 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Efficiency of Inverse Dynamics Models for Semi-Supervised Imitation Learning
Feb 02, 2026Semi-supervised imitation learning (SSIL) consists in learning a policy from a small dataset of action-labeled trajectories and a much larger dataset of action-free trajectories. Some SSIL methods learn an inverse dynamics model (IDM) to predict the action from the current state and the next state. An IDM can act as a policy when paired with a video model (VM-IDM) or as a label generator to perform behavior cloning on action-free data (IDM labeling). In this work, we first show that VM-IDM and IDM labeling learn the same policy in a limit case, which we call the IDM-based policy. We then argue that the previously observed advantage of IDM-based policies over behavior cloning is due to the superior sample efficiency of IDM learning, which we attribute to two causes: (i) the ground-truth IDM tends to be contained in a lower complexity hypothesis class relative to the expert policy, and (ii) the ground-truth IDM is often less stochastic than the expert policy. We argue these claims based on insights from statistical learning theory and novel experiments, including a study of IDM-based policies using recent architectures for unified video-action prediction (UVA). Motivated by these insights, we finally propose an improved version of the existing LAPO algorithm for latent action policy learning.
Less is More: Recursive Reasoning with Tiny Networks
Oct 06, 2025Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard puzzle tasks such as Sudoku, Maze, and ARC-AGI while trained with small models (27M parameters) on small data (around 1000 examples). HRM holds great promise for solving hard problems with small networks, but it is not yet well understood and may be suboptimal. We propose Tiny Recursive Model (TRM), a much simpler recursive reasoning approach that achieves significantly higher generalization than HRM, while using a single tiny network with only 2 layers. With only 7M parameters, TRM obtains 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2, higher than most LLMs (e.g., Deepseek R1, o3-mini, Gemini 2.5 Pro) with less than 0.01% of the parameters.
Multi-Agent Game Generation and Evaluation via Audio-Visual Recordings
Aug 01, 2025



While AI excels at generating text, audio, images, and videos, creating interactive audio-visual content such as video games remains challenging. Current LLMs can generate JavaScript games and animations, but lack automated evaluation metrics and struggle with complex content that normally requires teams of humans working for many months (multi-shot, multi-agents) using assets made by artists. To tackle these issues, we built a new metric and a multi-agent system. We propose AVR-Eval, a relative metric for multimedia content quality using Audio-Visual Recordings (AVRs). An omni-modal model (processing text, video, and audio) compares the AVRs of two contents, with a text model reviewing evaluations to determine superiority. We show that AVR-Eval properly identifies good from broken or mismatched content. We built AVR-Agent, a multi-agent system generating JavaScript code from a bank of multimedia assets (audio, images, 3D models). The coding agent selects relevant assets, generates multiple initial codes, uses AVR-Eval to identify the best version, and iteratively improves it through omni-modal agent feedback from the AVR. We run experiments on games and animations with AVR-Eval (win rate of content A against B). We find that content generated by AVR-Agent has a significantly higher win rate against content made through one-shot generation. However, models struggle to leverage custom assets and AVR feedback effectively, showing no higher win rate. This reveals a critical gap: while humans benefit from high-quality assets and audio-visual feedback, current coding models do not seem to utilize these resources as effectively, highlighting fundamental differences between human and machine content creation approaches.
Generating $π$-Functional Molecules Using STGG+ with Active Learning
Feb 20, 2025Generating novel molecules with out-of-distribution properties is a major challenge in molecular discovery. While supervised learning methods generate high-quality molecules similar to those in a dataset, they struggle to generalize to out-of-distribution properties. Reinforcement learning can explore new chemical spaces but often conducts 'reward-hacking' and generates non-synthesizable molecules. In this work, we address this problem by integrating a state-of-the-art supervised learning method, STGG+, in an active learning loop. Our approach iteratively generates, evaluates, and fine-tunes STGG+ to continuously expand its knowledge. We denote this approach STGG+AL. We apply STGG+AL to the design of organic $\pi$-functional materials, specifically two challenging tasks: 1) generating highly absorptive molecules characterized by high oscillator strength and 2) designing absorptive molecules with reasonable oscillator strength in the near-infrared (NIR) range. The generated molecules are validated and rationalized in-silico with time-dependent density functional theory. Our results demonstrate that our method is highly effective in generating novel molecules with high oscillator strength, contrary to existing methods such as reinforcement learning (RL) methods. We open-source our active-learning code along with our Conjugated-xTB dataset containing 2.9 million $\pi$-conjugated molecules and the function for approximating the oscillator strength and absorption wavelength (based on sTDA-xTB).
Understanding Adam Requires Better Rotation Dependent Assumptions
Oct 25, 2024



Despite its widespread adoption, Adam's advantage over Stochastic Gradient Descent (SGD) lacks a comprehensive theoretical explanation. This paper investigates Adam's sensitivity to rotations of the parameter space. We demonstrate that Adam's performance in training transformers degrades under random rotations of the parameter space, indicating a crucial sensitivity to the choice of basis. This reveals that conventional rotation-invariant assumptions are insufficient to capture Adam's advantages theoretically. To better understand the rotation-dependent properties that benefit Adam, we also identify structured rotations that preserve or even enhance its empirical performance. We then examine the rotation-dependent assumptions in the literature, evaluating their adequacy in explaining Adam's behavior across various rotation types. This work highlights the need for new, rotation-dependent theoretical frameworks to fully understand Adam's empirical success in modern machine learning tasks.
Generating Tabular Data Using Heterogeneous Sequential Feature Forest Flow Matching
Oct 20, 2024



Privacy and regulatory constraints make data generation vital to advancing machine learning without relying on real-world datasets. A leading approach for tabular data generation is the Forest Flow (FF) method, which combines Flow Matching with XGBoost. Despite its good performance, FF is slow and makes errors when treating categorical variables as one-hot continuous features. It is also highly sensitive to small changes in the initial conditions of the ordinary differential equation (ODE). To overcome these limitations, we develop Heterogeneous Sequential Feature Forest Flow (HS3F). Our method generates data sequentially (feature-by-feature), reducing the dependency on noisy initial conditions through the additional information from previously generated features. Furthermore, it generates categorical variables using multinomial sampling (from an XGBoost classifier) instead of flow matching, improving generation speed. We also use a Runge-Kutta 4th order (Rg4) ODE solver for improved performance over the Euler solver used in FF. Our experiments with 25 datasets reveal that HS3F produces higher quality and more diverse synthetic data than FF, especially for categorical variables. It also generates data 21-27 times faster for datasets with $\geq20%$ categorical variables. HS3F further demonstrates enhanced robustness to affine transformation in flow ODE initial conditions compared to FF. This study not only validates the HS3F but also unveils promising new strategies to advance generative models.
Beyond FVD: Enhanced Evaluation Metrics for Video Generation Quality
Oct 07, 2024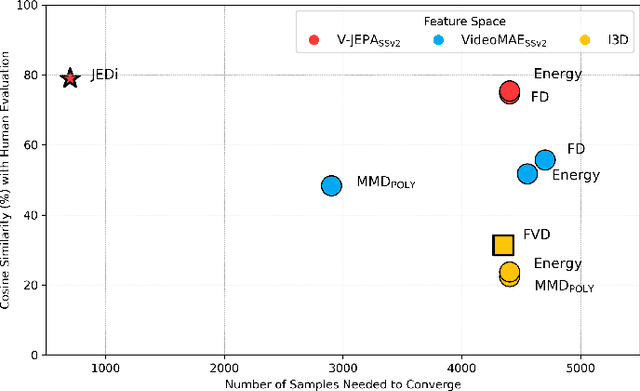


The Fr\'echet Video Distance (FVD) is a widely adopted metric for evaluating video generation distribution quality. However, its effectiveness relies on critical assumptions. Our analysis reveals three significant limitations: (1) the non-Gaussianity of the Inflated 3D Convnet (I3D) feature space; (2) the insensitivity of I3D features to temporal distortions; (3) the impractical sample sizes required for reliable estimation. These findings undermine FVD's reliability and show that FVD falls short as a standalone metric for video generation evaluation. After extensive analysis of a wide range of metrics and backbone architectures, we propose JEDi, the JEPA Embedding Distance, based on features derived from a Joint Embedding Predictive Architecture, measured using Maximum Mean Discrepancy with polynomial kernel. Our experiments on multiple open-source datasets show clear evidence that it is a superior alternative to the widely used FVD metric, requiring only 16% of the samples to reach its steady value, while increasing alignment with human evaluation by 34%, on average.
Any-Property-Conditional Molecule Generation with Self-Criticism using Spanning Trees
Jul 12, 2024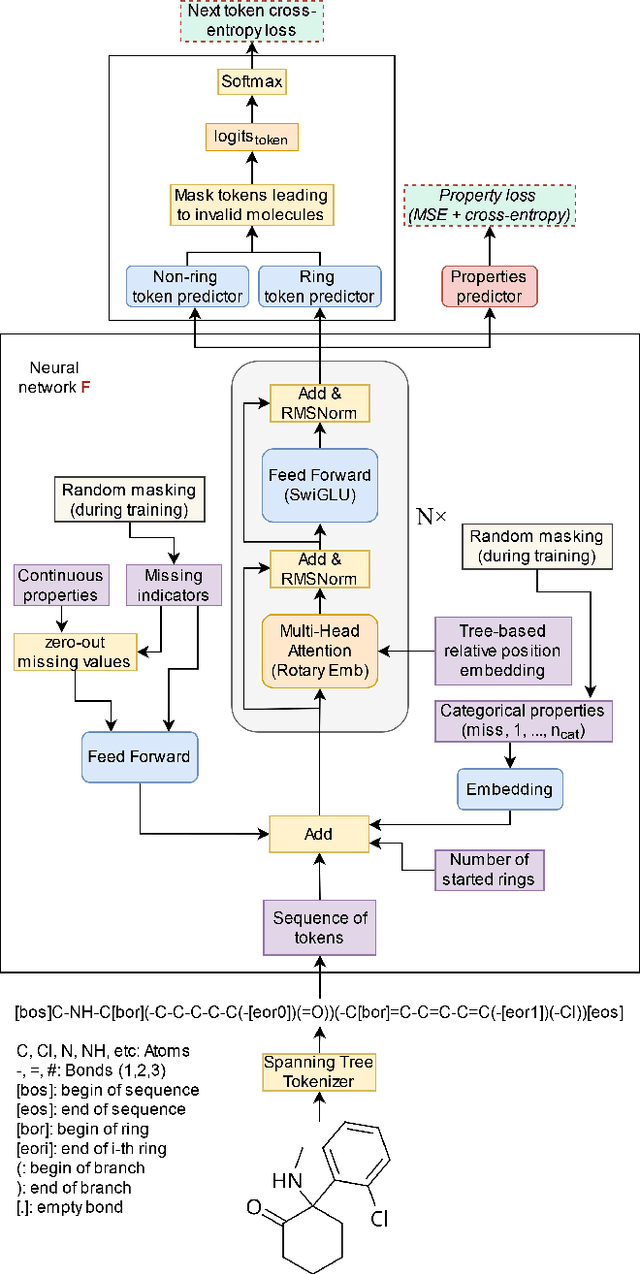
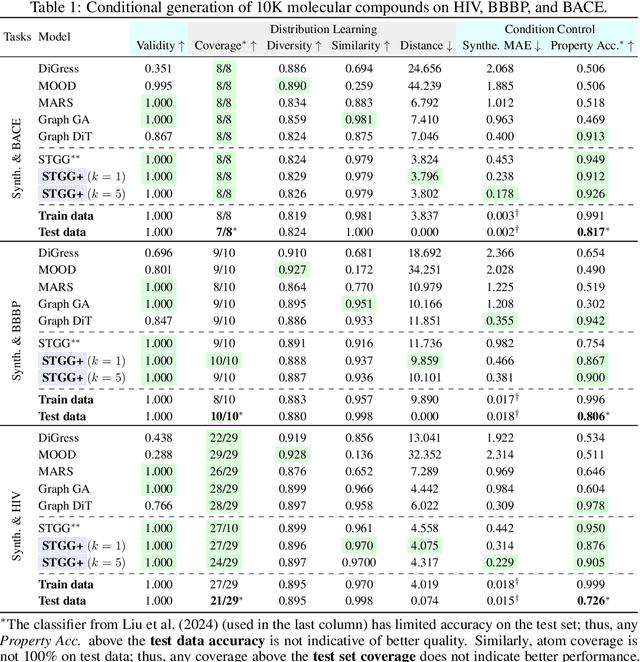
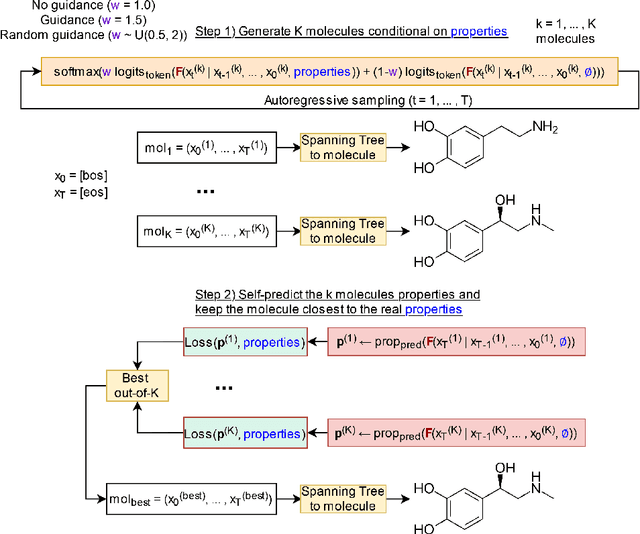
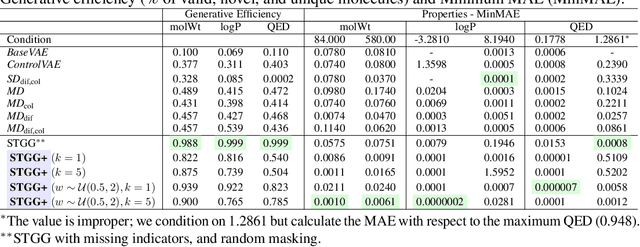
Generating novel molecules is challenging, with most representations leading to generative models producing many invalid molecules. Spanning Tree-based Graph Generation (STGG) is a promising approach to ensure the generation of valid molecules, outperforming state-of-the-art SMILES and graph diffusion models for unconditional generation. In the real world, we want to be able to generate molecules conditional on one or multiple desired properties rather than unconditionally. Thus, in this work, we extend STGG to multi-property-conditional generation. Our approach, STGG+, incorporates a modern Transformer architecture, random masking of properties during training (enabling conditioning on any subset of properties and classifier-free guidance), an auxiliary property-prediction loss (allowing the model to self-criticize molecules and select the best ones), and other improvements. We show that STGG+ achieves state-of-the-art performance on in-distribution and out-of-distribution conditional generation, and reward maximization.
Ctrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion
Jun 09, 2024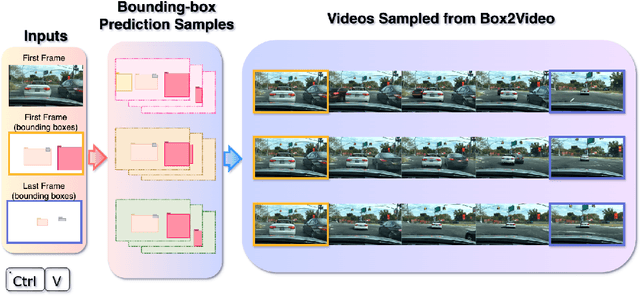
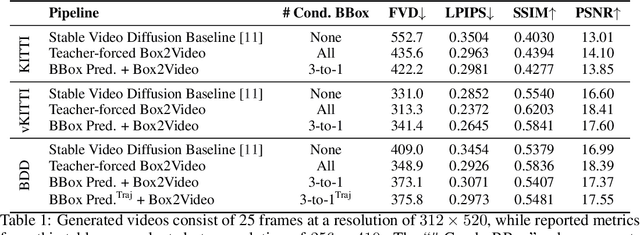


With recent advances in video prediction, controllable video generation has been attracting more attention. Generating high fidelity videos according to simple and flexible conditioning is of particular interest. To this end, we propose a controllable video generation model using pixel level renderings of 2D or 3D bounding boxes as conditioning. In addition, we also create a bounding box predictor that, given the initial and ending frames' bounding boxes, can predict up to 15 bounding boxes per frame for all the frames in a 25-frame clip. We perform experiments across 3 well-known AV video datasets: KITTI, Virtual-KITTI 2 and BDD100k.
LoGAH: Predicting 774-Million-Parameter Transformers using Graph HyperNetworks with 1/100 Parameters
May 25, 2024A good initialization of deep learning models is essential since it can help them converge better and faster. However, pretraining large models is unaffordable for many researchers, which makes a desired prediction for initial parameters more necessary nowadays. Graph HyperNetworks (GHNs), one approach to predicting model parameters, have recently shown strong performance in initializing large vision models. Unfortunately, predicting parameters of very wide networks relies on copying small chunks of parameters multiple times and requires an extremely large number of parameters to support full prediction, which greatly hinders its adoption in practice. To address this limitation, we propose LoGAH (Low-rank GrAph Hypernetworks), a GHN with a low-rank parameter decoder that expands to significantly wider networks without requiring as excessive increase of parameters as in previous attempts. LoGAH allows us to predict the parameters of 774-million large neural networks in a memory-efficient manner. We show that vision and language models (i.e., ViT and GPT-2) initialized with LoGAH achieve better performance than those initialized randomly or using existing hypernetworks. Furthermore, we show promising transfer learning results w.r.t. training LoGAH on small datasets and using the predicted parameters to initialize for larger tasks. We provide the codes in https://github.com/Blackzxy/LoGAH .