 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Optimistic Ascent (PI Control) is the Augmented Lagrangian Method in Disguise
Sep 26, 2025Constrained optimization is a powerful framework for enforcing requirements on neural networks. These constrained deep learning problems are typically solved using first-order methods on their min-max Lagrangian formulation, but such approaches often suffer from oscillations and can fail to find all local solutions. While the Augmented Lagrangian method (ALM) addresses these issues, practitioners often favor dual optimistic ascent schemes (PI control) on the standard Lagrangian, which perform well empirically but lack formal guarantees. In this paper, we establish a previously unknown equivalence between these approaches: dual optimistic ascent on the Lagrangian is equivalent to gradient descent-ascent on the Augmented Lagrangian. This finding allows us to transfer the robust theoretical guarantees of the ALM to the dual optimistic setting, proving it converges linearly to all local solutions. Furthermore, the equivalence provides principled guidance for tuning the optimism hyper-parameter. Our work closes a critical gap between the empirical success of dual optimistic methods and their theoretical foundation.
Bias Analysis in Unconditional Image Generative Models
Jun 10, 2025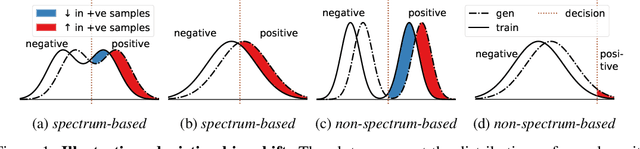
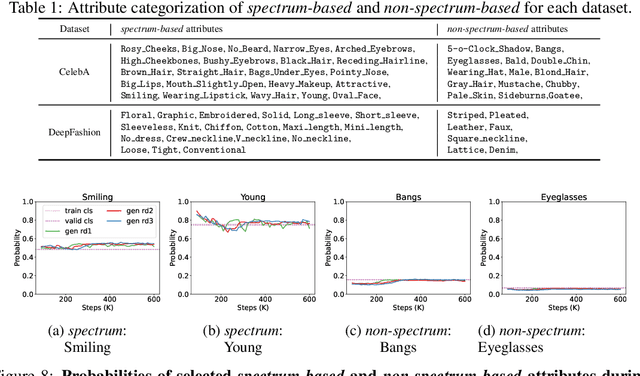
The widespread adoption of generative AI models has raised growing concerns about representational harm and potential discriminatory outcomes. Yet, despite growing literature on this topic, the mechanisms by which bias emerges - especially in unconditional generation - remain disentangled. We define the bias of an attribute as the difference between the probability of its presence in the observed distribution and its expected proportion in an ideal reference distribution. In our analysis, we train a set of unconditional image generative models and adopt a commonly used bias evaluation framework to study bias shift between training and generated distributions. Our experiments reveal that the detected attribute shifts are small. We find that the attribute shifts are sensitive to the attribute classifier used to label generated images in the evaluation framework, particularly when its decision boundaries fall in high-density regions. Our empirical analysis indicates that this classifier sensitivity is often observed in attributes values that lie on a spectrum, as opposed to exhibiting a binary nature. This highlights the need for more representative labeling practices, understanding the shortcomings through greater scrutiny of evaluation frameworks, and recognizing the socially complex nature of attributes when evaluating bias.
Position: Adopt Constraints Over Penalties in Deep Learning
May 27, 2025Recent efforts toward developing trustworthy AI systems with accountability guarantees have led to a growing reliance on machine learning formulations that incorporate external requirements, or constraints. These requirements are often enforced through penalization--adding fixed-weight terms to the task loss. We argue that this approach is ill-suited, and that tailored constrained optimization methods should be adopted instead. In particular, no penalty coefficient may yield a solution that both satisfies the constraints and achieves good performance--i.e., one solving the constrained problem. Moreover, tuning these coefficients is costly, incurring significant time and computational overhead. In contrast, tailored constrained methods--such as the Lagrangian approach, which optimizes the penalization "coefficients" (the Lagrange multipliers) alongside the model--(i) truly solve the constrained problem and add accountability, (ii) eliminate the need for extensive penalty tuning, and (iii) integrate seamlessly with modern deep learning pipelines.
Cooper: A Library for Constrained Optimization in Deep Learning
Apr 01, 2025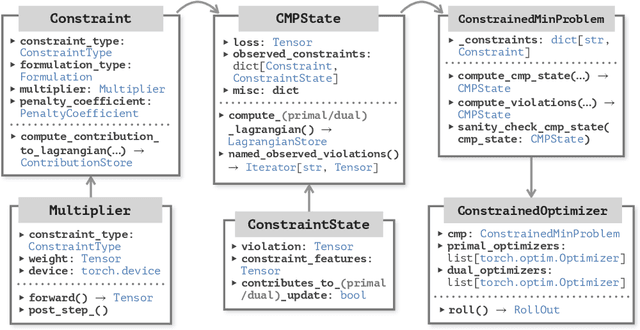
Cooper is an open-source package for solving constrained optimization problems involving deep learning models. Cooper implements several Lagrangian-based first-order update schemes, making it easy to combine constrained optimization algorithms with high-level features of PyTorch such as automatic differentiation, and specialized deep learning architectures and optimizers. Although Cooper is specifically designed for deep learning applications where gradients are estimated based on mini-batches, it is suitable for general non-convex continuous constrained optimization. Cooper's source code is available at https://github.com/cooper-org/cooper.
Feasible Learning
Jan 24, 2025We introduce Feasible Learning (FL), a sample-centric learning paradigm where models are trained by solving a feasibility problem that bounds the loss for each training sample. In contrast to the ubiquitous Empirical Risk Minimization (ERM) framework, which optimizes for average performance, FL demands satisfactory performance on every individual data point. Since any model that meets the prescribed performance threshold is a valid FL solution, the choice of optimization algorithm and its dynamics play a crucial role in shaping the properties of the resulting solutions. In particular, we study a primal-dual approach which dynamically re-weights the importance of each sample during training. To address the challenge of setting a meaningful threshold in practice, we introduce a relaxation of FL that incorporates slack variables of minimal norm. Our empirical analysis, spanning image classification, age regression, and preference optimization in large language models, demonstrates that models trained via FL can learn from data while displaying improved tail behavior compared to ERM, with only a marginal impact on average performance.
Tight Lower Bounds and Improved Convergence in Performative Prediction
Dec 04, 2024Performative prediction is a framework accounting for the shift in the data distribution induced by the prediction of a model deployed in the real world. Ensuring rapid convergence to a stable solution where the data distribution remains the same after the model deployment is crucial, especially in evolving environments. This paper extends the Repeated Risk Minimization (RRM) framework by utilizing historical datasets from previous retraining snapshots, yielding a class of algorithms that we call Affine Risk Minimizers and enabling convergence to a performatively stable point for a broader class of problems. We introduce a new upper bound for methods that use only the final iteration of the dataset and prove for the first time the tightness of both this new bound and the previous existing bounds within the same regime. We also prove that utilizing historical datasets can surpass the lower bound for last iterate RRM, and empirically observe faster convergence to the stable point on various performative prediction benchmarks. We offer at the same time the first lower bound analysis for RRM within the class of Affine Risk Minimizers, quantifying the potential improvements in convergence speed that could be achieved with other variants in our framework.
Understanding Adam Requires Better Rotation Dependent Assumptions
Oct 25, 2024



Despite its widespread adoption, Adam's advantage over Stochastic Gradient Descent (SGD) lacks a comprehensive theoretical explanation. This paper investigates Adam's sensitivity to rotations of the parameter space. We demonstrate that Adam's performance in training transformers degrades under random rotations of the parameter space, indicating a crucial sensitivity to the choice of basis. This reveals that conventional rotation-invariant assumptions are insufficient to capture Adam's advantages theoretically. To better understand the rotation-dependent properties that benefit Adam, we also identify structured rotations that preserve or even enhance its empirical performance. We then examine the rotation-dependent assumptions in the literature, evaluating their adequacy in explaining Adam's behavior across various rotation types. This work highlights the need for new, rotation-dependent theoretical frameworks to fully understand Adam's empirical success in modern machine learning tasks.
Accelerating Training with Neuron Interaction and Nowcasting Networks
Sep 06, 2024



Neural network training can be accelerated when a learnable update rule is used in lieu of classic adaptive optimizers (e.g. Adam). However, learnable update rules can be costly and unstable to train and use. A simpler recently proposed approach to accelerate training is to use Adam for most of the optimization steps and periodically, only every few steps, nowcast (predict future) parameters. We improve this approach by Neuron interaction and Nowcasting (NiNo) networks. NiNo leverages neuron connectivity and graph neural networks to more accurately nowcast parameters by learning in a supervised way from a set of training trajectories over multiple tasks. We show that in some networks, such as Transformers, neuron connectivity is non-trivial. By accurately modeling neuron connectivity, we allow NiNo to accelerate Adam training by up to 50\% in vision and language tasks.
Performative Prediction on Games and Mechanism Design
Aug 09, 2024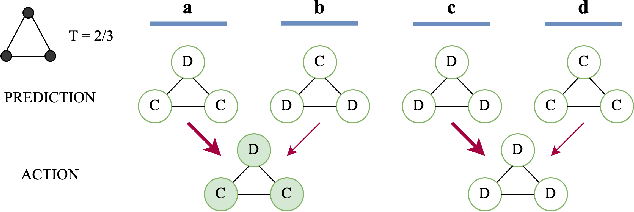
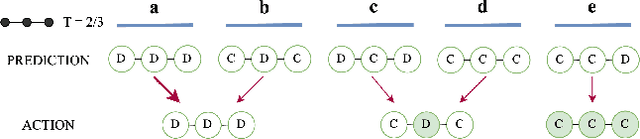
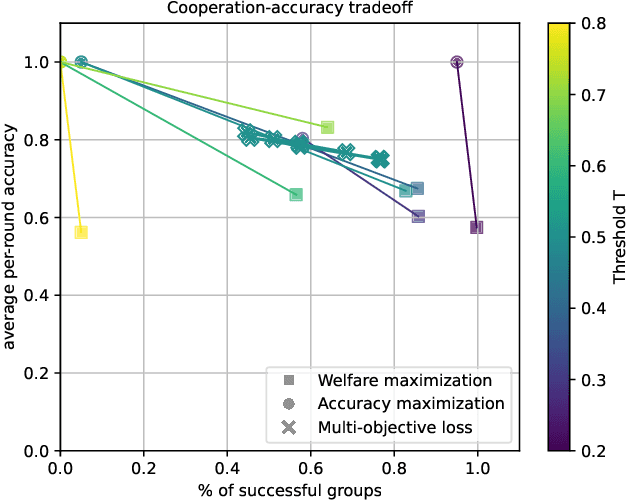
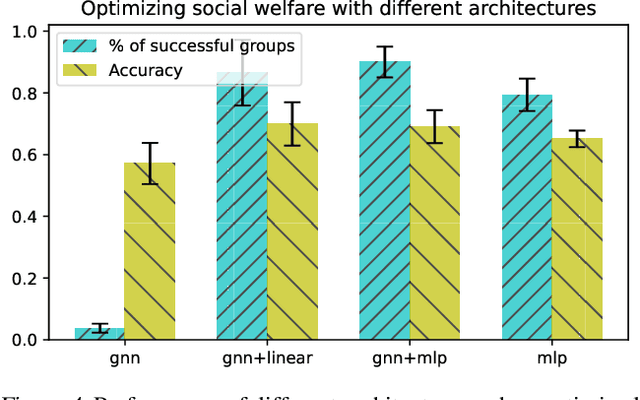
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.
On PI Controllers for Updating Lagrange Multipliers in Constrained Optimization
Jun 07, 2024Constrained optimization offers a powerful framework to prescribe desired behaviors in neural network models. Typically, constrained problems are solved via their min-max Lagrangian formulations, which exhibit unstable oscillatory dynamics when optimized using gradient descent-ascent. The adoption of constrained optimization techniques in the machine learning community is currently limited by the lack of reliable, general-purpose update schemes for the Lagrange multipliers. This paper proposes the $\nu$PI algorithm and contributes an optimization perspective on Lagrange multiplier updates based on PI controllers, extending the work of Stooke, Achiam and Abbeel (2020). We provide theoretical and empirical insights explaining the inability of momentum methods to address the shortcomings of gradient descent-ascent, and contrast this with the empirical success of our proposed $\nu$PI controller. Moreover, we prove that $\nu$PI generalizes popular momentum methods for single-objective minimization. Our experiments demonstrate that $\nu$PI reliably stabilizes the multiplier dynamics and its hyperparameters enjoy robust and predictable behavior.