 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Adopt Constraints Over Penalties in Deep Learning
May 27, 2025Recent efforts toward developing trustworthy AI systems with accountability guarantees have led to a growing reliance on machine learning formulations that incorporate external requirements, or constraints. These requirements are often enforced through penalization--adding fixed-weight terms to the task loss. We argue that this approach is ill-suited, and that tailored constrained optimization methods should be adopted instead. In particular, no penalty coefficient may yield a solution that both satisfies the constraints and achieves good performance--i.e., one solving the constrained problem. Moreover, tuning these coefficients is costly, incurring significant time and computational overhead. In contrast, tailored constrained methods--such as the Lagrangian approach, which optimizes the penalization "coefficients" (the Lagrange multipliers) alongside the model--(i) truly solve the constrained problem and add accountability, (ii) eliminate the need for extensive penalty tuning, and (iii) integrate seamlessly with modern deep learning pipelines.
Cooper: A Library for Constrained Optimization in Deep Learning
Apr 01, 2025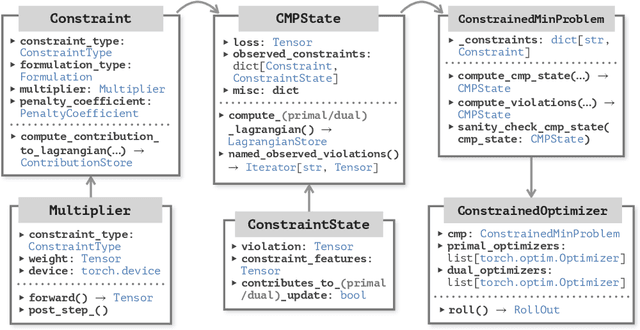
Cooper is an open-source package for solving constrained optimization problems involving deep learning models. Cooper implements several Lagrangian-based first-order update schemes, making it easy to combine constrained optimization algorithms with high-level features of PyTorch such as automatic differentiation, and specialized deep learning architectures and optimizers. Although Cooper is specifically designed for deep learning applications where gradients are estimated based on mini-batches, it is suitable for general non-convex continuous constrained optimization. Cooper's source code is available at https://github.com/cooper-org/cooper.
Feasible Learning
Jan 24, 2025We introduce Feasible Learning (FL), a sample-centric learning paradigm where models are trained by solving a feasibility problem that bounds the loss for each training sample. In contrast to the ubiquitous Empirical Risk Minimization (ERM) framework, which optimizes for average performance, FL demands satisfactory performance on every individual data point. Since any model that meets the prescribed performance threshold is a valid FL solution, the choice of optimization algorithm and its dynamics play a crucial role in shaping the properties of the resulting solutions. In particular, we study a primal-dual approach which dynamically re-weights the importance of each sample during training. To address the challenge of setting a meaningful threshold in practice, we introduce a relaxation of FL that incorporates slack variables of minimal norm. Our empirical analysis, spanning image classification, age regression, and preference optimization in large language models, demonstrates that models trained via FL can learn from data while displaying improved tail behavior compared to ERM, with only a marginal impact on average performance.
Balancing Act: Constraining Disparate Impact in Sparse Models
Oct 31, 2023

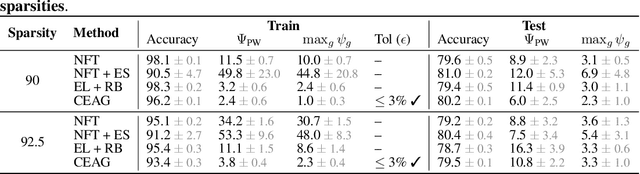

Model pruning is a popular approach to enable the deployment of large deep learning models on edge devices with restricted computational or storage capacities. Although sparse models achieve performance comparable to that of their dense counterparts at the level of the entire dataset, they exhibit high accuracy drops for some data sub-groups. Existing methods to mitigate this disparate impact induced by pruning (i) rely on surrogate metrics that address the problem indirectly and have limited interpretability; or (ii) scale poorly with the number of protected sub-groups in terms of computational cost. We propose a constrained optimization approach that $\textit{directly addresses the disparate impact of pruning}$: our formulation bounds the accuracy change between the dense and sparse models, for each sub-group. This choice of constraints provides an interpretable success criterion to determine if a pruned model achieves acceptable disparity levels. Experimental results demonstrate that our technique scales reliably to problems involving large models and hundreds of protected sub-groups.
Adaptive Tensor Learning with Tensor Networks
Aug 12, 2020

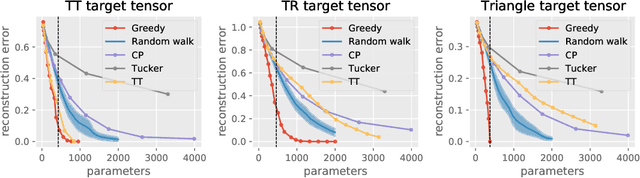
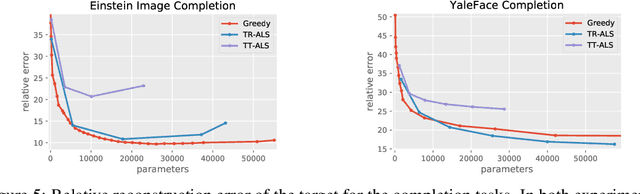
Tensor decomposition techniques have shown great successes in machine learning and data science by extending classical algorithms based on matrix factorization to multi-modal and multi-way data. However, there exist many tensor decomposition models~(CP, Tucker, Tensor Train, etc.) and the rank of such a decomposition is typically a collection of integers rather than a unique number, making model and hyper-parameter selection a tedious and costly task. At the same time, tensor network methods are powerful tools developed in the physics community which have recently shown their potential for machine learning applications and offer a unifying view of the various tensor decomposition models. In this paper, we leverage the tensor network formalism to develop a generic and efficient adaptive algorithm for tensor learning. Our method is based on a simple greedy approach optimizing a differentiable loss function starting from a rank one tensor and successively identifying the most promising tensor network edges for small rank increments. Our algorithm can adaptively identify tensor network structures with small number of parameters that effectively optimize the objective function from data. The framework we introduce is very broad and encompasses many common tensor optimization problems. Experiments on tensor decomposition and tensor completion tasks with both synthetic and real world data demonstrate the effectiveness of the proposed algorithm.