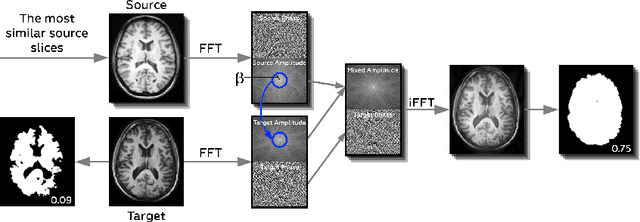

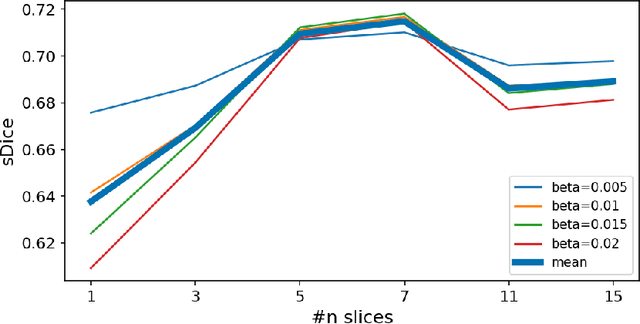

Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.