 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLoRA: Unpacking Bias Mitigation in Vision Models with Fairness-Driven Low-Rank Adaptation
Oct 22, 2024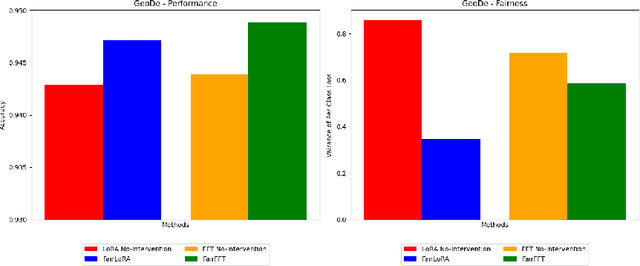


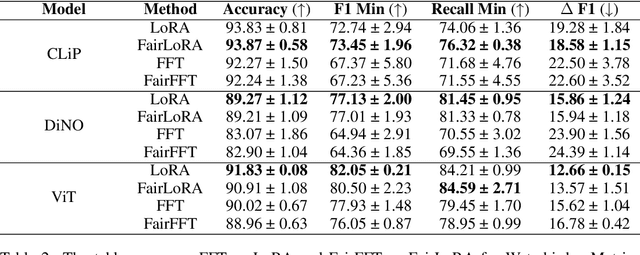
Recent advances in parameter-efficient fine-tuning methods, such as Low Rank Adaptation (LoRA), have gained significant attention for their ability to efficiently adapt large foundational models to various downstream tasks. These methods are appreciated for achieving performance comparable to full fine-tuning on aggregate-level metrics, while significantly reducing computational costs. To systematically address fairness in LLMs previous studies fine-tune on fairness specific data using a larger LoRA rank than typically used. In this paper, we introduce FairLoRA, a novel fairness-specific regularizer for LoRA aimed at reducing performance disparities across data subgroups by minimizing per-class variance in loss. To the best of our knowledge, we are the first to introduce a fairness based finetuning through LoRA. Our results demonstrate that the need for higher ranks to mitigate bias is not universal; it depends on factors such as the pre-trained model, dataset, and task. More importantly, we systematically evaluate FairLoRA across various vision models, including ViT, DiNO, and CLIP, in scenarios involving distribution shifts. We further emphasize the necessity of using multiple fairness metrics to obtain a holistic assessment of fairness, rather than relying solely on the metric optimized during training.
Balancing Act: Constraining Disparate Impact in Sparse Models
Oct 31, 2023

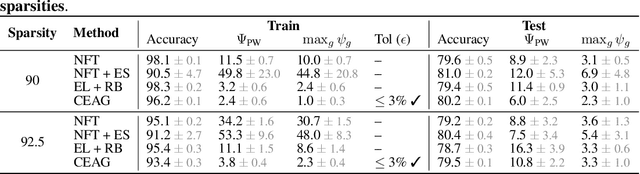

Model pruning is a popular approach to enable the deployment of large deep learning models on edge devices with restricted computational or storage capacities. Although sparse models achieve performance comparable to that of their dense counterparts at the level of the entire dataset, they exhibit high accuracy drops for some data sub-groups. Existing methods to mitigate this disparate impact induced by pruning (i) rely on surrogate metrics that address the problem indirectly and have limited interpretability; or (ii) scale poorly with the number of protected sub-groups in terms of computational cost. We propose a constrained optimization approach that $\textit{directly addresses the disparate impact of pruning}$: our formulation bounds the accuracy change between the dense and sparse models, for each sub-group. This choice of constraints provides an interpretable success criterion to determine if a pruned model achieves acceptable disparity levels. Experimental results demonstrate that our technique scales reliably to problems involving large models and hundreds of protected sub-groups.
Omega: Optimistic EMA Gradients
Jun 13, 2023Stochastic min-max optimization has gained interest in the machine learning community with the advancements in GANs and adversarial training. Although game optimization is fairly well understood in the deterministic setting, some issues persist in the stochastic regime. Recent work has shown that stochastic gradient descent-ascent methods such as the optimistic gradient are highly sensitive to noise or can fail to converge. Although alternative strategies exist, they can be prohibitively expensive. We introduce Omega, a method with optimistic-like updates that mitigates the impact of noise by incorporating an EMA of historic gradients in its update rule. We also explore a variation of this algorithm that incorporates momentum. Although we do not provide convergence guarantees, our experiments on stochastic games show that Omega outperforms the optimistic gradient method when applied to linear players.
Offense Detection in Dravidian Languages using Code-Mixing Index based Focal Loss
Nov 12, 2021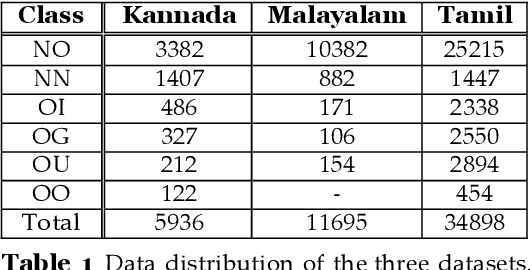
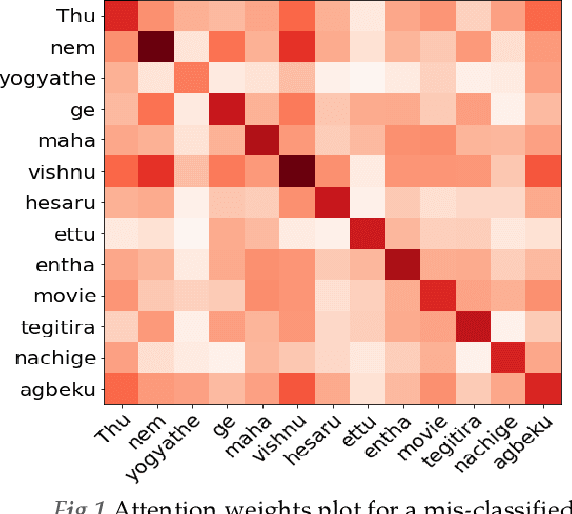
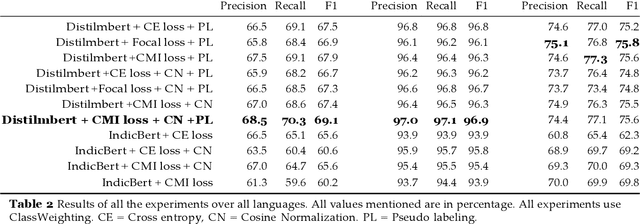
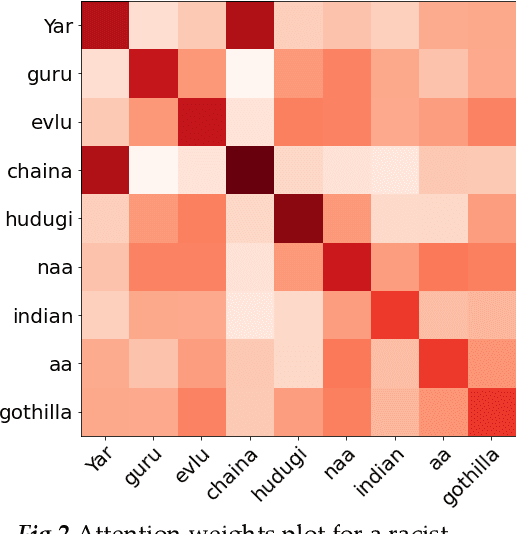
Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product-based classifier with the cosine-based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting.
Can Self Reported Symptoms Predict Daily COVID-19 Cases?
May 18, 2021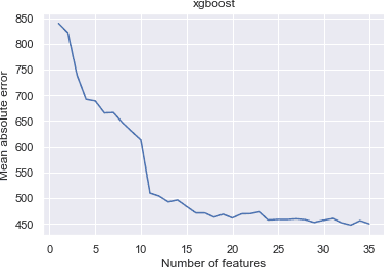
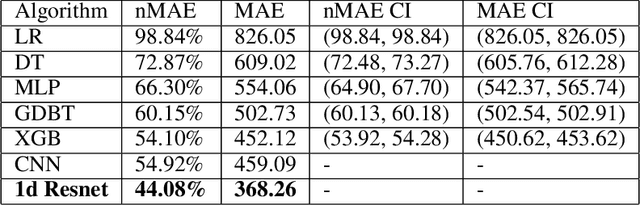
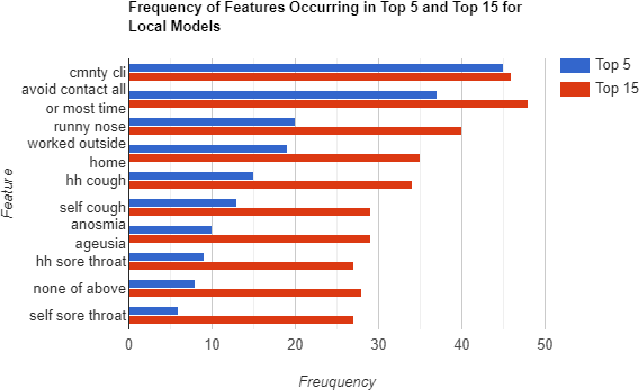

The COVID-19 pandemic has impacted lives and economies across the globe, leading to many deaths. While vaccination is an important intervention, its roll-out is slow and unequal across the globe. Therefore, extensive testing still remains one of the key methods to monitor and contain the virus. Testing on a large scale is expensive and arduous. Hence, we need alternate methods to estimate the number of cases. Online surveys have been shown to be an effective method for data collection amidst the pandemic. In this work, we develop machine learning models to estimate the prevalence of COVID-19 using self-reported symptoms. Our best model predicts the daily cases with a mean absolute error (MAE) of 226.30 (normalized MAE of 27.09%) per state, which demonstrates the possibility of predicting the actual number of confirmed cases by utilizing self-reported symptoms. The models are developed at two levels of data granularity - local models, which are trained at the state level, and a single global model which is trained on the combined data aggregated across all states. Our results indicate a lower error on the local models as opposed to the global model. In addition, we also show that the most important symptoms (features) vary considerably from state to state. This work demonstrates that the models developed on crowd-sourced data, curated via online platforms, can complement the existing epidemiological surveillance infrastructure in a cost-effective manner.
Improved Customer Transaction Classification using Semi-Supervised Knowledge Distillation
Feb 15, 2021
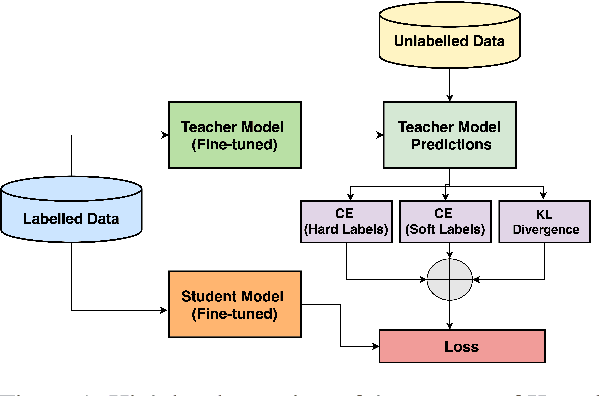
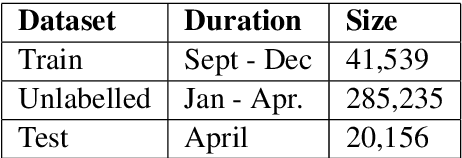
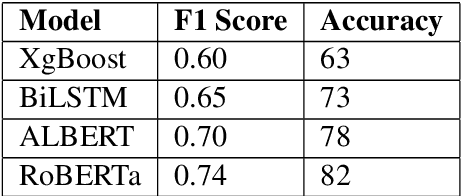
In pickup and delivery services, transaction classification based on customer provided free text is a challenging problem. It involves the association of a wide variety of customer inputs to a fixed set of categories while adapting to the various customer writing styles. This categorization is important for the business: it helps understand the market needs and trends, and also assist in building a personalized experience for different segments of the customers. Hence, it is vital to capture these category information trends at scale, with high precision and recall. In this paper, we focus on a specific use-case where a single category drives each transaction. We propose a cost-effective transaction classification approach based on semi-supervision and knowledge distillation frameworks. The approach identifies the category of a transaction using free text input given by the customer. We use weak labelling and notice that the performance gains are similar to that of using human-annotated samples. On a large internal dataset and on 20Newsgroup dataset, we see that RoBERTa performs the best for the categorization tasks. Further, using an ALBERT model (it has 33x fewer parameters vis-a-vis parameters of RoBERTa), with RoBERTa as the Teacher, we see a performance similar to that of RoBERTa and better performance over unadapted ALBERT. This framework, with ALBERT as a student and RoBERTa as teacher, is further referred to as R-ALBERT in this paper. The model is in production and is used by business to understand changing trends and take appropriate decisions.
Hostility Detection and Covid-19 Fake News Detection in Social Media
Jan 15, 2021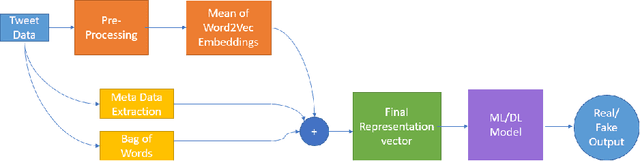
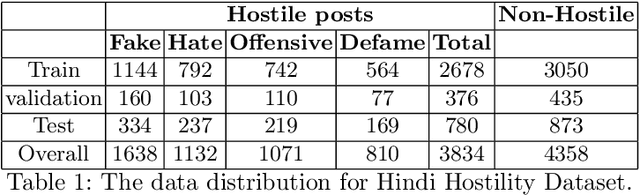

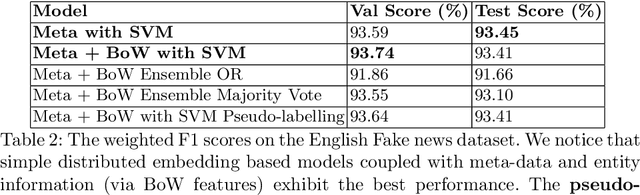
Withtheadventofsocialmedia,therehasbeenanextremely rapid increase in the content shared online. Consequently, the propagation of fake news and hostile messages on social media platforms has also skyrocketed. In this paper, we address the problem of detecting hostile and fake content in the Devanagari (Hindi) script as a multi-class, multi-label problem. Using NLP techniques, we build a model that makes use of an abusive language detector coupled with features extracted via Hindi BERT and Hindi FastText models and metadata. Our model achieves a 0.97 F1 score on coarse grain evaluation on Hostility detection task. Additionally, we built models to identify fake news related to Covid-19 in English tweets. We leverage entity information extracted from the tweets along with textual representations learned from word embeddings and achieve a 0.93 F1 score on the English fake news detection task.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020
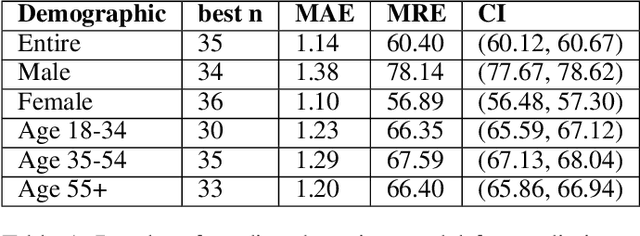
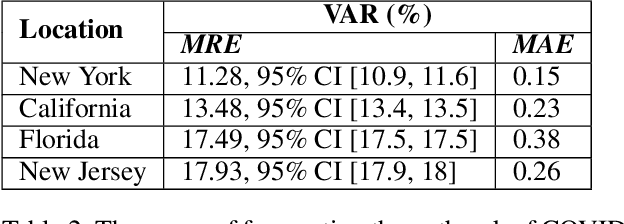
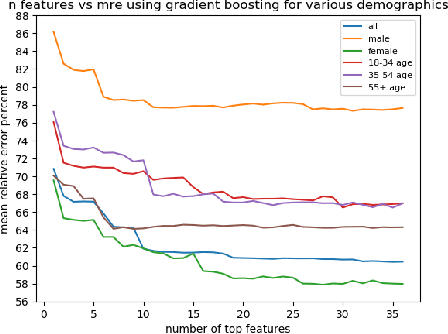
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.