 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories
Apr 11, 2025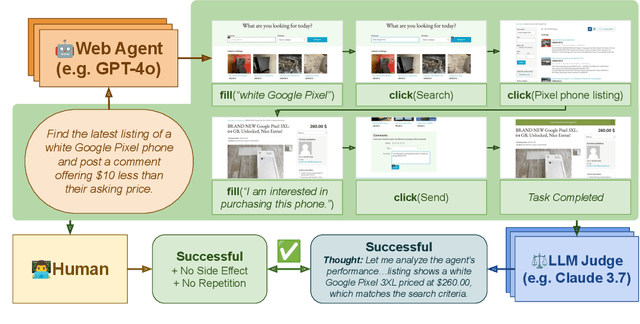
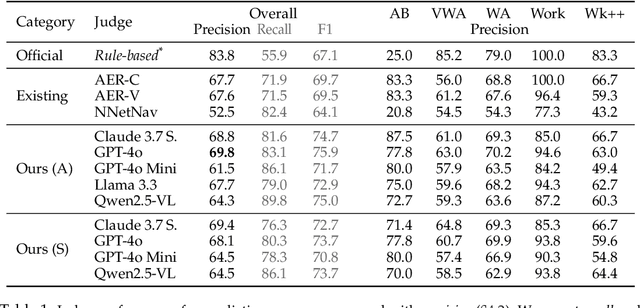
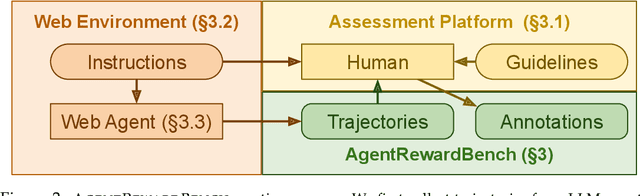
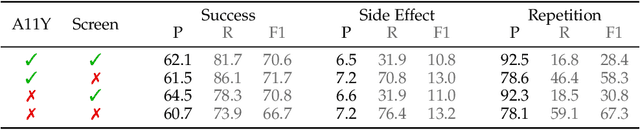
Web agents enable users to perform tasks on web browsers through natural language interaction. Evaluating web agents trajectories is an important problem, since it helps us determine whether the agent successfully completed the tasks. Rule-based methods are widely used for this purpose, but they are challenging to extend to new tasks and may not always recognize successful trajectories. We may achieve higher accuracy through human evaluation, but the process would be substantially slower and more expensive. Automatic evaluations with LLMs may avoid the challenges of designing new rules and manually annotating trajectories, enabling faster and cost-effective evaluation. However, it is unclear how effective they are at evaluating web agents. To this end, we propose AgentRewardBench, the first benchmark to assess the effectiveness of LLM judges for evaluating web agents. AgentRewardBench contains 1302 trajectories across 5 benchmarks and 4 LLMs. Each trajectory in AgentRewardBench is reviewed by an expert, who answers questions pertaining to the success, side effects, and repetitiveness of the agent. Using our benchmark, we evaluate 12 LLM judges and find that no single LLM excels across all benchmarks. We also find that the rule-based evaluation used by common benchmarks tends to underreport the success rate of web agents, highlighting a key weakness of rule-based evaluation and the need to develop more flexible automatic evaluations. We release the benchmark at: https://agent-reward-bench.github.io
Reducing Hallucinations in Language Model-based SPARQL Query Generation Using Post-Generation Memory Retrieval
Feb 19, 2025



The ability to generate SPARQL queries from natural language questions is crucial for ensuring efficient and accurate retrieval of structured data from knowledge graphs (KG). While large language models (LLMs) have been widely adopted for SPARQL query generation, they are often susceptible to hallucinations and out-of-distribution errors when producing KG elements like Uniform Resource Identifiers (URIs) based on internal parametric knowledge. This often results in content that appears plausible but is factually incorrect, posing significant challenges for their use in real-world information retrieval (IR) applications. This has led to increased research aimed at detecting and mitigating such errors. In this paper, we introduce PGMR (Post-Generation Memory Retrieval), a modular framework that incorporates a non-parametric memory module to retrieve KG elements and enhance LLM-based SPARQL query generation. Our experimental results indicate that PGMR consistently delivers strong performance across diverse datasets, data distributions, and LLMs. Notably, PGMR significantly mitigates URI hallucinations, nearly eliminating the problem in several scenarios.
GeoCoder: Solving Geometry Problems by Generating Modular Code through Vision-Language Models
Oct 17, 2024



Geometry problem-solving demands advanced reasoning abilities to process multimodal inputs and employ mathematical knowledge effectively. Vision-language models (VLMs) have made significant progress in various multimodal tasks. Yet, they still struggle with geometry problems and are significantly limited by their inability to perform mathematical operations not seen during pre-training, such as calculating the cosine of an arbitrary angle, and by difficulties in correctly applying relevant geometry formulas. To overcome these challenges, we present GeoCoder, which leverages modular code-finetuning to generate and execute code using a predefined geometry function library. By executing the code, we achieve accurate and deterministic calculations, contrasting the stochastic nature of autoregressive token prediction, while the function library minimizes errors in formula usage. We also propose a multimodal retrieval-augmented variant of GeoCoder, named RAG-GeoCoder, which incorporates a non-parametric memory module for retrieving functions from the geometry library, thereby reducing reliance on parametric memory. Our modular code-finetuning approach enhances the geometric reasoning capabilities of VLMs, yielding an average improvement of over 16% across various question complexities on the GeomVerse dataset compared to other finetuning methods.
Controllable Image Generation via Collage Representations
Apr 26, 2023Recent advances in conditional generative image models have enabled impressive results. On the one hand, text-based conditional models have achieved remarkable generation quality, by leveraging large-scale datasets of image-text pairs. To enable fine-grained controllability, however, text-based models require long prompts, whose details may be ignored by the model. On the other hand, layout-based conditional models have also witnessed significant advances. These models rely on bounding boxes or segmentation maps for precise spatial conditioning in combination with coarse semantic labels. The semantic labels, however, cannot be used to express detailed appearance characteristics. In this paper, we approach fine-grained scene controllability through image collages which allow a rich visual description of the desired scene as well as the appearance and location of the objects therein, without the need of class nor attribute labels. We introduce "mixing and matching scenes" (M&Ms), an approach that consists of an adversarially trained generative image model which is conditioned on appearance features and spatial positions of the different elements in a collage, and integrates these into a coherent image. We train our model on the OpenImages (OI) dataset and evaluate it on collages derived from OI and MS-COCO datasets. Our experiments on the OI dataset show that M&Ms outperforms baselines in terms of fine-grained scene controllability while being very competitive in terms of image quality and sample diversity. On the MS-COCO dataset, we highlight the generalization ability of our model by outperforming DALL-E in terms of the zero-shot FID metric, despite using two magnitudes fewer parameters and data. Collage based generative models have the potential to advance content creation in an efficient and effective way as they are intuitive to use and yield high quality generations.
Reinforced active learning for image segmentation
Feb 16, 2020
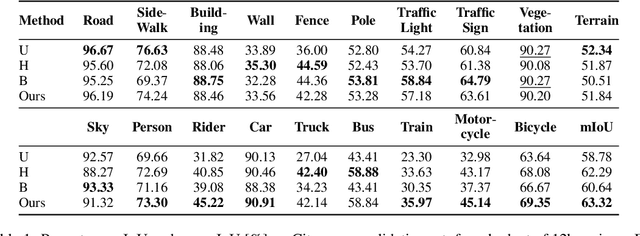


Learning-based approaches for semantic segmentation have two inherent challenges. First, acquiring pixel-wise labels is expensive and time-consuming. Second, realistic segmentation datasets are highly unbalanced: some categories are much more abundant than others, biasing the performance to the most represented ones. In this paper, we are interested in focusing human labelling effort on a small subset of a larger pool of data, minimizing this effort while maximizing performance of a segmentation model on a hold-out set. We present a new active learning strategy for semantic segmentation based on deep reinforcement learning (RL). An agent learns a policy to select a subset of small informative image regions -- opposed to entire images -- to be labeled, from a pool of unlabeled data. The region selection decision is made based on predictions and uncertainties of the segmentation model being trained. Our method proposes a new modification of the deep Q-network (DQN) formulation for active learning, adapting it to the large-scale nature of semantic segmentation problems. We test the proof of concept in CamVid and provide results in the large-scale dataset Cityscapes. On Cityscapes, our deep RL region-based DQN approach requires roughly 30% less additional labeled data than our most competitive baseline to reach the same performance. Moreover, we find that our method asks for more labels of under-represented categories compared to the baselines, improving their performance and helping to mitigate class imbalance.
Learning Sparse Mixture of Experts for Visual Question Answering
Sep 19, 2019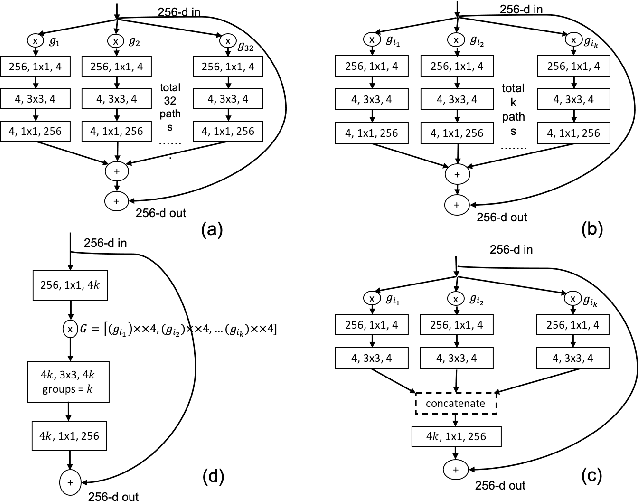
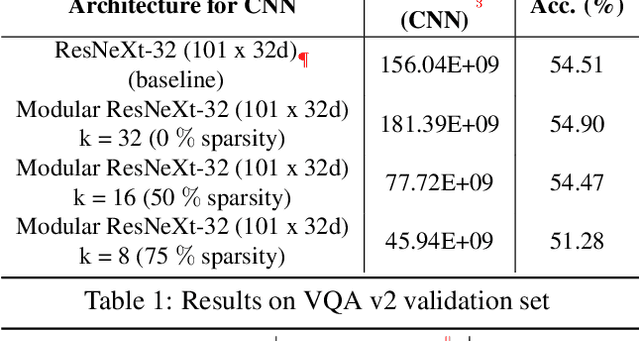

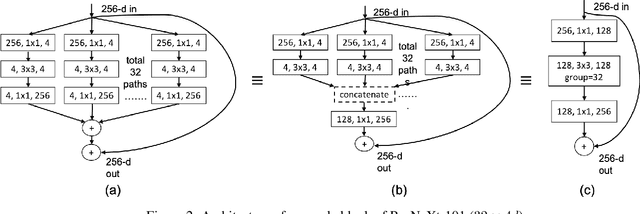
There has been a rapid progress in the task of Visual Question Answering with improved model architectures. Unfortunately, these models are usually computationally intensive due to their sheer size which poses a serious challenge for deployment. We aim to tackle this issue for the specific task of Visual Question Answering (VQA). A Convolutional Neural Network (CNN) is an integral part of the visual processing pipeline of a VQA model (assuming the CNN is trained along with entire VQA model). In this project, we propose an efficient and modular neural architecture for the VQA task with focus on the CNN module. Our experiments demonstrate that a sparsely activated CNN based VQA model achieves comparable performance to a standard CNN based VQA model architecture.
Structure Learning for Neural Module Networks
May 27, 2019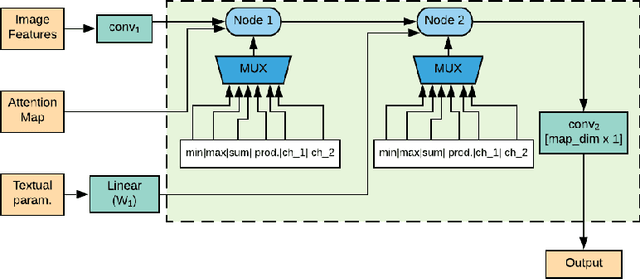
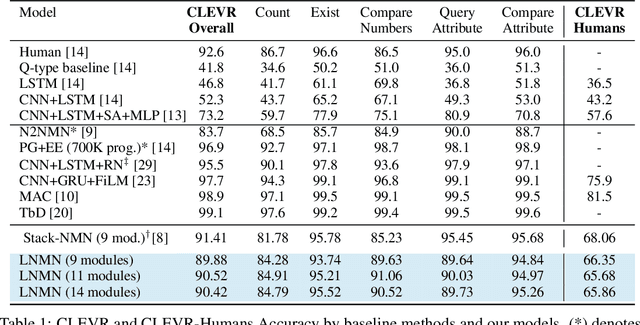
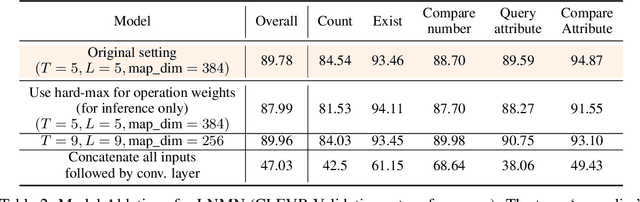
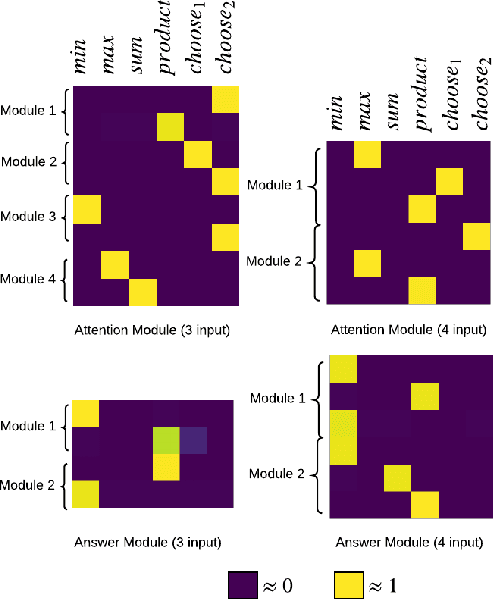
Neural Module Networks, originally proposed for the task of visual question answering, are a class of neural network architectures that involve human-specified neural modules, each designed for a specific form of reasoning. In current formulations of such networks only the parameters of the neural modules and/or the order of their execution is learned. In this work, we further expand this approach and also learn the underlying internal structure of modules in terms of the ordering and combination of simple and elementary arithmetic operators. Our results show that one is indeed able to simultaneously learn both internal module structure and module sequencing without extra supervisory signals for module execution sequencing. With this approach, we report performance comparable to models using hand-designed modules.
Active Domain Randomization
Apr 09, 2019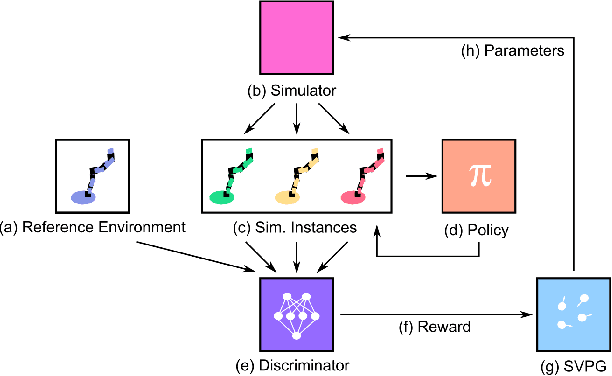

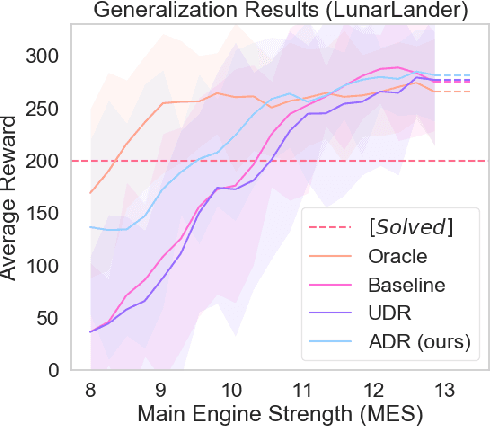
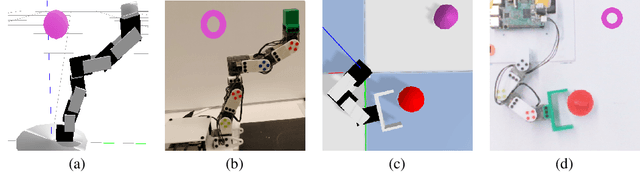
Domain randomization is a popular technique for improving domain transfer, often used in a zero-shot setting when the target domain is unknown or cannot easily be used for training. In this work, we empirically examine the effects of domain randomization on agent generalization. Our experiments show that domain randomization may lead to suboptimal, high-variance policies, which we attribute to the uniform sampling of environment parameters. We propose Active Domain Randomization, a novel algorithm that learns a parameter sampling strategy. Our method looks for the most informative environment variations within the given randomization ranges by leveraging the discrepancies of policy rollouts in randomized and reference environment instances. We find that training more frequently on these instances leads to better overall agent generalization. In addition, when domain randomization and policy transfer fail, Active Domain Randomization offers more insight into the deficiencies of both the chosen parameter ranges and the learned policy, allowing for more focused debugging. Our experiments across various physics-based simulated and a real-robot task show that this enhancement leads to more robust, consistent policies.
Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents
Apr 02, 2019
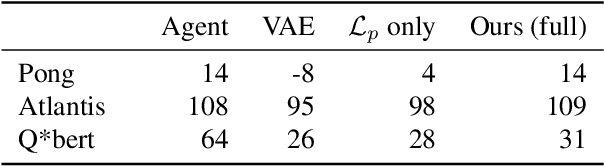


As deep reinforcement learning driven by visual perception becomes more widely used there is a growing need to better understand and probe the learned agents. Understanding the decision making process and its relationship to visual inputs can be very valuable to identify problems in learned behavior. However, this topic has been relatively under-explored in the research community. In this work we present a method for synthesizing visual inputs of interest for a trained agent. Such inputs or states could be situations in which specific actions are necessary. Further, critical states in which a very high or a very low reward can be achieved are often interesting to understand the situational awareness of the system as they can correspond to risky states. To this end, we learn a generative model over the state space of the environment and use its latent space to optimize a target function for the state of interest. In our experiments we show that this method can generate insights for a variety of environments and reinforcement learning methods. We explore results in the standard Atari benchmark games as well as in an autonomous driving simulator. Based on the efficiency with which we have been able to identify behavioural weaknesses with this technique, we believe this general approach could serve as an important tool for AI safety applications.
Visual Imitation Learning with Recurrent Siamese Networks
Jan 22, 2019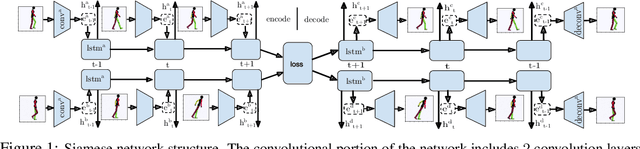

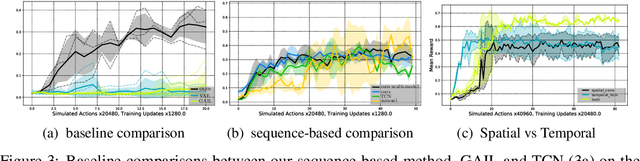
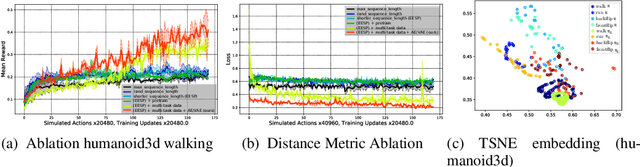
People solve the difficult problem of understanding the salient features of both observations of others and the relationship to their own state when learning to imitate specific tasks. In this work, we train a comparator network which is used to compute distances between motions. Given a desired motion the comparator can provide a reward signal to the agent via the distance between the desired motion and the agent's motion. We train an RNN-based comparator model to compute distances in space and time between motion clips while training an RL policy to minimize this distance. Furthermore, we examine a challenging form of this problem where a single \demonstrationText is provided for a given task. We demonstrate our approach in the setting of deep learning based control for physical simulation of humanoid walking in both 2D with $10$ degrees of freedom (DoF) and 3D with $38$ DoF.