 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Guided Diffusion for Offline Black-Box Optimization
Oct 01, 2024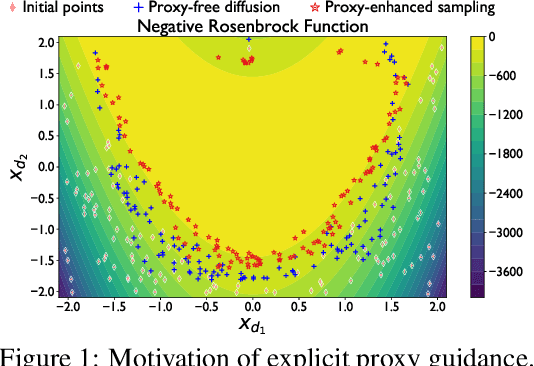
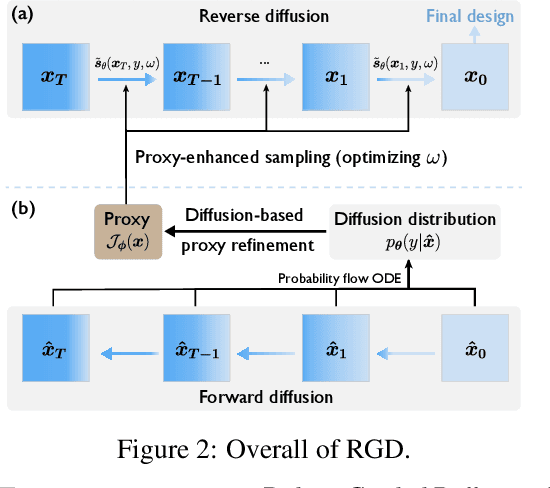
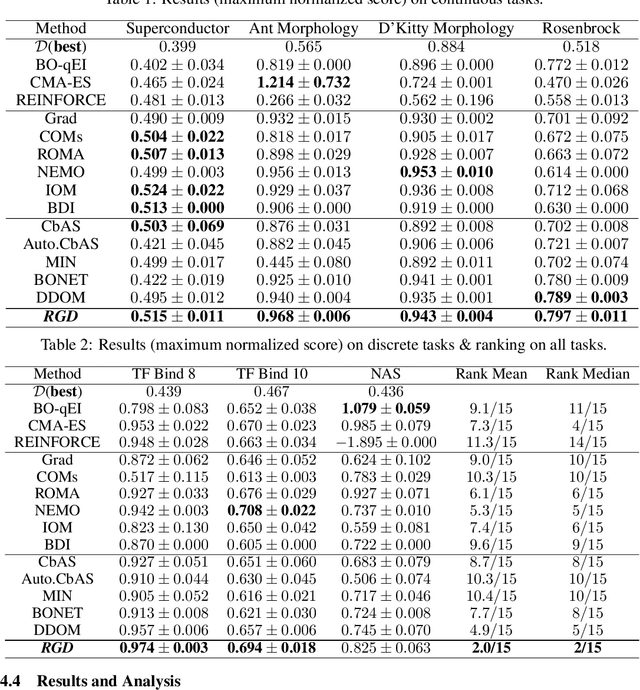
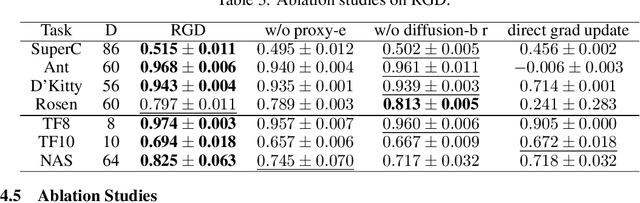
Offline black-box optimization aims to maximize a black-box function using an offline dataset of designs and their measured properties. Two main approaches have emerged: the forward approach, which learns a mapping from input to its value, thereby acting as a proxy to guide optimization, and the inverse approach, which learns a mapping from value to input for conditional generation. (a) Although proxy-free~(classifier-free) diffusion shows promise in robustly modeling the inverse mapping, it lacks explicit guidance from proxies, essential for generating high-performance samples beyond the training distribution. Therefore, we propose \textit{proxy-enhanced sampling} which utilizes the explicit guidance from a trained proxy to bolster proxy-free diffusion with enhanced sampling control. (b) Yet, the trained proxy is susceptible to out-of-distribution issues. To address this, we devise the module \textit{diffusion-based proxy refinement}, which seamlessly integrates insights from proxy-free diffusion back into the proxy for refinement. To sum up, we propose \textit{\textbf{R}obust \textbf{G}uided \textbf{D}iffusion for Offline Black-box Optimization}~(\textbf{RGD}), combining the advantages of proxy~(explicit guidance) and proxy-free diffusion~(robustness) for effective conditional generation. RGD achieves state-of-the-art results on various design-bench tasks, underscoring its efficacy. Our code is at https://anonymous.4open.science/r/RGD-27A5/README.md.
DStruct2Design: Data and Benchmarks for Data Structure Driven Generative Floor Plan Design
Jul 22, 2024



Text conditioned generative models for images have yielded impressive results. Text conditioned floorplan generation as a special type of raster image generation task also received particular attention. However there are many use cases in floorpla generation where numerical properties of the generated result are more important than the aesthetics. For instance, one might want to specify sizes for certain rooms in a floorplan and compare the generated floorplan with given specifications Current approaches, datasets and commonly used evaluations do not support these kinds of constraints. As such, an attractive strategy is to generate an intermediate data structure that contains numerical properties of a floorplan which can be used to generate the final floorplan image. To explore this setting we (1) construct a new dataset for this data-structure to data-structure formulation of floorplan generation using two popular image based floorplan datasets RPLAN and ProcTHOR-10k, and provide the tools to convert further procedurally generated ProcTHOR floorplan data into our format. (2) We explore the task of floorplan generation given a partial or complete set of constraints and we design a series of metrics and benchmarks to enable evaluating how well samples generated from models respect the constraints. (3) We create multiple baselines by finetuning a large language model (LLM), Llama3, and demonstrate the feasibility of using floorplan data structure conditioned LLMs for the problem of floorplan generation respecting numerical constraints. We hope that our new datasets and benchmarks will encourage further research on different ways to improve the performance of LLMs and other generative modelling techniques for generating designs where quantitative constraints are only partially specified, but must be respected.
Conservative objective models are a special kind of contrastive divergence-based energy model
Apr 07, 2023



In this work we theoretically show that conservative objective models (COMs) for offline model-based optimisation (MBO) are a special kind of contrastive divergence-based energy model, one where the energy function represents both the unconditional probability of the input and the conditional probability of the reward variable. While the initial formulation only samples modes from its learned distribution, we propose a simple fix that replaces its gradient ascent sampler with a Langevin MCMC sampler. This gives rise to a special probabilistic model where the probability of sampling an input is proportional to its predicted reward. Lastly, we show that better samples can be obtained if the model is decoupled so that the unconditional and conditional probabilities are modelled separately.
Score-based Diffusion Models in Function Space
Feb 14, 2023



Diffusion models have recently emerged as a powerful framework for generative modeling. They consist of a forward process that perturbs input data with Gaussian white noise and a reverse process that learns a score function to generate samples by denoising. Despite their tremendous success, they are mostly formulated on finite-dimensional spaces, e.g. Euclidean, limiting their applications to many domains where the data has a functional form such as in scientific computing and 3D geometric data analysis. In this work, we introduce a mathematically rigorous framework called Denoising Diffusion Operators (DDOs) for training diffusion models in function space. In DDOs, the forward process perturbs input functions gradually using a Gaussian process. The generative process is formulated by integrating a function-valued Langevin dynamic. Our approach requires an appropriate notion of the score for the perturbed data distribution, which we obtain by generalizing denoising score matching to function spaces that can be infinite-dimensional. We show that the corresponding discretized algorithm generates accurate samples at a fixed cost that is independent of the data resolution. We theoretically and numerically verify the applicability of our approach on a set of problems, including generating solutions to the Navier-Stokes equation viewed as the push-forward distribution of forcings from a Gaussian Random Field (GRF).
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
Towards good validation metrics for generative models in offline model-based optimisation
Nov 19, 2022In this work we propose a principled evaluation framework for model-based optimisation to measure how well a generative model can extrapolate. We achieve this by interpreting the training and validation splits as draws from their respective `truncated' ground truth distributions, where examples in the validation set contain scores much larger than those in the training set. Model selection is performed on the validation set for some prescribed validation metric. A major research question however is in determining what validation metric correlates best with the expected value of generated candidates with respect to the ground truth oracle; work towards answering this question can translate to large economic gains since it is expensive to evaluate the ground truth oracle in the real world. We compare various validation metrics for generative adversarial networks using our framework. We also discuss limitations with our framework with respect to existing datasets and how progress can be made to mitigate them.
Challenges in leveraging GANs for few-shot data augmentation
Mar 30, 2022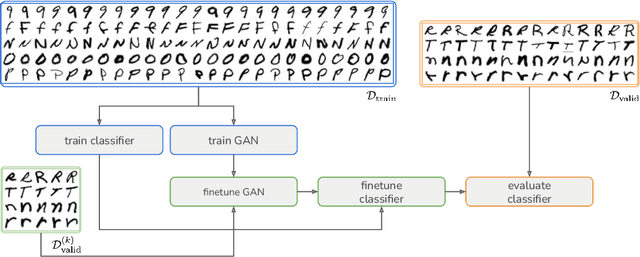
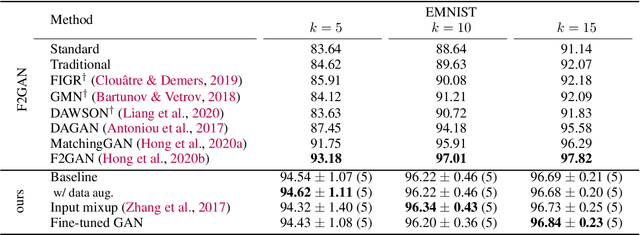
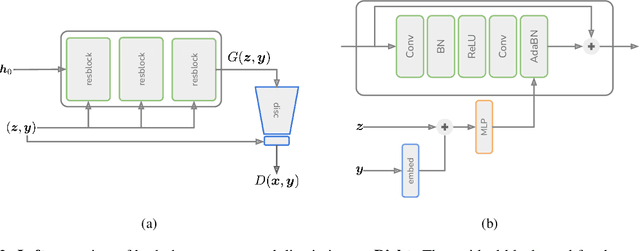

In this paper, we explore the use of GAN-based few-shot data augmentation as a method to improve few-shot classification performance. We perform an exploration into how a GAN can be fine-tuned for such a task (one of which is in a class-incremental manner), as well as a rigorous empirical investigation into how well these models can perform to improve few-shot classification. We identify issues related to the difficulty of training such generative models under a purely supervised regime with very few examples, as well as issues regarding the evaluation protocols of existing works. We also find that in this regime, classification accuracy is highly sensitive to how the classes of the dataset are randomly split. Therefore, we propose a semi-supervised fine-tuning approach as a more pragmatic way forward to address these problems.
Adversarial Mixup Resynthesizers
Apr 04, 2019
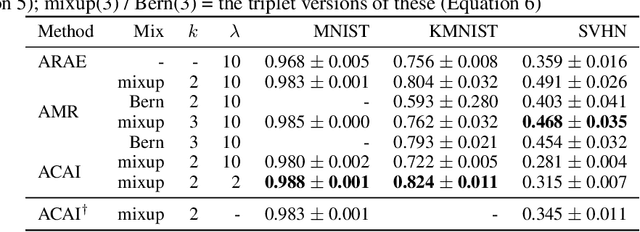
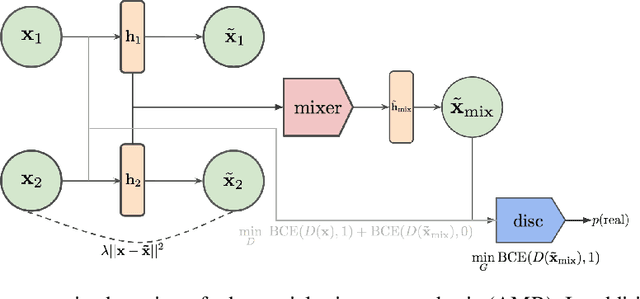
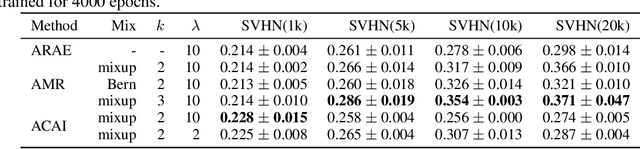
In this paper, we explore new approaches to combining information encoded within the learned representations of autoencoders. We explore models that are capable of combining the attributes of multiple inputs such that a resynthesised output is trained to fool an adversarial discriminator for real versus synthesised data. Furthermore, we explore the use of such an architecture in the context of semi-supervised learning, where we learn a mixing function whose objective is to produce interpolations of hidden states, or masked combinations of latent representations that are consistent with a conditioned class label. We show quantitative and qualitative evidence that such a formulation is an interesting avenue of research.
Manifold Mixup: Learning Better Representations by Interpolating Hidden States
Oct 04, 2018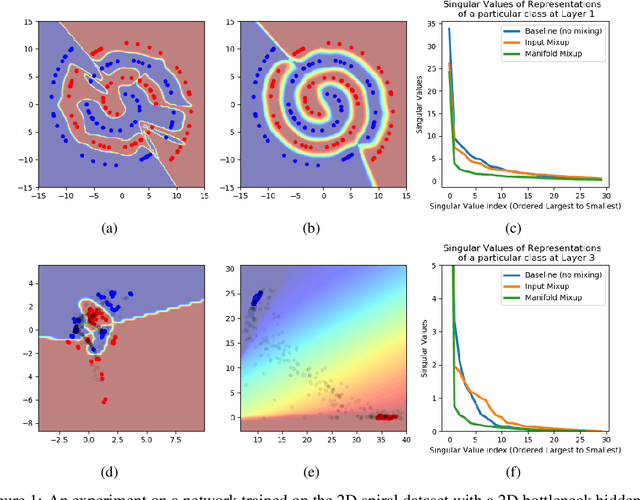
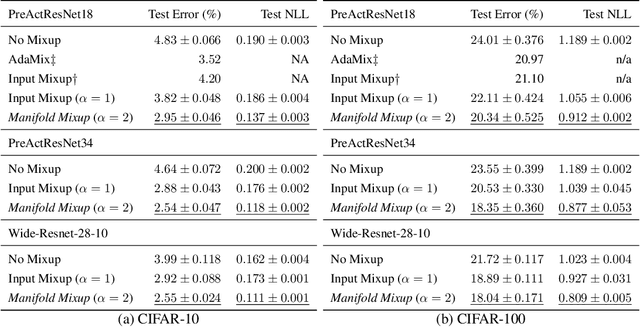
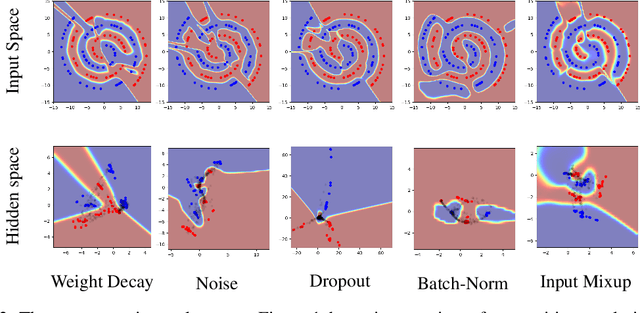
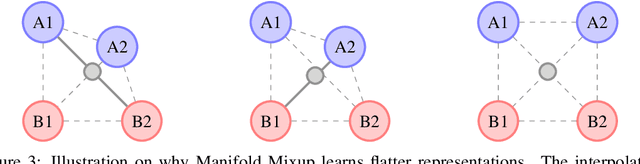
Deep networks often perform well on the data distribution on which they are trained, yet give incorrect (and often very confident) answers when evaluated on points from off of the training distribution. This is exemplified by the adversarial examples phenomenon but can also be seen in terms of model generalization and domain shift. Ideally, a model would assign lower confidence to points unlike those from the training distribution. We propose a regularizer which addresses this issue by training with interpolated hidden states and encouraging the classifier to be less confident at these points. Because the hidden states are learned, this has an important effect of encouraging the hidden states for a class to be concentrated in such a way so that interpolations within the same class or between two different classes do not intersect with the real data points from other classes. This has a major advantage in that it avoids the underfitting which can result from interpolating in the input space. We prove that the exact condition for this problem of underfitting to be avoided by Manifold Mixup is that the dimensionality of the hidden states exceeds the number of classes, which is often the case in practice. Additionally, this concentration can be seen as making the features in earlier layers more discriminative. We show that despite requiring no significant additional computation, Manifold Mixup achieves large improvements over strong baselines in supervised learning, robustness to single-step adversarial attacks, semi-supervised learning, and Negative Log-Likelihood on held out samples.
Unsupervised Depth Estimation, 3D Face Rotation and Replacement
Oct 01, 2018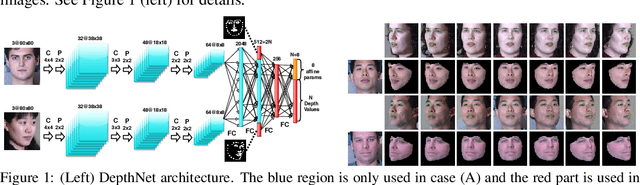

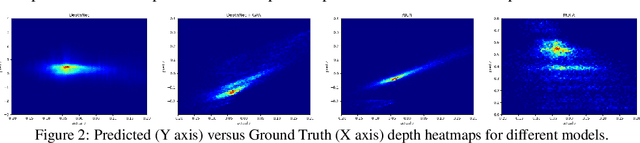
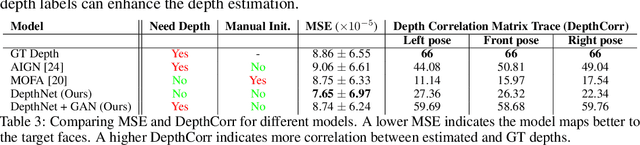
We present an unsupervised approach for learning to estimate three dimensional (3D) facial structure from a single image while also predicting 3D viewpoint transformations that match a desired pose and facial geometry. We achieve this by inferring the depth of facial keypoints of an input image in an unsupervised manner, without using any form of ground-truth depth information. We show how it is possible to use these depths as intermediate computations within a new backpropable loss to predict the parameters of a 3D affine transformation matrix that maps inferred 3D keypoints of an input face to the corresponding 2D keypoints on a desired target facial geometry or pose. Our resulting approach can therefore be used to infer plausible 3D transformations from one face pose to another, allowing faces to be frontalized, transformed into 3D models or even warped to another pose and facial geometry. Lastly, we identify certain shortcomings with our formulation, and explore adversarial image translation techniques as a post-processing step to re-synthesize complete head shots for faces re-targeted to different poses or identities.
* Depth Estimation, Face Rotation, Face Swap