 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Floor Plan Design with LLMs via Reinforcement Learning with Verifiable Rewards
May 13, 2026An AI system for professional floor plan design must precisely control room dimensions and areas while respecting the desired connectivity between rooms and maintaining functional and aesthetic quality. Existing generative approaches focus primarily on respecting the requested connectivity between rooms, but do not support generating floor plans that respect numerical constraints. We introduce a text-based floor plan generation approach that fine-tunes a large language model (LLM) on real plans and then applies reinforcement learning with verifiable rewards (RLVR) to improve adherence to topological and numerical constraints while discouraging invalid or overlapping outputs. Furthermore, we design a set of constraint adherence metrics to systematically measure how generated floor plans align with user-defined constraints. Our model generates floor plans that satisfy user-defined connectivity and numerical constraints and outperforms existing methods on Realism, Compatibility, and Diversity metrics. Across all tasks, our approach achieves at least a 94% relative reduction in Compatibility compared with existing methods. Our results demonstrate that LLMs can effectively handle constraints in this setting, suggesting broader applications for text-based generative modeling.
Diagnosing COVID-19 Severity from Chest X-Ray Images Using ViT and CNN Architectures
Feb 23, 2025


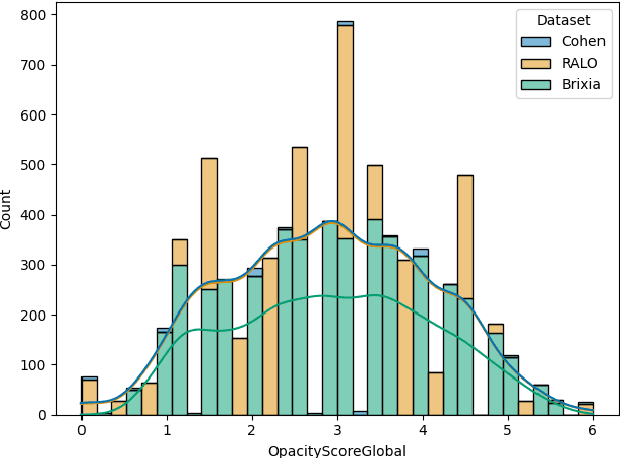
The COVID-19 pandemic strained healthcare resources and prompted discussion about how machine learning can alleviate physician burdens and contribute to diagnosis. Chest x-rays (CXRs) are used for diagnosis of COVID-19, but few studies predict the severity of a patient's condition from CXRs. In this study, we produce a large COVID severity dataset by merging three sources and investigate the efficacy of transfer learning using ImageNet- and CXR-pretrained models and vision transformers (ViTs) in both severity regression and classification tasks. A pretrained DenseNet161 model performed the best on the three class severity prediction problem, reaching 80% accuracy overall and 77.3%, 83.9%, and 70% on mild, moderate and severe cases, respectively. The ViT had the best regression results, with a mean absolute error of 0.5676 compared to radiologist-predicted severity scores. The project's source code is publicly available.
Reducing Hallucinations in Language Model-based SPARQL Query Generation Using Post-Generation Memory Retrieval
Feb 19, 2025



The ability to generate SPARQL queries from natural language questions is crucial for ensuring efficient and accurate retrieval of structured data from knowledge graphs (KG). While large language models (LLMs) have been widely adopted for SPARQL query generation, they are often susceptible to hallucinations and out-of-distribution errors when producing KG elements like Uniform Resource Identifiers (URIs) based on internal parametric knowledge. This often results in content that appears plausible but is factually incorrect, posing significant challenges for their use in real-world information retrieval (IR) applications. This has led to increased research aimed at detecting and mitigating such errors. In this paper, we introduce PGMR (Post-Generation Memory Retrieval), a modular framework that incorporates a non-parametric memory module to retrieve KG elements and enhance LLM-based SPARQL query generation. Our experimental results indicate that PGMR consistently delivers strong performance across diverse datasets, data distributions, and LLMs. Notably, PGMR significantly mitigates URI hallucinations, nearly eliminating the problem in several scenarios.
DStruct2Design: Data and Benchmarks for Data Structure Driven Generative Floor Plan Design
Jul 22, 2024



Text conditioned generative models for images have yielded impressive results. Text conditioned floorplan generation as a special type of raster image generation task also received particular attention. However there are many use cases in floorpla generation where numerical properties of the generated result are more important than the aesthetics. For instance, one might want to specify sizes for certain rooms in a floorplan and compare the generated floorplan with given specifications Current approaches, datasets and commonly used evaluations do not support these kinds of constraints. As such, an attractive strategy is to generate an intermediate data structure that contains numerical properties of a floorplan which can be used to generate the final floorplan image. To explore this setting we (1) construct a new dataset for this data-structure to data-structure formulation of floorplan generation using two popular image based floorplan datasets RPLAN and ProcTHOR-10k, and provide the tools to convert further procedurally generated ProcTHOR floorplan data into our format. (2) We explore the task of floorplan generation given a partial or complete set of constraints and we design a series of metrics and benchmarks to enable evaluating how well samples generated from models respect the constraints. (3) We create multiple baselines by finetuning a large language model (LLM), Llama3, and demonstrate the feasibility of using floorplan data structure conditioned LLMs for the problem of floorplan generation respecting numerical constraints. We hope that our new datasets and benchmarks will encourage further research on different ways to improve the performance of LLMs and other generative modelling techniques for generating designs where quantitative constraints are only partially specified, but must be respected.
Learning Action and Reasoning-Centric Image Editing from Videos and Simulations
Jul 03, 2024
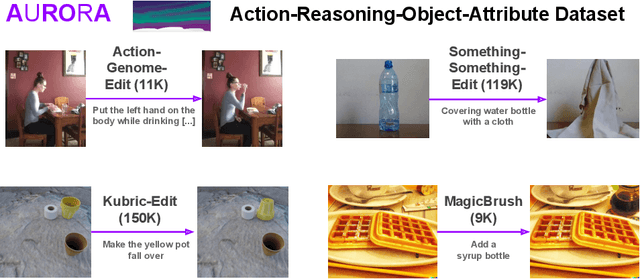

An image editing model should be able to perform diverse edits, ranging from object replacement, changing attributes or style, to performing actions or movement, which require many forms of reasoning. Current general instruction-guided editing models have significant shortcomings with action and reasoning-centric edits. Object, attribute or stylistic changes can be learned from visually static datasets. On the other hand, high-quality data for action and reasoning-centric edits is scarce and has to come from entirely different sources that cover e.g. physical dynamics, temporality and spatial reasoning. To this end, we meticulously curate the AURORA Dataset (Action-Reasoning-Object-Attribute), a collection of high-quality training data, human-annotated and curated from videos and simulation engines. We focus on a key aspect of quality training data: triplets (source image, prompt, target image) contain a single meaningful visual change described by the prompt, i.e., truly minimal changes between source and target images. To demonstrate the value of our dataset, we evaluate an AURORA-finetuned model on a new expert-curated benchmark (AURORA-Bench) covering 8 diverse editing tasks. Our model significantly outperforms previous editing models as judged by human raters. For automatic evaluations, we find important flaws in previous metrics and caution their use for semantically hard editing tasks. Instead, we propose a new automatic metric that focuses on discriminative understanding. We hope that our efforts : (1) curating a quality training dataset and an evaluation benchmark, (2) developing critical evaluations, and (3) releasing a state-of-the-art model, will fuel further progress on general image editing.