 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe global convergence time of stochastic gradient descent in non-convex landscapes: Sharp estimates via large deviations
Mar 20, 2025In this paper, we examine the time it takes for stochastic gradient descent (SGD) to reach the global minimum of a general, non-convex loss function. We approach this question through the lens of randomly perturbed dynamical systems and large deviations theory, and we provide a tight characterization of the global convergence time of SGD via matching upper and lower bounds. These bounds are dominated by the most "costly" set of obstacles that the algorithm may need to overcome to reach a global minimizer from a given initialization, coupling in this way the global geometry of the underlying loss landscape with the statistics of the noise entering the process. Finally, motivated by applications to the training of deep neural networks, we also provide a series of refinements and extensions of our analysis for loss functions with shallow local minima.
$\texttt{skwdro}$: a library for Wasserstein distributionally robust machine learning
Oct 28, 2024
We present skwdro, a Python library for training robust machine learning models. The library is based on distributionally robust optimization using optimal transport distances. For ease of use, it features both scikit-learn compatible estimators for popular objectives, as well as a wrapper for PyTorch modules, enabling researchers and practitioners to use it in a wide range of models with minimal code changes. Its implementation relies on an entropic smoothing of the original robust objective in order to ensure maximal model flexibility. The library is available at https://github.com/iutzeler/skwdro
What is the long-run distribution of stochastic gradient descent? A large deviations analysis
Jun 13, 2024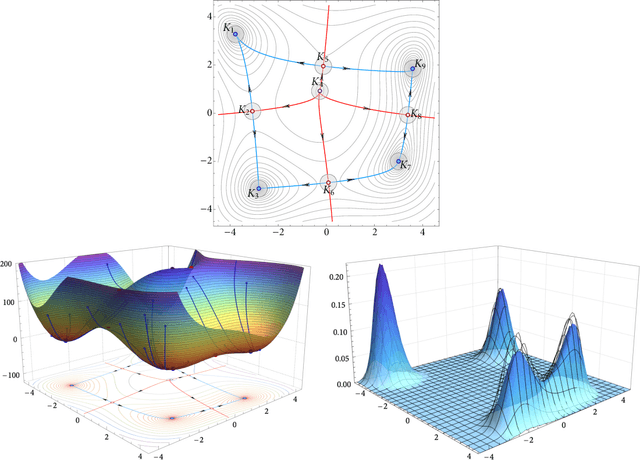
In this paper, we examine the long-run distribution of stochastic gradient descent (SGD) in general, non-convex problems. Specifically, we seek to understand which regions of the problem's state space are more likely to be visited by SGD, and by how much. Using an approach based on the theory of large deviations and randomly perturbed dynamical systems, we show that the long-run distribution of SGD resembles the Boltzmann-Gibbs distribution of equilibrium thermodynamics with temperature equal to the method's step-size and energy levels determined by the problem's objective and the statistics of the noise. In particular, we show that, in the long run, (a) the problem's critical region is visited exponentially more often than any non-critical region; (b) the iterates of SGD are exponentially concentrated around the problem's minimum energy state (which does not always coincide with the global minimum of the objective); (c) all other connected components of critical points are visited with frequency that is exponentially proportional to their energy level; and, finally (d) any component of local maximizers or saddle points is "dominated" by a component of local minimizers which is visited exponentially more often.
Automatic Rao-Blackwellization for Sequential Monte Carlo with Belief Propagation
Dec 15, 2023


Exact Bayesian inference on state-space models~(SSM) is in general untractable, and unfortunately, basic Sequential Monte Carlo~(SMC) methods do not yield correct approximations for complex models. In this paper, we propose a mixed inference algorithm that computes closed-form solutions using belief propagation as much as possible, and falls back to sampling-based SMC methods when exact computations fail. This algorithm thus implements automatic Rao-Blackwellization and is even exact for Gaussian tree models.
Exact Generalization Guarantees for (Regularized) Wasserstein Distributionally Robust Models
May 26, 2023Wasserstein distributionally robust estimators have emerged as powerful models for prediction and decision-making under uncertainty. These estimators provide attractive generalization guarantees: the robust objective obtained from the training distribution is an exact upper bound on the true risk with high probability. However, existing guarantees either suffer from the curse of dimensionality, are restricted to specific settings, or lead to spurious error terms. In this paper, we show that these generalization guarantees actually hold on general classes of models, do not suffer from the curse of dimensionality, and can even cover distribution shifts at testing. We also prove that these results carry over to the newly-introduced regularized versions of Wasserstein distributionally robust problems.
On the rate of convergence of Bregman proximal methods in constrained variational inequalities
Nov 15, 2022We examine the last-iterate convergence rate of Bregman proximal methods - from mirror descent to mirror-prox - in constrained variational inequalities. Our analysis shows that the convergence speed of a given method depends sharply on the Legendre exponent of the underlying Bregman regularizer (Euclidean, entropic, or other), a notion that measures the growth rate of said regularizer near a solution. In particular, we show that boundary solutions exhibit a clear separation of regimes between methods with a zero and non-zero Legendre exponent respectively, with linear convergence for the former versus sublinear for the latter. This dichotomy becomes even more pronounced in linearly constrained problems where, specifically, Euclidean methods converge along sharp directions in a finite number of steps, compared to a linear rate for entropic methods.
The Last-Iterate Convergence Rate of Optimistic Mirror Descent in Stochastic Variational Inequalities
Jul 05, 2021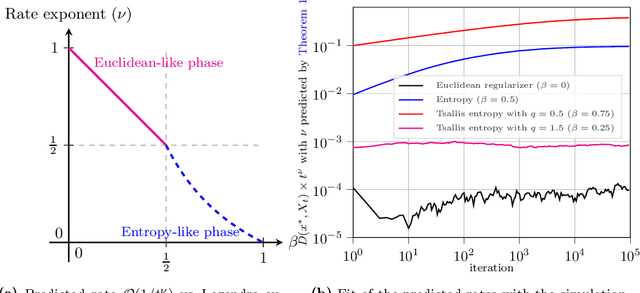
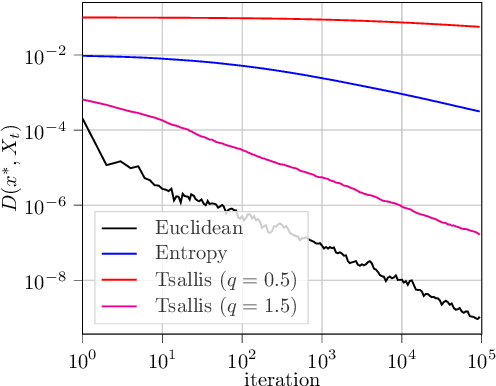
In this paper, we analyze the local convergence rate of optimistic mirror descent methods in stochastic variational inequalities, a class of optimization problems with important applications to learning theory and machine learning. Our analysis reveals an intricate relation between the algorithm's rate of convergence and the local geometry induced by the method's underlying Bregman function. We quantify this relation by means of the Legendre exponent, a notion that we introduce to measure the growth rate of the Bregman divergence relative to the ambient norm near a solution. We show that this exponent determines both the optimal step-size policy of the algorithm and the optimal rates attained, explaining in this way the differences observed for some popular Bregman functions (Euclidean projection, negative entropy, fractional power, etc.).
Characterizing the Expressive Power of Invariant and Equivariant Graph Neural Networks
Jun 28, 2020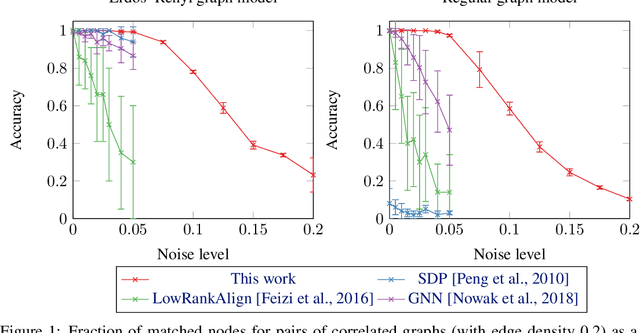

Various classes of Graph Neural Networks (GNN) have been proposed and shown to be successful in a wide range of applications with graph structured data. In this paper, we propose a theoretical framework able to compare the expressive power of these GNN architectures. The current universality theorems only apply to intractable classes of GNNs. Here, we prove the first approximation guarantees for practical GNNs, paving the way for a better understanding of their generalization. Our theoretical results are proved for invariant GNNs computing a graph embedding (permutation of the nodes of the input graph does not affect the output) and equivariant GNNs computing an embedding of the nodes (permutation of the input permutes the output). We show that Folklore Graph Neural Networks (FGNN), which are tensor based GNNs augmented with matrix multiplication are the most expressive architectures proposed so far for a given tensor order. We illustrate our results on the Quadratic Assignment Problem (a NP-Hard combinatorial problem) by showing that FGNNs are able to learn how to solve the problem, leading to much better average performances than existing algorithms (based on spectral, SDP or other GNNs architectures). On a practical side, we also implement masked tensors to handle batches of graphs of varying sizes.
Accelerating Smooth Games by Manipulating Spectral Shapes
Jan 02, 2020
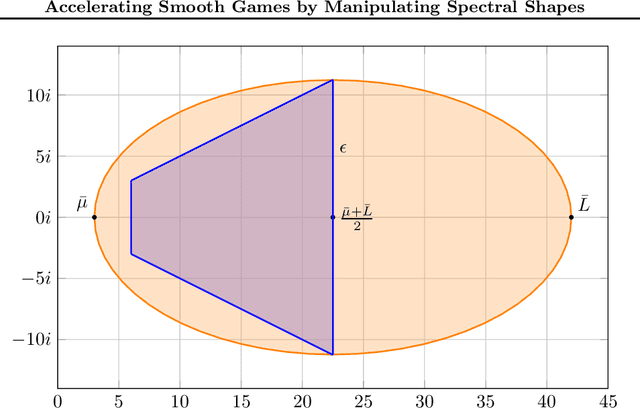
We use matrix iteration theory to characterize acceleration in smooth games. We define the spectral shape of a family of games as the set containing all eigenvalues of the Jacobians of standard gradient dynamics in the family. Shapes restricted to the real line represent well-understood classes of problems, like minimization. Shapes spanning the complex plane capture the added numerical challenges in solving smooth games. In this framework, we describe gradient-based methods, such as extragradient, as transformations on the spectral shape. Using this perspective, we propose an optimal algorithm for bilinear games. For smooth and strongly monotone operators, we identify a continuum between convex minimization, where acceleration is possible using Polyak's momentum, and the worst case where gradient descent is optimal. Finally, going beyond first-order methods, we propose an accelerated version of consensus optimization.
A Tight and Unified Analysis of Extragradient for a Whole Spectrum of Differentiable Games
Jun 24, 2019

We consider differentiable games: multi-objective minimization problems, where the goal is to find a Nash equilibrium. The machine learning community has recently started using extrapolation-based variants of the gradient method. A prime example is the extragradient, which yields linear convergence in cases like bilinear games, where the standard gradient method fails. The full benefits of extrapolation-based methods are not known: i) there is no unified analysis for a large class of games that includes both strongly monotone and bilinear games; ii) it is not known whether the rate achieved by extragradient can be improved, e.g. by considering multiple extrapolation steps. We answer these questions through new analysis of the extragradient's local and global convergence properties. Our analysis covers the whole range of settings between purely bilinear and strongly monotone games. It reveals that extragradient converges via different mechanisms at these extremes; in between, it exploits the most favorable mechanism for the given problem. We then present lower bounds on the rate of convergence for a wide class of algorithms with any number of extrapolations. Our bounds prove that the extragradient achieves the optimal rate in this class, and that our upper bounds are tight. Our precise characterization of the extragradient's convergence behavior in games shows that, unlike in convex optimization, the extragradient method may be much faster than the gradient method.