 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Document Packing on the Latent Multi-Hop Reasoning Capabilities of Large Language Models
Dec 16, 2025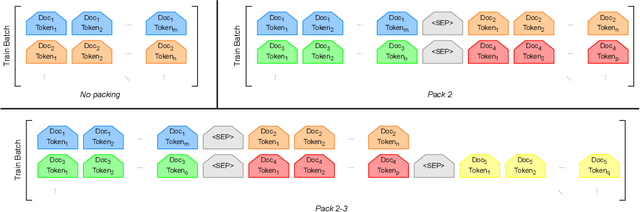
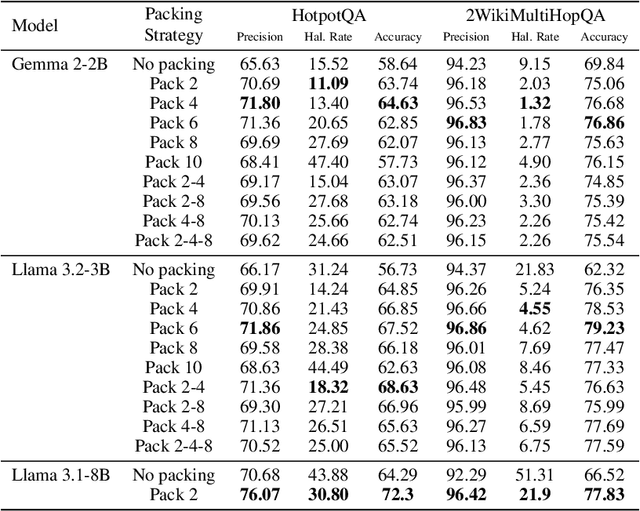


The standard practice for training large language models involves packing multiple documents together to optimize computational efficiency. However, the impact of this process on the models' capabilities remains largely unexplored. To address this gap, we investigate how different document-packing strategies influence the latent multi-hop reasoning abilities of LLMs. Our findings indicate that packing can improve model performance compared to training on individual documents, at the expense of more compute. To further understand the underlying mechanisms, we conduct an ablation study, identifying key factors that explain the advantages of packing. Ultimately, our research deepens the understanding of LLM training dynamics and provides practical insights for optimizing model development.
Learning to Extract Context for Context-Aware LLM Inference
Dec 12, 2025User prompts to large language models (LLMs) are often ambiguous or under-specified, and subtle contextual cues shaped by user intentions, prior knowledge, and risk factors strongly influence what constitutes an appropriate response. Misinterpreting intent or risks may lead to unsafe outputs, while overly cautious interpretations can cause unnecessary refusal of benign requests. In this paper, we question the conventional framework in which LLMs generate immediate responses to requests without considering broader contextual factors. User requests are situated within broader contexts such as intentions, knowledge, and prior experience, which strongly influence what constitutes an appropriate answer. We propose a framework that extracts and leverages such contextual information from the user prompt itself. Specifically, a reinforcement learning based context generator, designed in an autoencoder-like fashion, is trained to infer contextual signals grounded in the prompt and use them to guide response generation. This approach is particularly important for safety tasks, where ambiguous requests may bypass safeguards while benign but confusing requests can trigger unnecessary refusals. Experiments show that our method reduces harmful responses by an average of 5.6% on the SafetyInstruct dataset across multiple foundation models and improves the harmonic mean of attack success rate and compliance on benign prompts by 6.2% on XSTest and WildJailbreak. These results demonstrate the effectiveness of context extraction for safer and more reliable LLM inferences.
Gistify! Codebase-Level Understanding via Runtime Execution
Oct 30, 2025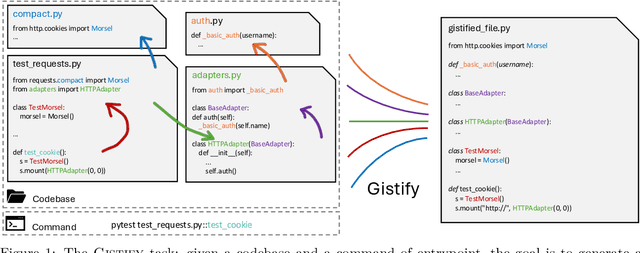
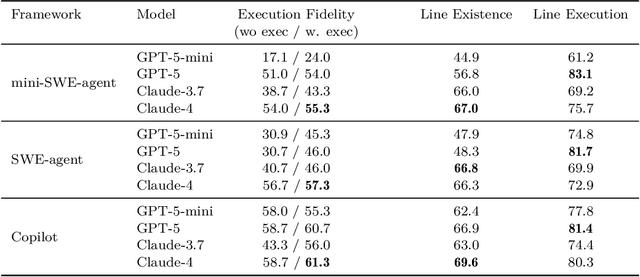

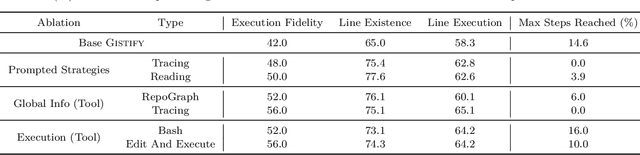
As coding agents are increasingly deployed in large codebases, the need to automatically design challenging, codebase-level evaluation is central. We propose Gistify, a task where a coding LLM must create a single, minimal, self-contained file that can reproduce a specific functionality of a codebase. The coding LLM is given full access to a codebase along with a specific entrypoint (e.g., a python command), and the generated file must replicate the output of the same command ran under the full codebase, while containing only the essential components necessary to execute the provided command. Success on Gistify requires both structural understanding of the codebase, accurate modeling of its execution flow as well as the ability to produce potentially large code patches. Our findings show that current state-of-the-art models struggle to reliably solve Gistify tasks, especially ones with long executions traces.
Medical Red Teaming Protocol of Language Models: On the Importance of User Perspectives in Healthcare Settings
Jul 09, 2025As the performance of large language models (LLMs) continues to advance, their adoption is expanding across a wide range of domains, including the medical field. The integration of LLMs into medical applications raises critical safety concerns, particularly due to their use by users with diverse roles, e.g. patients and clinicians, and the potential for model's outputs to directly affect human health. Despite the domain-specific capabilities of medical LLMs, prior safety evaluations have largely focused only on general safety benchmarks. In this paper, we introduce a safety evaluation protocol tailored to the medical domain in both patient user and clinician user perspectives, alongside general safety assessments and quantitatively analyze the safety of medical LLMs. We bridge a gap in the literature by building the PatientSafetyBench containing 466 samples over 5 critical categories to measure safety from the perspective of the patient. We apply our red-teaming protocols on the MediPhi model collection as a case study. To our knowledge, this is the first work to define safety evaluation criteria for medical LLMs through targeted red-teaming taking three different points of view - patient, clinician, and general user - establishing a foundation for safer deployment in medical domains.
A Modular Approach for Clinical SLMs Driven by Synthetic Data with Pre-Instruction Tuning, Model Merging, and Clinical-Tasks Alignment
May 15, 2025High computation costs and latency of large language models such as GPT-4 have limited their deployment in clinical settings. Small language models (SLMs) offer a cost-effective alternative, but their limited capacity requires biomedical domain adaptation, which remains challenging. An additional bottleneck is the unavailability and high sensitivity of clinical data. To address these challenges, we propose a novel framework for adapting SLMs into high-performing clinical models. We introduce the MediPhi collection of 3.8B-parameter SLMs developed with our novel framework: pre-instruction tuning of experts on relevant medical and clinical corpora (PMC, Medical Guideline, MedWiki, etc.), model merging, and clinical-tasks alignment. To cover most clinical tasks, we extended the CLUE benchmark to CLUE+, doubling its size. Our expert models deliver relative improvements on this benchmark over the base model without any task-specific fine-tuning: 64.3% on medical entities, 49.5% on radiology reports, and 44% on ICD-10 coding (outperforming GPT-4-0125 by 14%). We unify the expert models into MediPhi via model merging, preserving gains across benchmarks. Furthermore, we built the MediFlow collection, a synthetic dataset of 2.5 million high-quality instructions on 14 medical NLP tasks, 98 fine-grained document types, and JSON format support. Alignment of MediPhi using supervised fine-tuning and direct preference optimization achieves further gains of 18.9% on average.
Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
May 07, 2025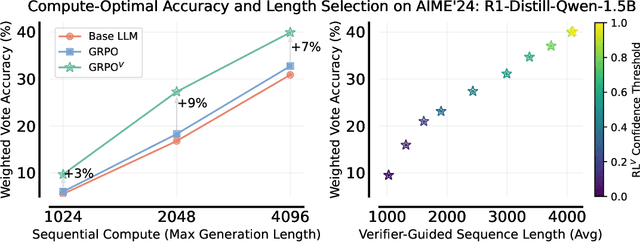
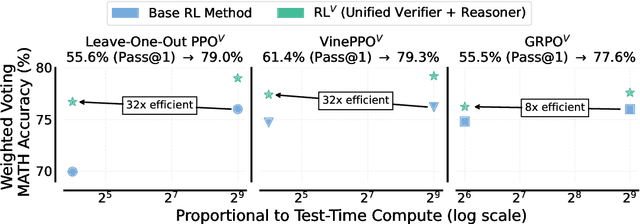
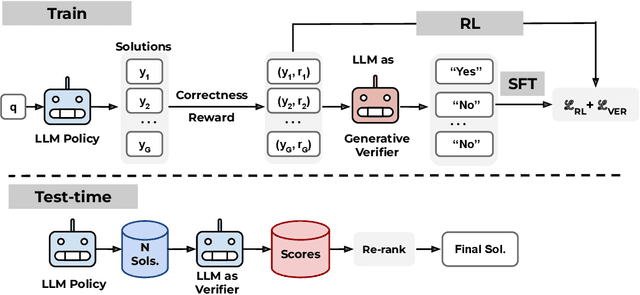
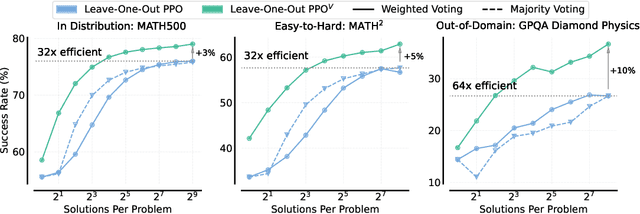
Prevalent reinforcement learning~(RL) methods for fine-tuning LLM reasoners, such as GRPO or Leave-one-out PPO, abandon the learned value function in favor of empirically estimated returns. This hinders test-time compute scaling that relies on using the value-function for verification. In this work, we propose RL$^V$ that augments any ``value-free'' RL method by jointly training the LLM as both a reasoner and a generative verifier using RL-generated data, adding verification capabilities without significant overhead. Empirically, RL$^V$ boosts MATH accuracy by over 20\% with parallel sampling and enables $8-32\times$ efficient test-time compute scaling compared to the base RL method. RL$^V$ also exhibits strong generalization capabilities for both easy-to-hard and out-of-domain tasks. Furthermore, RL$^V$ achieves $1.2-1.6\times$ higher performance when jointly scaling parallel and sequential test-time compute with a long reasoning R1 model.
debug-gym: A Text-Based Environment for Interactive Debugging
Mar 27, 2025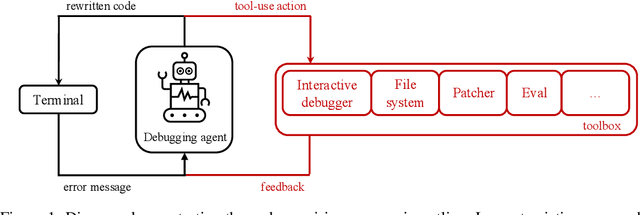
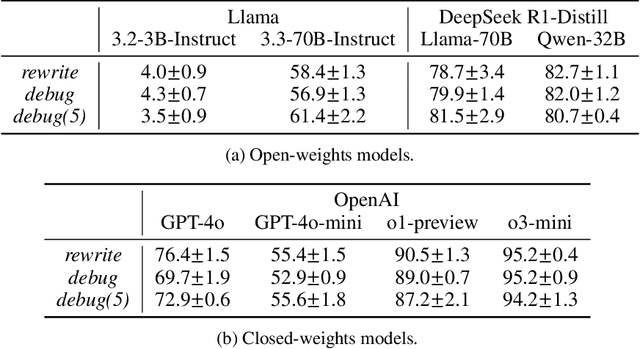
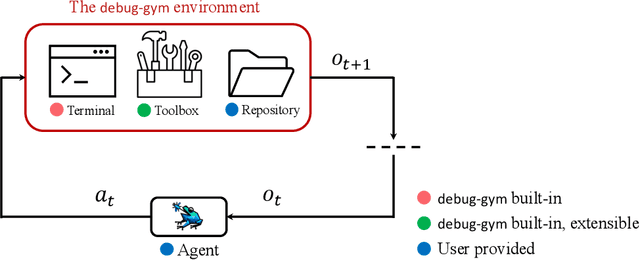
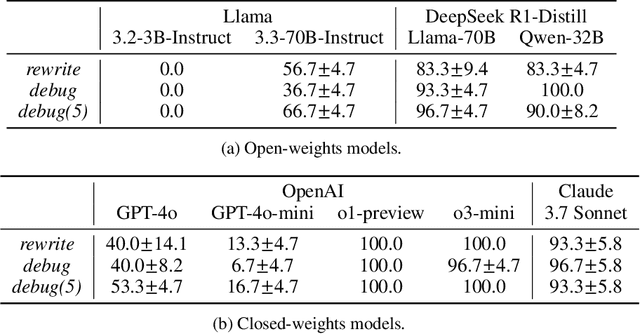
Large Language Models (LLMs) are increasingly relied upon for coding tasks, yet in most scenarios it is assumed that all relevant information can be either accessed in context or matches their training data. We posit that LLMs can benefit from the ability to interactively explore a codebase to gather the information relevant to their task. To achieve this, we present a textual environment, namely debug-gym, for developing LLM-based agents in an interactive coding setting. Our environment is lightweight and provides a preset of useful tools, such as a Python debugger (pdb), designed to facilitate an LLM-based agent's interactive debugging. Beyond coding and debugging tasks, this approach can be generalized to other tasks that would benefit from information-seeking behavior by an LLM agent.
Training Plug-n-Play Knowledge Modules with Deep Context Distillation
Mar 11, 2025Dynamically integrating new or rapidly evolving information after (Large) Language Model pre-training remains challenging, particularly in low-data scenarios or when dealing with private and specialized documents. In-context learning and retrieval-augmented generation (RAG) face limitations, including their high inference costs and their inability to capture global document information. In this paper, we propose a way of modularizing knowledge by training document-level Knowledge Modules (KMs). KMs are lightweight components implemented as parameter-efficient LoRA modules, which are trained to store information about new documents and can be easily plugged into models on demand. We show that next-token prediction performs poorly as the training objective for KMs. We instead propose Deep Context Distillation: we learn KMs parameters such as to simulate hidden states and logits of a teacher that takes the document in context. Our method outperforms standard next-token prediction and pre-instruction training techniques, across two datasets. Finally, we highlight synergies between KMs and retrieval-augmented generation.
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
Oct 02, 2024



Large language models (LLMs) are increasingly applied to complex reasoning tasks that require executing several complex steps before receiving any reward. Properly assigning credit to these steps is essential for enhancing model performance. Proximal Policy Optimization (PPO), a state-of-the-art reinforcement learning (RL) algorithm used for LLM finetuning, employs value networks to tackle credit assignment. However, value networks face challenges in predicting the expected cumulative rewards accurately in complex reasoning tasks, often leading to high-variance updates and suboptimal performance. In this work, we systematically evaluate the efficacy of value networks and reveal their significant shortcomings in reasoning-heavy LLM tasks, showing that they barely outperform a random baseline when comparing alternative steps. To address this, we propose VinePPO, a straightforward approach that leverages the flexibility of language environments to compute unbiased Monte Carlo-based estimates, bypassing the need for large value networks. Our method consistently outperforms PPO and other RL-free baselines across MATH and GSM8K datasets with fewer gradient updates (up to 9x), less wall-clock time (up to 3.0x). These results emphasize the importance of accurate credit assignment in RL finetuning of LLM and demonstrate VinePPO's potential as a superior alternative.
Not All LLM Reasoners Are Created Equal
Oct 02, 2024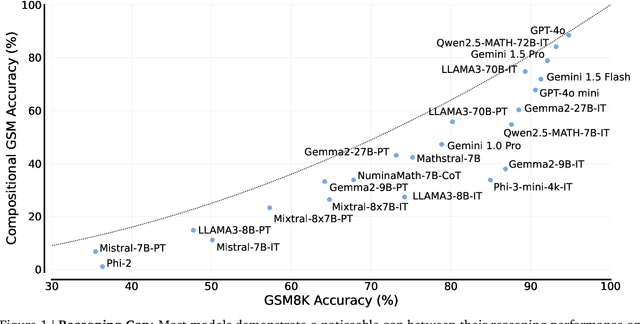
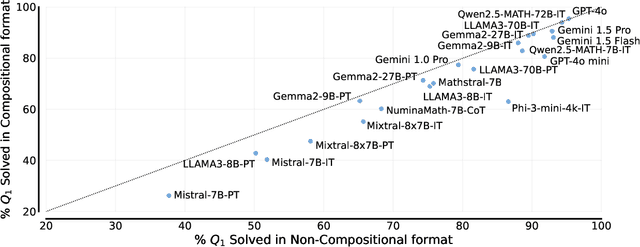
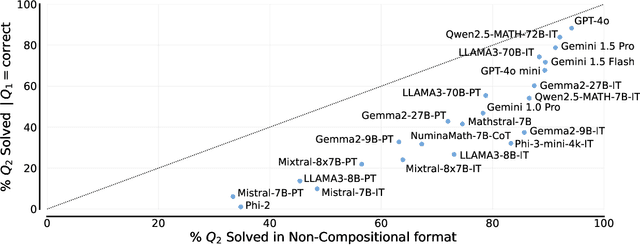
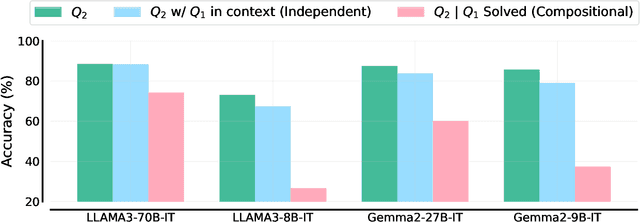
We study the depth of grade-school math (GSM) problem-solving capabilities of LLMs. To this end, we evaluate their performance on pairs of existing math word problems together so that the answer to the second problem depends on correctly answering the first problem. Our findings reveal a significant reasoning gap in most LLMs, that is performance difference between solving the compositional pairs and solving each question independently. This gap is more pronounced in smaller, more cost-efficient, and math-specialized models. Moreover, instruction-tuning recipes and code generation have varying effects across LLM sizes, while finetuning on GSM can lead to task overfitting. Our analysis indicates that large reasoning gaps are not because of test-set leakage, but due to distraction from additional context and poor second-hop reasoning. Overall, LLMs exhibit systematic differences in their reasoning abilities, despite what their performance on standard benchmarks indicates.