Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Natural Language Inference Models with Example Forgetting
Nov 10, 2019
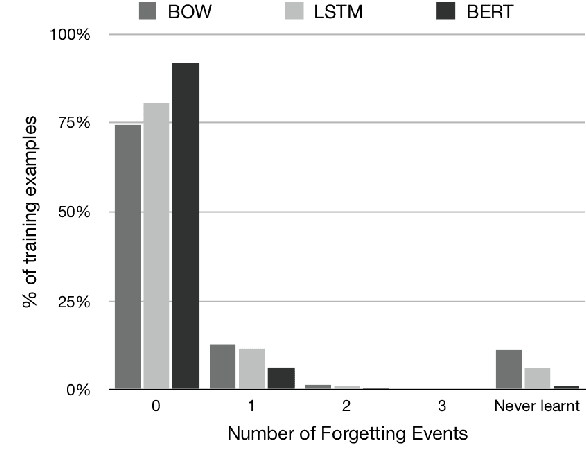

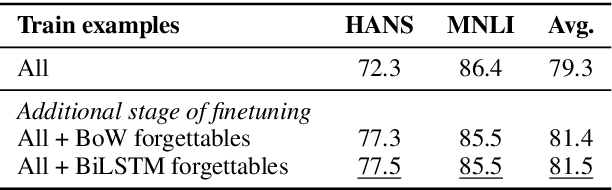
We investigate whether example forgetting, a recently introduced measure of hardness of examples, can be used to select training examples in order to increase robustness of natural language understanding models in a natural language inference task (MNLI). We analyze forgetting events for MNLI and provide evidence that forgettable examples under simpler models can be used to increase robustness of the recently proposed BERT model, measured by testing an MNLI trained model on HANS, a curated test set that exhibits a shift in distribution compared to the MNLI test set. Moreover, we show that, the "large" version of BERT is more robust than its "base" version but its robustness can still be improved with our approach.
Via