 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
Apr 11, 2025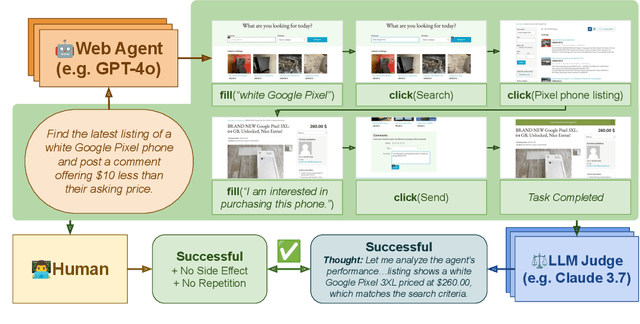
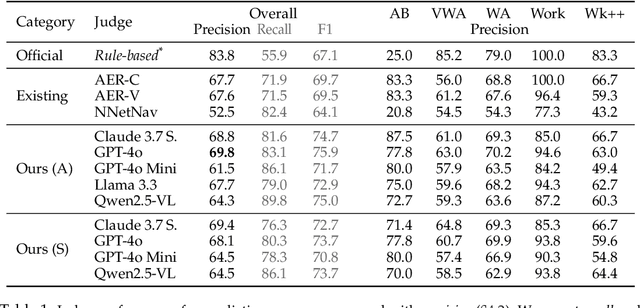
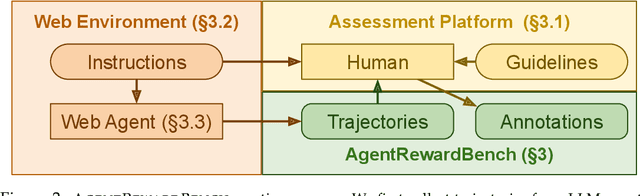
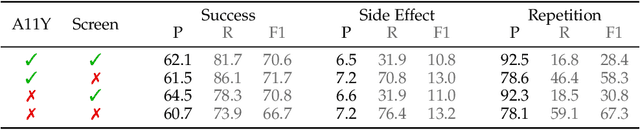
Web agents enable users to perform tasks on web browsers through natural language interaction. Evaluating web agents trajectories is an important problem, since it helps us determine whether the agent successfully completed the tasks. Rule-based methods are widely used for this purpose, but they are challenging to extend to new tasks and may not always recognize successful trajectories. We may achieve higher accuracy through human evaluation, but the process would be substantially slower and more expensive. Automatic evaluations with LLMs may avoid the challenges of designing new rules and manually annotating trajectories, enabling faster and cost-effective evaluation. However, it is unclear how effective they are at evaluating web agents. To this end, we propose AgentRewardBench, the first benchmark to assess the effectiveness of LLM judges for evaluating web agents. AgentRewardBench contains 1302 trajectories across 5 benchmarks and 4 LLMs. Each trajectory in AgentRewardBench is reviewed by an expert, who answers questions pertaining to the success, side effects, and repetitiveness of the agent. Using our benchmark, we evaluate 12 LLM judges and find that no single LLM excels across all benchmarks. We also find that the rule-based evaluation used by common benchmarks tends to underreport the success rate of web agents, highlighting a key weakness of rule-based evaluation and the need to develop more flexible automatic evaluations. We release the benchmark at: https://agent-reward-bench.github.io
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
Oct 02, 2024



Large language models (LLMs) are increasingly applied to complex reasoning tasks that require executing several complex steps before receiving any reward. Properly assigning credit to these steps is essential for enhancing model performance. Proximal Policy Optimization (PPO), a state-of-the-art reinforcement learning (RL) algorithm used for LLM finetuning, employs value networks to tackle credit assignment. However, value networks face challenges in predicting the expected cumulative rewards accurately in complex reasoning tasks, often leading to high-variance updates and suboptimal performance. In this work, we systematically evaluate the efficacy of value networks and reveal their significant shortcomings in reasoning-heavy LLM tasks, showing that they barely outperform a random baseline when comparing alternative steps. To address this, we propose VinePPO, a straightforward approach that leverages the flexibility of language environments to compute unbiased Monte Carlo-based estimates, bypassing the need for large value networks. Our method consistently outperforms PPO and other RL-free baselines across MATH and GSM8K datasets with fewer gradient updates (up to 9x), less wall-clock time (up to 3.0x). These results emphasize the importance of accurate credit assignment in RL finetuning of LLM and demonstrate VinePPO's potential as a superior alternative.
The Impact of Positional Encoding on Length Generalization in Transformers
May 31, 2023



Length generalization, the ability to generalize from small training context sizes to larger ones, is a critical challenge in the development of Transformer-based language models. Positional encoding (PE) has been identified as a major factor influencing length generalization, but the exact impact of different PE schemes on extrapolation in downstream tasks remains unclear. In this paper, we conduct a systematic empirical study comparing the length generalization performance of decoder-only Transformers with five different position encoding approaches including Absolute Position Embedding (APE), T5's Relative PE, ALiBi, and Rotary, in addition to Transformers without positional encoding (NoPE). Our evaluation encompasses a battery of reasoning and mathematical tasks. Our findings reveal that the most commonly used positional encoding methods, such as ALiBi, Rotary, and APE, are not well suited for length generalization in downstream tasks. More importantly, NoPE outperforms other explicit positional encoding methods while requiring no additional computation. We theoretically demonstrate that NoPE can represent both absolute and relative PEs, but when trained with SGD, it mostly resembles T5's relative PE attention patterns. Finally, we find that scratchpad is not always helpful to solve length generalization and its format highly impacts the model's performance. Overall, our work suggests that explicit position embeddings are not essential for decoder-only Transformers to generalize well to longer sequences.
Measuring the Knowledge Acquisition-Utilization Gap in Pretrained Language Models
May 24, 2023While pre-trained language models (PLMs) have shown evidence of acquiring vast amounts of knowledge, it remains unclear how much of this parametric knowledge is actually usable in performing downstream tasks. We propose a systematic framework to measure parametric knowledge utilization in PLMs. Our framework first extracts knowledge from a PLM's parameters and subsequently constructs a downstream task around this extracted knowledge. Performance on this task thus depends exclusively on utilizing the model's possessed knowledge, avoiding confounding factors like insufficient signal. As an instantiation, we study factual knowledge of PLMs and measure utilization across 125M to 13B parameter PLMs. We observe that: (1) PLMs exhibit two gaps - in acquired vs. utilized knowledge, (2) they show limited robustness in utilizing knowledge under distribution shifts, and (3) larger models close the acquired knowledge gap but the utilized knowledge gap remains. Overall, our study provides insights into PLMs' capabilities beyond their acquired knowledge.
The Curious Case of Absolute Position Embeddings
Oct 23, 2022



Transformer language models encode the notion of word order using positional information. Most commonly, this positional information is represented by absolute position embeddings (APEs), that are learned from the pretraining data. However, in natural language, it is not absolute position that matters, but relative position, and the extent to which APEs can capture this type of information has not been investigated. In this work, we observe that models trained with APE over-rely on positional information to the point that they break-down when subjected to sentences with shifted position information. Specifically, when models are subjected to sentences starting from a non-zero position (excluding the effect of priming), they exhibit noticeably degraded performance on zero to full-shot tasks, across a range of model families and model sizes. Our findings raise questions about the efficacy of APEs to model the relativity of position information, and invite further introspection on the sentence and word order processing strategies employed by these models.