 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Floor Plan Design with LLMs via Reinforcement Learning with Verifiable Rewards
May 13, 2026An AI system for professional floor plan design must precisely control room dimensions and areas while respecting the desired connectivity between rooms and maintaining functional and aesthetic quality. Existing generative approaches focus primarily on respecting the requested connectivity between rooms, but do not support generating floor plans that respect numerical constraints. We introduce a text-based floor plan generation approach that fine-tunes a large language model (LLM) on real plans and then applies reinforcement learning with verifiable rewards (RLVR) to improve adherence to topological and numerical constraints while discouraging invalid or overlapping outputs. Furthermore, we design a set of constraint adherence metrics to systematically measure how generated floor plans align with user-defined constraints. Our model generates floor plans that satisfy user-defined connectivity and numerical constraints and outperforms existing methods on Realism, Compatibility, and Diversity metrics. Across all tasks, our approach achieves at least a 94% relative reduction in Compatibility compared with existing methods. Our results demonstrate that LLMs can effectively handle constraints in this setting, suggesting broader applications for text-based generative modeling.
Beyond FVD: Enhanced Evaluation Metrics for Video Generation Quality
Oct 07, 2024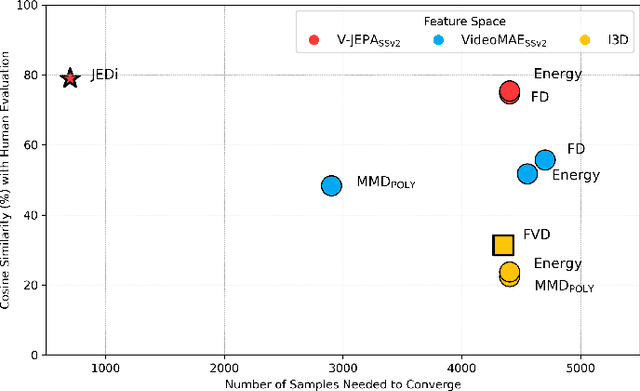

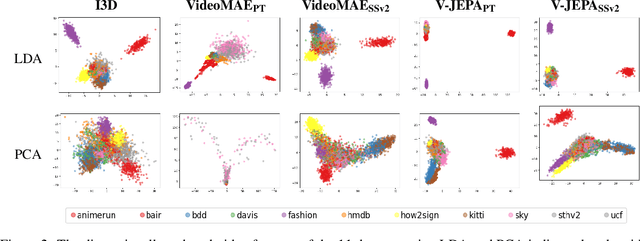

The Fr\'echet Video Distance (FVD) is a widely adopted metric for evaluating video generation distribution quality. However, its effectiveness relies on critical assumptions. Our analysis reveals three significant limitations: (1) the non-Gaussianity of the Inflated 3D Convnet (I3D) feature space; (2) the insensitivity of I3D features to temporal distortions; (3) the impractical sample sizes required for reliable estimation. These findings undermine FVD's reliability and show that FVD falls short as a standalone metric for video generation evaluation. After extensive analysis of a wide range of metrics and backbone architectures, we propose JEDi, the JEPA Embedding Distance, based on features derived from a Joint Embedding Predictive Architecture, measured using Maximum Mean Discrepancy with polynomial kernel. Our experiments on multiple open-source datasets show clear evidence that it is a superior alternative to the widely used FVD metric, requiring only 16% of the samples to reach its steady value, while increasing alignment with human evaluation by 34%, on average.
DStruct2Design: Data and Benchmarks for Data Structure Driven Generative Floor Plan Design
Jul 22, 2024



Text conditioned generative models for images have yielded impressive results. Text conditioned floorplan generation as a special type of raster image generation task also received particular attention. However there are many use cases in floorpla generation where numerical properties of the generated result are more important than the aesthetics. For instance, one might want to specify sizes for certain rooms in a floorplan and compare the generated floorplan with given specifications Current approaches, datasets and commonly used evaluations do not support these kinds of constraints. As such, an attractive strategy is to generate an intermediate data structure that contains numerical properties of a floorplan which can be used to generate the final floorplan image. To explore this setting we (1) construct a new dataset for this data-structure to data-structure formulation of floorplan generation using two popular image based floorplan datasets RPLAN and ProcTHOR-10k, and provide the tools to convert further procedurally generated ProcTHOR floorplan data into our format. (2) We explore the task of floorplan generation given a partial or complete set of constraints and we design a series of metrics and benchmarks to enable evaluating how well samples generated from models respect the constraints. (3) We create multiple baselines by finetuning a large language model (LLM), Llama3, and demonstrate the feasibility of using floorplan data structure conditioned LLMs for the problem of floorplan generation respecting numerical constraints. We hope that our new datasets and benchmarks will encourage further research on different ways to improve the performance of LLMs and other generative modelling techniques for generating designs where quantitative constraints are only partially specified, but must be respected.
Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion
Jun 09, 2024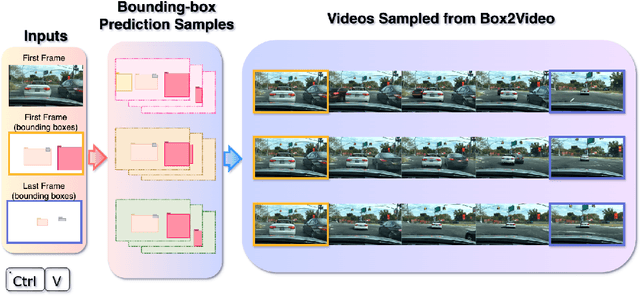
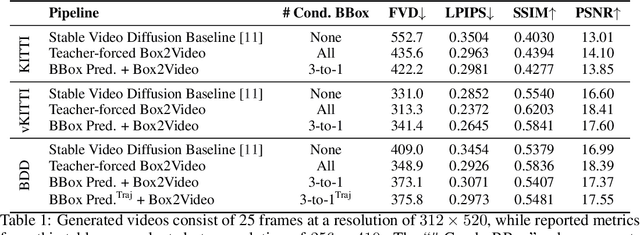


With recent advances in video prediction, controllable video generation has been attracting more attention. Generating high fidelity videos according to simple and flexible conditioning is of particular interest. To this end, we propose a controllable video generation model using pixel level renderings of 2D or 3D bounding boxes as conditioning. In addition, we also create a bounding box predictor that, given the initial and ending frames' bounding boxes, can predict up to 15 bounding boxes per frame for all the frames in a 25-frame clip. We perform experiments across 3 well-known AV video datasets: KITTI, Virtual-KITTI 2 and BDD100k.