 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Policy Gradient Theorem for Efficient Policy Updates in Actor-Critic Algorithms
Feb 15, 2022

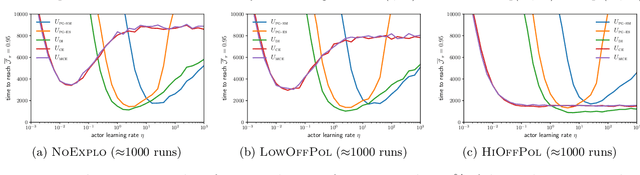
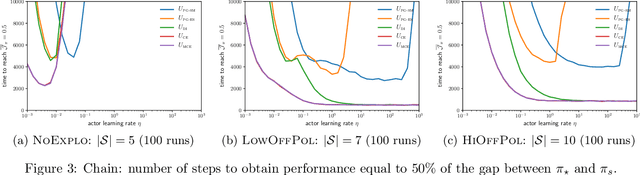
In Reinforcement Learning, the optimal action at a given state is dependent on policy decisions at subsequent states. As a consequence, the learning targets evolve with time and the policy optimization process must be efficient at unlearning what it previously learnt. In this paper, we discover that the policy gradient theorem prescribes policy updates that are slow to unlearn because of their structural symmetry with respect to the value target. To increase the unlearning speed, we study a novel policy update: the gradient of the cross-entropy loss with respect to the action maximizing $q$, but find that such updates may lead to a decrease in value. Consequently, we introduce a modified policy update devoid of that flaw, and prove its guarantees of convergence to global optimality in $\mathcal{O}(t^{-1})$ under classic assumptions. Further, we assess standard policy updates and our cross-entropy policy updates along six analytical dimensions. Finally, we empirically validate our theoretical findings.
On the Chattering of SARSA with Linear Function Approximation
Feb 14, 2022



SARSA, a classical on-policy control algorithm for reinforcement learning, is known to chatter when combined with linear function approximation: SARSA does not diverge but oscillates in a bounded region. However, little is know about how fast SARSA converges to that region and how large the region is. In this paper, we make progress towards solving this open problem by showing the convergence rate of projected SARSA to a bounded region. Importantly, the region is much smaller than the ball used for projection provided that the the magnitude of the reward is not too large. Our analysis applies to expected SARSA as well as SARSA($\lambda$). Existing works regarding the convergence of linear SARSA to a fixed point all require the Lipschitz constant of SARSA's policy improvement operator to be sufficiently small; our analysis instead applies to arbitrary Lipschitz constants and thus characterizes the behavior of linear SARSA for a new regime.
Global Optimality and Finite Sample Analysis of Softmax Off-Policy Actor Critic under State Distribution Mismatch
Nov 04, 2021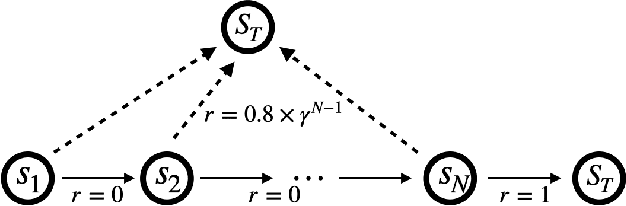
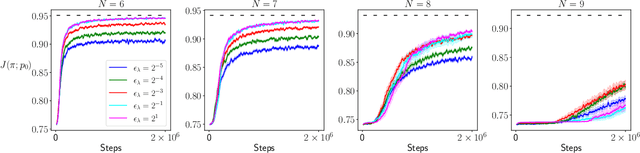
In this paper, we establish the global optimality and convergence rate of an off-policy actor critic algorithm in the tabular setting without using density ratio to correct the discrepancy between the state distribution of the behavior policy and that of the target policy. Our work goes beyond existing works on the optimality of policy gradient methods in that existing works use the exact policy gradient for updating the policy parameters while we use an approximate and stochastic update step. Our update step is not a gradient update because we do not use a density ratio to correct the state distribution, which aligns well with what practitioners do. Our update is approximate because we use a learned critic instead of the true value function. Our update is stochastic because at each step the update is done for only the current state action pair. Moreover, we remove several restrictive assumptions from existing works in our analysis. Central to our work is the finite sample analysis of a generic stochastic approximation algorithm with time-inhomogeneous update operators on time-inhomogeneous Markov chains, based on its uniform contraction properties.
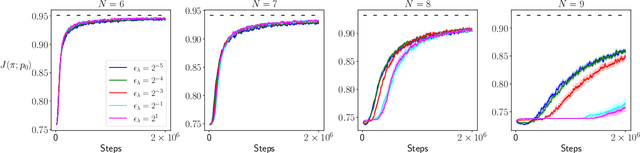
Dr Jekyll and Mr Hyde: the Strange Case of Off-Policy Policy Updates
Sep 29, 2021

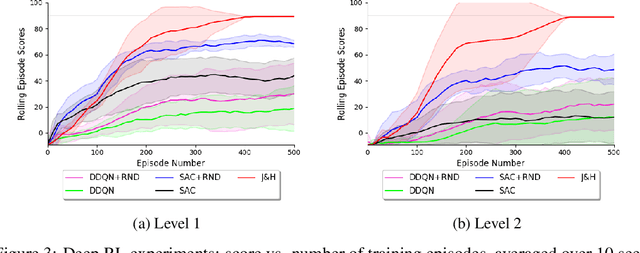

The policy gradient theorem states that the policy should only be updated in states that are visited by the current policy, which leads to insufficient planning in the off-policy states, and thus to convergence to suboptimal policies. We tackle this planning issue by extending the policy gradient theory to policy updates with respect to any state density. Under these generalized policy updates, we show convergence to optimality under a necessary and sufficient condition on the updates' state densities, and thereby solve the aforementioned planning issue. We also prove asymptotic convergence rates that significantly improve those in the policy gradient literature. To implement the principles prescribed by our theory, we propose an agent, Dr Jekyll & Mr Hyde (JH), with a double personality: Dr Jekyll purely exploits while Mr Hyde purely explores. JH's independent policies allow to record two separate replay buffers: one on-policy (Dr Jekyll's) and one off-policy (Mr Hyde's), and therefore to update JH's models with a mixture of on-policy and off-policy updates. More than an algorithm, JH defines principles for actor-critic algorithms to satisfy the requirements we identify in our analysis. We extensively test on finite MDPs where JH demonstrates a superior ability to recover from converging to a suboptimal policy without impairing its speed of convergence. We also implement a deep version of the algorithm and test it on a simple problem where it shows promising results.
Decomposed Mutual Information Estimation for Contrastive Representation Learning
Jun 25, 2021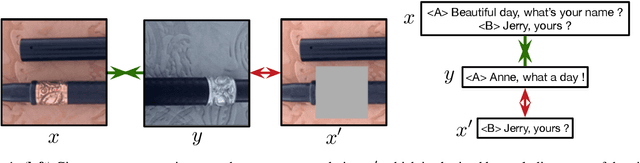

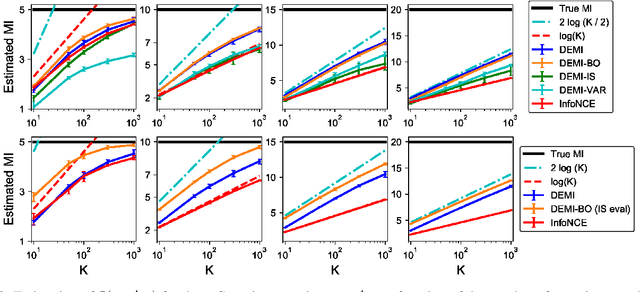
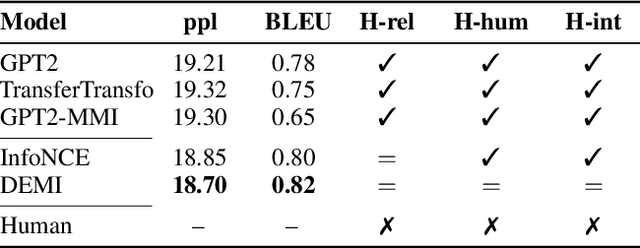
Recent contrastive representation learning methods rely on estimating mutual information (MI) between multiple views of an underlying context. E.g., we can derive multiple views of a given image by applying data augmentation, or we can split a sequence into views comprising the past and future of some step in the sequence. Contrastive lower bounds on MI are easy to optimize, but have a strong underestimation bias when estimating large amounts of MI. We propose decomposing the full MI estimation problem into a sum of smaller estimation problems by splitting one of the views into progressively more informed subviews and by applying the chain rule on MI between the decomposed views. This expression contains a sum of unconditional and conditional MI terms, each measuring modest chunks of the total MI, which facilitates approximation via contrastive bounds. To maximize the sum, we formulate a contrastive lower bound on the conditional MI which can be approximated efficiently. We refer to our general approach as Decomposed Estimation of Mutual Information (DEMI). We show that DEMI can capture a larger amount of MI than standard non-decomposed contrastive bounds in a synthetic setting, and learns better representations in a vision domain and for dialogue generation.
Reinforcement Learning Framework for Deep Brain Stimulation Study
Feb 22, 2020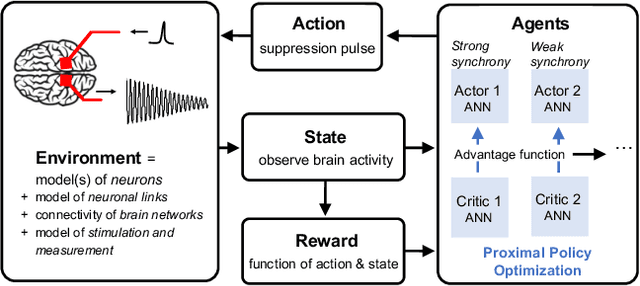
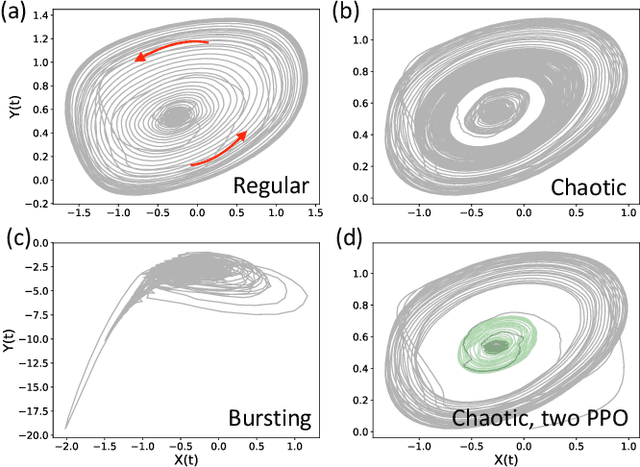
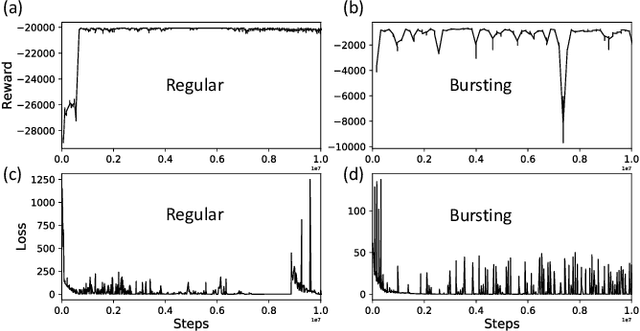
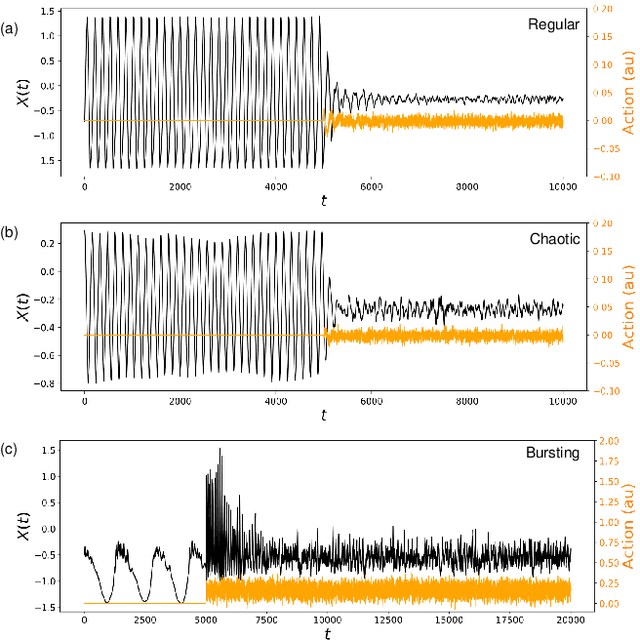
Malfunctioning neurons in the brain sometimes operate synchronously, reportedly causing many neurological diseases, e.g. Parkinson's. Suppression and control of this collective synchronous activity are therefore of great importance for neuroscience, and can only rely on limited engineering trials due to the need to experiment with live human brains. We present the first Reinforcement Learning gym framework that emulates this collective behavior of neurons and allows us to find suppression parameters for the environment of synthetic degenerate models of neurons. We successfully suppress synchrony via RL for three pathological signaling regimes, characterize the framework's stability to noise, and further remove the unwanted oscillations by engaging multiple PPO agents.
Robust Natural Language Inference Models with Example Forgetting
Nov 10, 2019
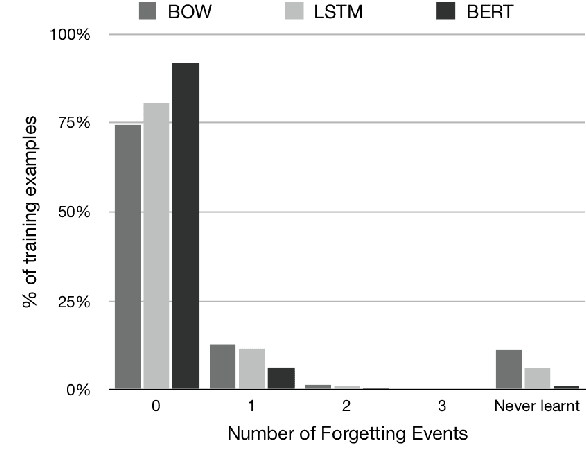

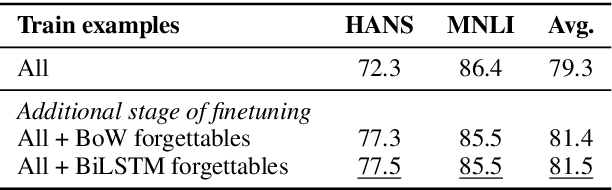
We investigate whether example forgetting, a recently introduced measure of hardness of examples, can be used to select training examples in order to increase robustness of natural language understanding models in a natural language inference task (MNLI). We analyze forgetting events for MNLI and provide evidence that forgettable examples under simpler models can be used to increase robustness of the recently proposed BERT model, measured by testing an MNLI trained model on HANS, a curated test set that exhibits a shift in distribution compared to the MNLI test set. Moreover, we show that, the "large" version of BERT is more robust than its "base" version but its robustness can still be improved with our approach.