 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonwalk: Inverse-Forward Differentiation
Feb 22, 2024Backpropagation, while effective for gradient computation, falls short in addressing memory consumption, limiting scalability. This work explores forward-mode gradient computation as an alternative in invertible networks, showing its potential to reduce the memory footprint without substantial drawbacks. We introduce a novel technique based on a vector-inverse-Jacobian product that accelerates the computation of forward gradients while retaining the advantages of memory reduction and preserving the fidelity of true gradients. Our method, Moonwalk, has a time complexity linear in the depth of the network, unlike the quadratic time complexity of na\"ive forward, and empirically reduces computation time by several orders of magnitude without allocating more memory. We further accelerate Moonwalk by combining it with reverse-mode differentiation to achieve time complexity comparable with backpropagation while maintaining a much smaller memory footprint. Finally, we showcase the robustness of our method across several architecture choices. Moonwalk is the first forward-based method to compute true gradients in invertible networks in computation time comparable to backpropagation and using significantly less memory.
Align Your Intents: Offline Imitation Learning via Optimal Transport
Feb 20, 2024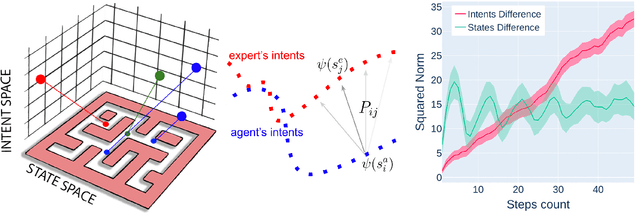



Offline reinforcement learning (RL) addresses the problem of sequential decision-making by learning optimal policy through pre-collected data, without interacting with the environment. As yet, it has remained somewhat impractical, because one rarely knows the reward explicitly and it is hard to distill it retrospectively. Here, we show that an imitating agent can still learn the desired behavior merely from observing the expert, despite the absence of explicit rewards or action labels. In our method, AILOT (Aligned Imitation Learning via Optimal Transport), we involve special representation of states in a form of intents that incorporate pairwise spatial distances within the data. Given such representations, we define intrinsic reward function via optimal transport distance between the expert's and the agent's trajectories. We report that AILOT outperforms state-of-the art offline imitation learning algorithms on D4RL benchmarks and improves the performance of other offline RL algorithms in the sparse-reward tasks.
Learning to Design Analog Circuits to Meet Threshold Specifications
Jul 25, 2023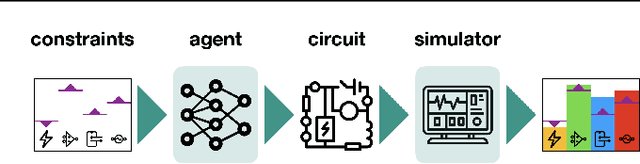

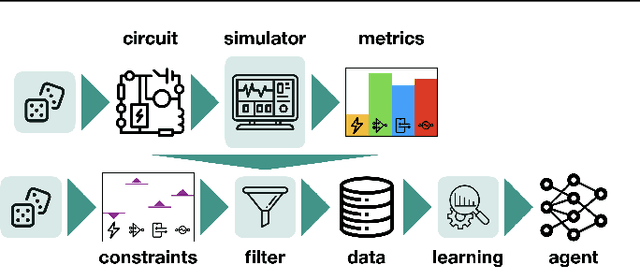

Automated design of analog and radio-frequency circuits using supervised or reinforcement learning from simulation data has recently been studied as an alternative to manual expert design. It is straightforward for a design agent to learn an inverse function from desired performance metrics to circuit parameters. However, it is more common for a user to have threshold performance criteria rather than an exact target vector of feasible performance measures. In this work, we propose a method for generating from simulation data a dataset on which a system can be trained via supervised learning to design circuits to meet threshold specifications. We moreover perform the to-date most extensive evaluation of automated analog circuit design, including experimenting in a significantly more diverse set of circuits than in prior work, covering linear, nonlinear, and autonomous circuit configurations, and show that our method consistently reaches success rate better than 90% at 5% error margin, while also improving data efficiency by upward of an order of magnitude. A demo of this system is available at circuits.streamlit.app
Reinforcement Learning Framework for Deep Brain Stimulation Study
Feb 22, 2020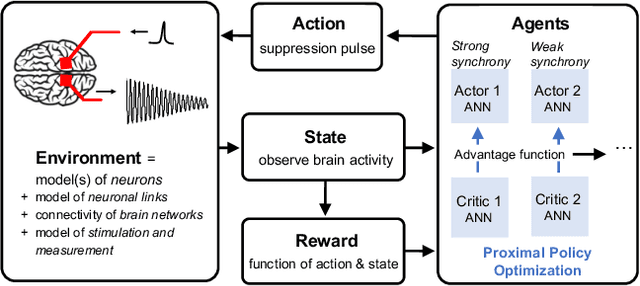
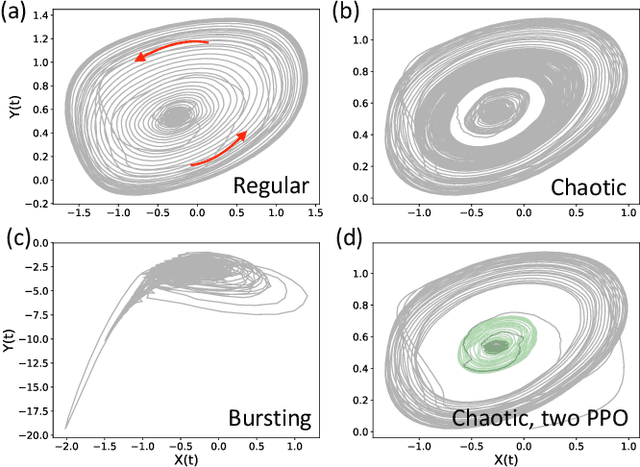
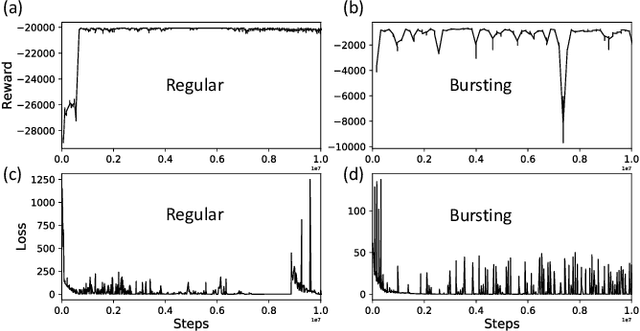
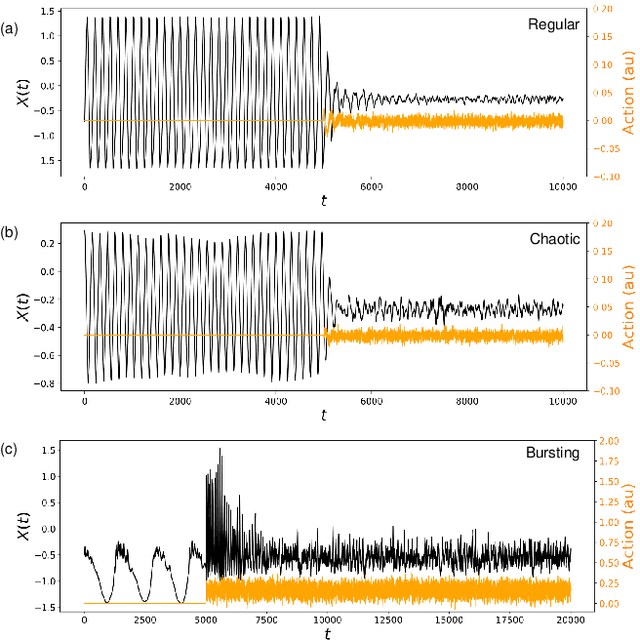
Malfunctioning neurons in the brain sometimes operate synchronously, reportedly causing many neurological diseases, e.g. Parkinson's. Suppression and control of this collective synchronous activity are therefore of great importance for neuroscience, and can only rely on limited engineering trials due to the need to experiment with live human brains. We present the first Reinforcement Learning gym framework that emulates this collective behavior of neurons and allows us to find suppression parameters for the environment of synthetic degenerate models of neurons. We successfully suppress synchrony via RL for three pathological signaling regimes, characterize the framework's stability to noise, and further remove the unwanted oscillations by engaging multiple PPO agents.