 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgestable-worldmodel: A Platform for Reproducible World Modeling Research and Evaluation
May 20, 2026World models are central to building agents that can reason, plan, and generalize beyond their training data. However, research on world models is currently fragmented, with disparate codebases, data pipelines, and evaluation protocols hindering reproducibility and fair comparison. Current practice is further limited by three key bottlenecks: fragile one-off codebases, slow video data loading, and the lack of standardized generalization benchmarks. We present stable-worldmodel (swm), an open-source platform for standardized and reproducible world modeling research and evaluation. It delivers (1) a high-performance Lance-based data layer with native support and conversion tools for MP4, HDF5, and LeRobot datasets, (2) clean, well-tested implementations of modern world model baselines and planning solvers, and (3) a broad suite of environments and tasks extended with controllable visual, geometric, and physical factors of variation for systematic in-silico evaluation of dynamics understanding, control performance, representation quality, and out-of-distribution generalization. By unifying the full pipeline under a single, scalable framework, \texttt{swm} dramatically reduces research overhead and accelerates trustworthy progress toward reliable world models.
stable-worldmodel-v1: Reproducible World Modeling Research and Evaluation
Feb 09, 2026World Models have emerged as a powerful paradigm for learning compact, predictive representations of environment dynamics, enabling agents to reason, plan, and generalize beyond direct experience. Despite recent interest in World Models, most available implementations remain publication-specific, severely limiting their reusability, increasing the risk of bugs, and reducing evaluation standardization. To mitigate these issues, we introduce stable-worldmodel (SWM), a modular, tested, and documented world-model research ecosystem that provides efficient data-collection tools, standardized environments, planning algorithms, and baseline implementations. In addition, each environment in SWM enables controllable factors of variation, including visual and physical properties, to support robustness and continual learning research. Finally, we demonstrate the utility of SWM by using it to study zero-shot robustness in DINO-WM.
Understanding Adam Requires Better Rotation Dependent Assumptions
Oct 25, 2024



Despite its widespread adoption, Adam's advantage over Stochastic Gradient Descent (SGD) lacks a comprehensive theoretical explanation. This paper investigates Adam's sensitivity to rotations of the parameter space. We demonstrate that Adam's performance in training transformers degrades under random rotations of the parameter space, indicating a crucial sensitivity to the choice of basis. This reveals that conventional rotation-invariant assumptions are insufficient to capture Adam's advantages theoretically. To better understand the rotation-dependent properties that benefit Adam, we also identify structured rotations that preserve or even enhance its empirical performance. We then examine the rotation-dependent assumptions in the literature, evaluating their adequacy in explaining Adam's behavior across various rotation types. This work highlights the need for new, rotation-dependent theoretical frameworks to fully understand Adam's empirical success in modern machine learning tasks.
SING: A Plug-and-Play DNN Learning Technique
May 25, 2023



We propose SING (StabIlized and Normalized Gradient), a plug-and-play technique that improves the stability and generalization of the Adam(W) optimizer. SING is straightforward to implement and has minimal computational overhead, requiring only a layer-wise standardization of the gradients fed to Adam(W) without introducing additional hyper-parameters. We support the effectiveness and practicality of the proposed approach by showing improved results on a wide range of architectures, problems (such as image classification, depth estimation, and natural language processing), and in combination with other optimizers. We provide a theoretical analysis of the convergence of the method, and we show that by virtue of the standardization, SING can escape local minima narrower than a threshold that is inversely proportional to the network's depth.
The Curse of Unrolling: Rate of Differentiating Through Optimization
Sep 27, 2022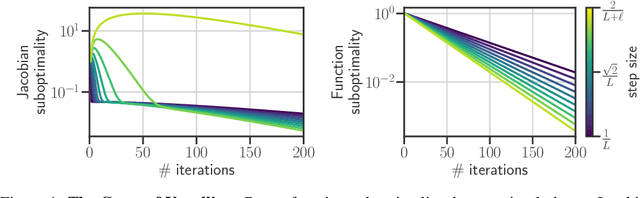
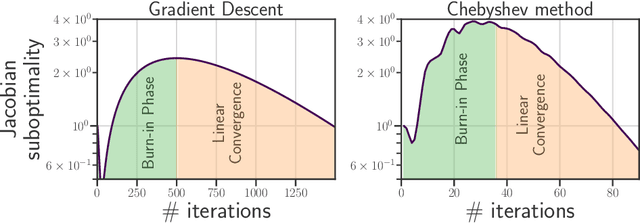
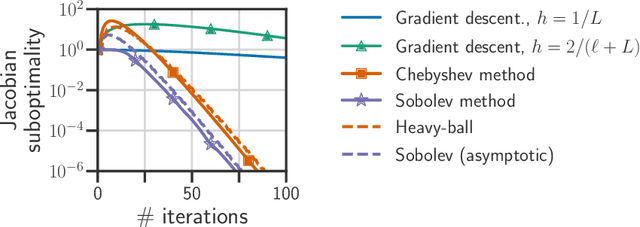
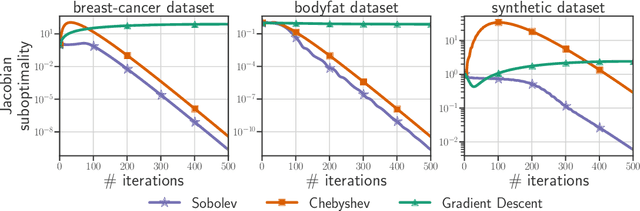
Computing the Jacobian of the solution of an optimization problem is a central problem in machine learning, with applications in hyperparameter optimization, meta-learning, optimization as a layer, and dataset distillation, to name a few. Unrolled differentiation is a popular heuristic that approximates the solution using an iterative solver and differentiates it through the computational path. This work provides a non-asymptotic convergence-rate analysis of this approach on quadratic objectives for gradient descent and the Chebyshev method. We show that to ensure convergence of the Jacobian, we can either 1) choose a large learning rate leading to a fast asymptotic convergence but accept that the algorithm may have an arbitrarily long burn-in phase or 2) choose a smaller learning rate leading to an immediate but slower convergence. We refer to this phenomenon as the curse of unrolling. Finally, we discuss open problems relative to this approach, such as deriving a practical update rule for the optimal unrolling strategy and making novel connections with the field of Sobolev orthogonal polynomials.
Only Tails Matter: Average-Case Universality and Robustness in the Convex Regime
Jun 22, 2022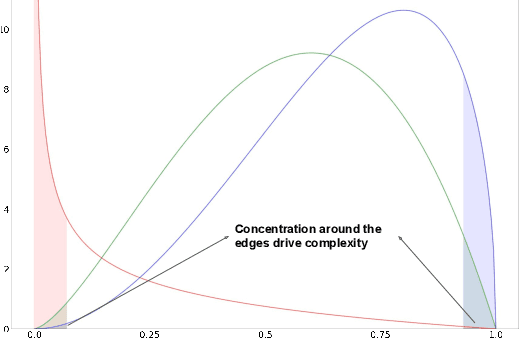


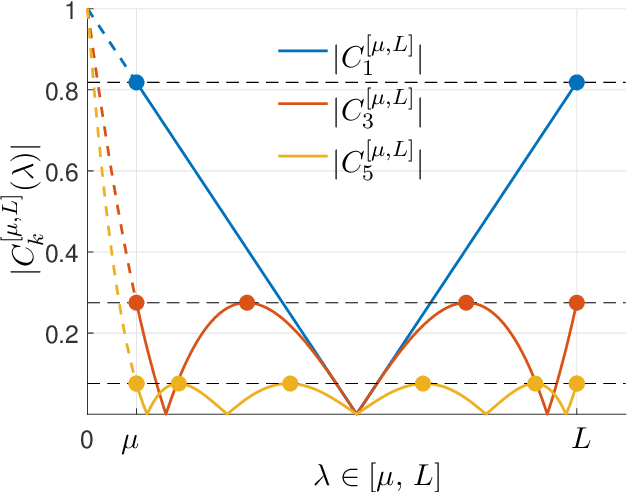
The recently developed average-case analysis of optimization methods allows a more fine-grained and representative convergence analysis than usual worst-case results. In exchange, this analysis requires a more precise hypothesis over the data generating process, namely assuming knowledge of the expected spectral distribution (ESD) of the random matrix associated with the problem. This work shows that the concentration of eigenvalues near the edges of the ESD determines a problem's asymptotic average complexity. This a priori information on this concentration is a more grounded assumption than complete knowledge of the ESD. This approximate concentration is effectively a middle ground between the coarseness of the worst-case scenario convergence and the restrictive previous average-case analysis. We also introduce the Generalized Chebyshev method, asymptotically optimal under a hypothesis on this concentration and globally optimal when the ESD follows a Beta distribution. We compare its performance to classical optimization algorithms, such as gradient descent or Nesterov's scheme, and we show that, in the average-case context, Nesterov's method is universally nearly optimal asymptotically.
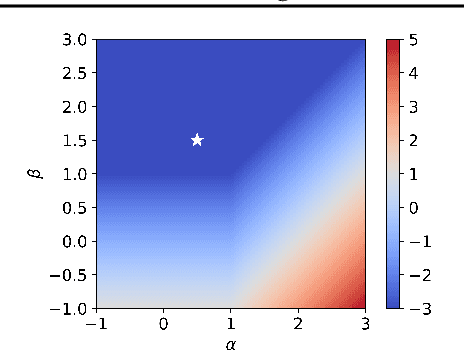
Convergence Rates for the MAP of an Exponential Family and Stochastic Mirror Descent -- an Open Problem
Nov 12, 2021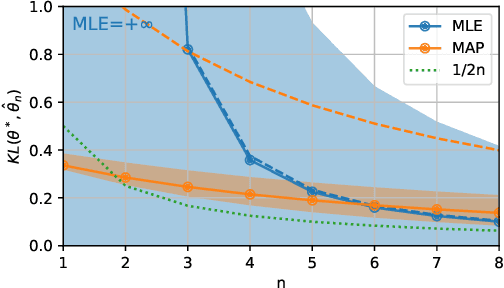
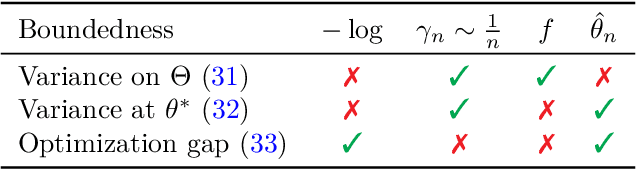
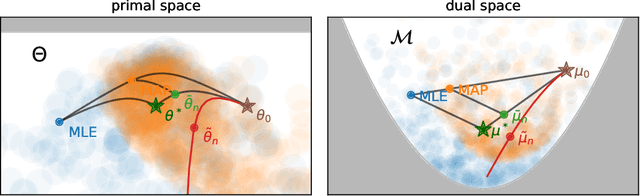
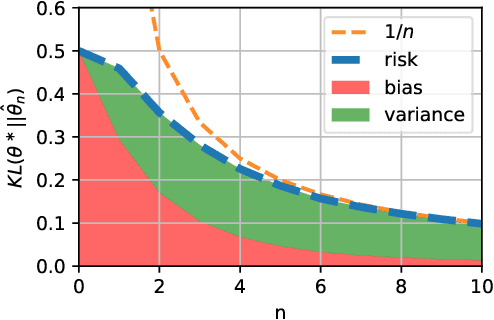
We consider the problem of upper bounding the expected log-likelihood sub-optimality of the maximum likelihood estimate (MLE), or a conjugate maximum a posteriori (MAP) for an exponential family, in a non-asymptotic way. Surprisingly, we found no general solution to this problem in the literature. In particular, current theories do not hold for a Gaussian or in the interesting few samples regime. After exhibiting various facets of the problem, we show we can interpret the MAP as running stochastic mirror descent (SMD) on the log-likelihood. However, modern convergence results do not apply for standard examples of the exponential family, highlighting holes in the convergence literature. We believe solving this very fundamental problem may bring progress to both the statistics and optimization communities.
Connecting Sphere Manifolds Hierarchically for Regularization
Jun 25, 2021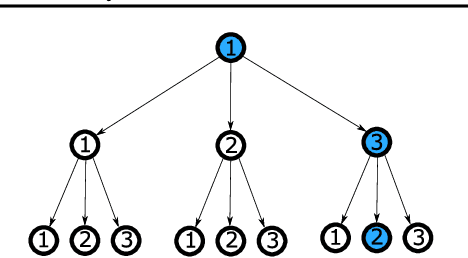
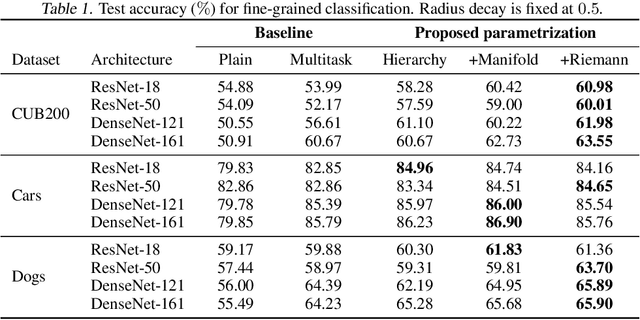
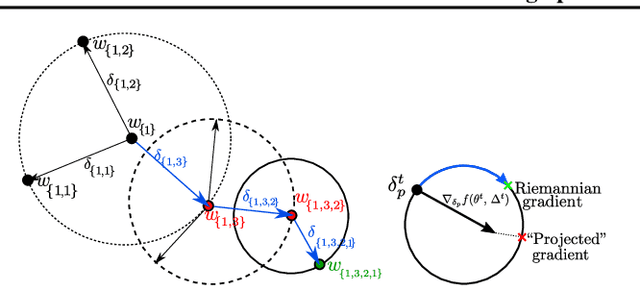
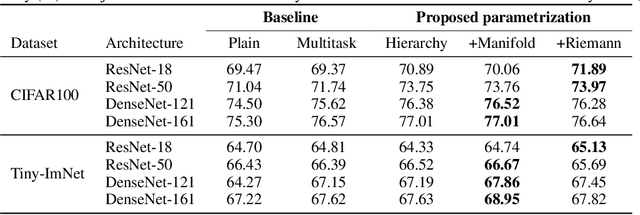
This paper considers classification problems with hierarchically organized classes. We force the classifier (hyperplane) of each class to belong to a sphere manifold, whose center is the classifier of its super-class. Then, individual sphere manifolds are connected based on their hierarchical relations. Our technique replaces the last layer of a neural network by combining a spherical fully-connected layer with a hierarchical layer. This regularization is shown to improve the performance of widely used deep neural network architectures (ResNet and DenseNet) on publicly available datasets (CIFAR100, CUB200, Stanford dogs, Stanford cars, and Tiny-ImageNet).
Acceleration Methods
Jan 23, 2021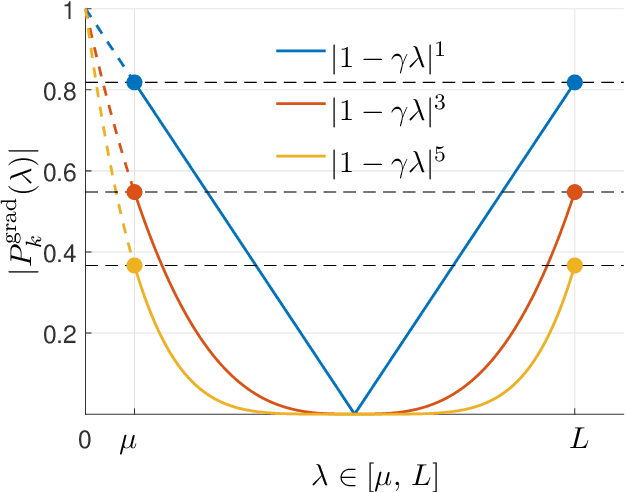
This monograph covers some recent advances on a range of acceleration techniques frequently used in convex optimization. We first use quadratic optimization problems to introduce two key families of methods, momentum and nested optimization schemes, which coincide in the quadratic case to form the Chebyshev method whose complexity is analyzed using Chebyshev polynomials. We discuss momentum methods in detail, starting with the seminal work of Nesterov (1983) and structure convergence proofs using a few master templates, such as that of \emph{optimized gradient methods} which have the key benefit of showing how momentum methods maximize convergence rates. We further cover proximal acceleration techniques, at the heart of the \emph{Catalyst} and \emph{Accelerated Hybrid Proximal Extragradient} frameworks, using similar algorithmic patterns. Common acceleration techniques directly rely on the knowledge of some regularity parameters of the problem at hand, and we conclude by discussing \emph{restart} schemes, a set of simple techniques to reach nearly optimal convergence rates while adapting to unobserved regularity parameters.
Average-case Acceleration for Bilinear Games and Normal Matrices
Oct 05, 2020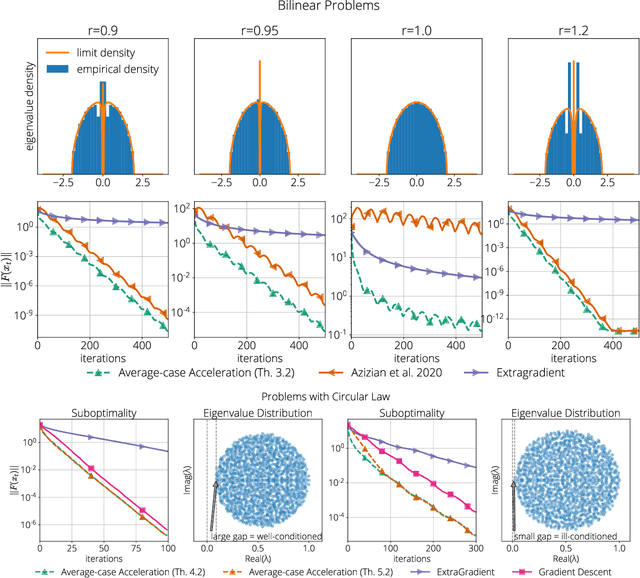
Advances in generative modeling and adversarial learning have given rise to renewed interest in smooth games. However, the absence of symmetry in the matrix of second derivatives poses challenges that are not present in the classical minimization framework. While a rich theory of average-case analysis has been developed for minimization problems, little is known in the context of smooth games. In this work we take a first step towards closing this gap by developing average-case optimal first-order methods for a subset of smooth games. We make the following three main contributions. First, we show that for zero-sum bilinear games the average-case optimal method is the optimal method for the minimization of the Hamiltonian. Second, we provide an explicit expression for the optimal method corresponding to normal matrices, potentially non-symmetric. Finally, we specialize it to matrices with eigenvalues located in a disk and show a provable speed-up compared to worst-case optimal algorithms. We illustrate our findings through benchmarks with a varying degree of mismatch with our assumptions.