 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposition and Alignment of Diffusion Models using Constrained Learning
Aug 26, 2025Diffusion models have become prevalent in generative modeling due to their ability to sample from complex distributions. To improve the quality of generated samples and their compliance with user requirements, two commonly used methods are: (i) Alignment, which involves fine-tuning a diffusion model to align it with a reward; and (ii) Composition, which combines several pre-trained diffusion models, each emphasizing a desirable attribute in the generated outputs. However, trade-offs often arise when optimizing for multiple rewards or combining multiple models, as they can often represent competing properties. Existing methods cannot guarantee that the resulting model faithfully generates samples with all the desired properties. To address this gap, we propose a constrained optimization framework that unifies alignment and composition of diffusion models by enforcing that the aligned model satisfies reward constraints and/or remains close to (potentially multiple) pre-trained models. We provide a theoretical characterization of the solutions to the constrained alignment and composition problems and develop a Lagrangian-based primal-dual training algorithm to approximate these solutions. Empirically, we demonstrate the effectiveness and merits of our proposed approach in image generation, applying it to alignment and composition, and show that our aligned or composed model satisfies constraints effectively, and improves on the equally-weighted approach. Our implementation can be found at https://github.com/shervinkhalafi/constrained_comp_align.
Infinity Search: Approximate Vector Search with Projections on q-Metric Spaces
Jun 06, 2025Despite the ubiquity of vector search applications, prevailing search algorithms overlook the metric structure of vector embeddings, treating it as a constraint rather than exploiting its underlying properties. In this paper, we demonstrate that in $q$-metric spaces, metric trees can leverage a stronger version of the triangle inequality to reduce comparisons for exact search. Notably, as $q$ approaches infinity, the search complexity becomes logarithmic. Therefore, we propose a novel projection method that embeds vector datasets with arbitrary dissimilarity measures into $q$-metric spaces while preserving the nearest neighbor. We propose to learn an approximation of this projection to efficiently transform query points to a space where euclidean distances satisfy the desired properties. Our experimental results with text and image vector embeddings show that learning $q$-metric approximations enables classic metric tree algorithms -- which typically underperform with high-dimensional data -- to achieve competitive performance against state-of-the-art search methods.
Alignment of large language models with constrained learning
May 26, 2025We study the problem of computing an optimal large language model (LLM) policy for a constrained alignment problem, where the goal is to maximize a primary reward objective while satisfying constraints on secondary utilities. Despite the popularity of Lagrangian-based LLM policy search in constrained alignment, iterative primal-dual methods often fail to converge, and non-iterative dual-based methods do not achieve optimality in the LLM parameter space. To address these challenges, we employ Lagrangian duality to develop an iterative dual-based alignment method that alternates between updating the LLM policy via Lagrangian maximization and updating the dual variable via dual descent. In theory, we characterize the primal-dual gap between the primal value in the distribution space and the dual value in the LLM parameter space. We further quantify the optimality gap of the learned LLM policies at near-optimal dual variables with respect to both the objective and the constraint functions. These results prove that dual-based alignment methods can find an optimal constrained LLM policy, up to an LLM parametrization gap. We demonstrate the effectiveness and merits of our approach through extensive experiments conducted on the PKU-SafeRLHF dataset.
Feasible Learning
Jan 24, 2025We introduce Feasible Learning (FL), a sample-centric learning paradigm where models are trained by solving a feasibility problem that bounds the loss for each training sample. In contrast to the ubiquitous Empirical Risk Minimization (ERM) framework, which optimizes for average performance, FL demands satisfactory performance on every individual data point. Since any model that meets the prescribed performance threshold is a valid FL solution, the choice of optimization algorithm and its dynamics play a crucial role in shaping the properties of the resulting solutions. In particular, we study a primal-dual approach which dynamically re-weights the importance of each sample during training. To address the challenge of setting a meaningful threshold in practice, we introduce a relaxation of FL that incorporates slack variables of minimal norm. Our empirical analysis, spanning image classification, age regression, and preference optimization in large language models, demonstrates that models trained via FL can learn from data while displaying improved tail behavior compared to ERM, with only a marginal impact on average performance.
LoRTA: Low Rank Tensor Adaptation of Large Language Models
Oct 15, 2024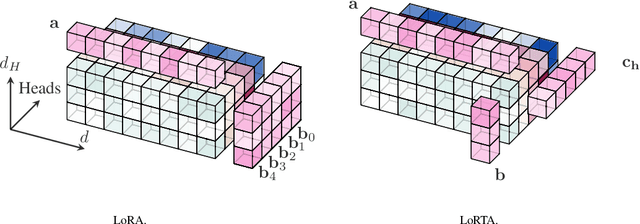

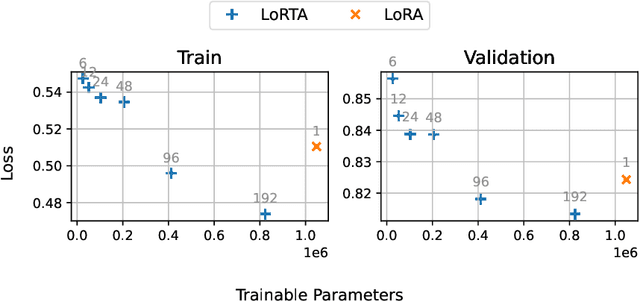

Low Rank Adaptation (LoRA) is a popular Parameter Efficient Fine Tuning (PEFT) method that effectively adapts large pre-trained models for downstream tasks. LoRA parameterizes model updates using low-rank matrices at each layer, significantly reducing the number of trainable parameters and, consequently, resource requirements during fine-tuning. However, the lower bound on the number of trainable parameters remains high due to the use of the low-rank matrix model. In this paper, we address this limitation by proposing a novel approach that employs a low rank tensor parametrization for model updates. The proposed low rank tensor model can significantly reduce the number of trainable parameters, while also allowing for finer-grained control over adapter size. Our experiments on Natural Language Understanding, Instruction Tuning, Preference Optimization and Protein Folding benchmarks demonstrate that our method is both efficient and effective for fine-tuning large language models, achieving a substantial reduction in the number of parameters while maintaining comparable performance.
Loss Shaping Constraints for Long-Term Time Series Forecasting
Feb 14, 2024Several applications in time series forecasting require predicting multiple steps ahead. Despite the vast amount of literature in the topic, both classical and recent deep learning based approaches have mostly focused on minimising performance averaged over the predicted window. We observe that this can lead to disparate distributions of errors across forecasting steps, especially for recent transformer architectures trained on popular forecasting benchmarks. That is, optimising performance on average can lead to undesirably large errors at specific time-steps. In this work, we present a Constrained Learning approach for long-term time series forecasting that aims to find the best model in terms of average performance that respects a user-defined upper bound on the loss at each time-step. We call our approach loss shaping constraints because it imposes constraints on the loss at each time step, and leverage recent duality results to show that despite its non-convexity, the resulting problem has a bounded duality gap. We propose a practical Primal-Dual algorithm to tackle it, and demonstrate that the proposed approach exhibits competitive average performance in time series forecasting benchmarks, while shaping the distribution of errors across the predicted window.
Resilient Constrained Learning
Jun 04, 2023



When deploying machine learning solutions, they must satisfy multiple requirements beyond accuracy, such as fairness, robustness, or safety. These requirements are imposed during training either implicitly, using penalties, or explicitly, using constrained optimization methods based on Lagrangian duality. Either way, specifying requirements is hindered by the presence of compromises and limited prior knowledge about the data. Furthermore, their impact on performance can often only be evaluated by actually solving the learning problem. This paper presents a constrained learning approach that adapts the requirements while simultaneously solving the learning task. To do so, it relaxes the learning constraints in a way that contemplates how much they affect the task at hand by balancing the performance gains obtained from the relaxation against a user-defined cost of that relaxation. We call this approach resilient constrained learning after the term used to describe ecological systems that adapt to disruptions by modifying their operation. We show conditions under which this balance can be achieved and introduce a practical algorithm to compute it, for which we derive approximation and generalization guarantees. We showcase the advantages of this resilient learning method in image classification tasks involving multiple potential invariances and in heterogeneous federated learning.
Neural Networks with Quantization Constraints
Oct 27, 2022Enabling low precision implementations of deep learning models, without considerable performance degradation, is necessary in resource and latency constrained settings. Moreover, exploiting the differences in sensitivity to quantization across layers can allow mixed precision implementations to achieve a considerably better computation performance trade-off. However, backpropagating through the quantization operation requires introducing gradient approximations, and choosing which layers to quantize is challenging for modern architectures due to the large search space. In this work, we present a constrained learning approach to quantization aware training. We formulate low precision supervised learning as a constrained optimization problem, and show that despite its non-convexity, the resulting problem is strongly dual and does away with gradient estimations. Furthermore, we show that dual variables indicate the sensitivity of the objective with respect to constraint perturbations. We demonstrate that the proposed approach exhibits competitive performance in image classification tasks, and leverage the sensitivity result to apply layer selective quantization based on the value of dual variables, leading to considerable performance improvements.
Automatic Data Augmentation via Invariance-Constrained Learning
Sep 29, 2022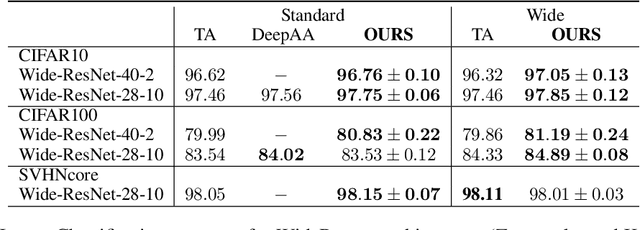


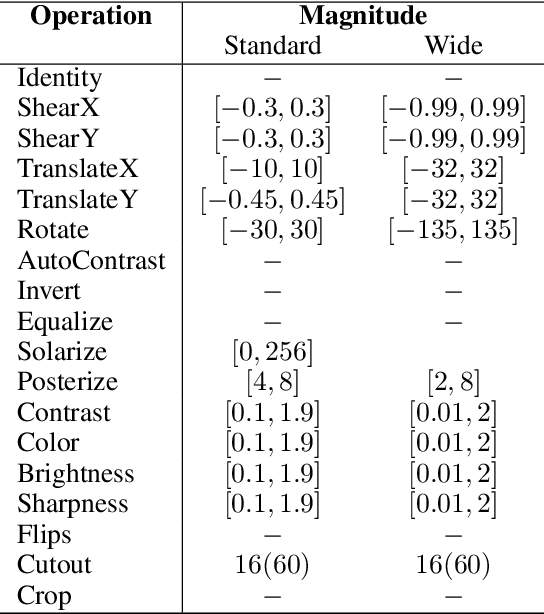
Underlying data structures, such as symmetries or invariances to transformations, are often exploited to improve the solution of learning tasks. However, embedding these properties in models or learning algorithms can be challenging and computationally intensive. Data augmentation, on the other hand, induces these symmetries during training by applying multiple transformations to the input data. Despite its ubiquity, its effectiveness depends on the choices of which transformations to apply, when to do so, and how often. In fact, there is both empirical and theoretical evidence that the indiscriminate use of data augmentation can introduce biases that outweigh its benefits. This work tackles these issues by automatically adapting the data augmentation while solving the learning task. To do so, it formulates data augmentation as an invariance-constrained learning problem and leverages Monte Carlo Markov Chain (MCMC) sampling to solve it. The result is a practical algorithm that not only does away with a priori searches for augmentation distributions, but also dynamically controls if and when data augmentation is applied. Our experiments illustrate the performance of this method, which achieves state-of-the-art results in automatic data augmentation benchmarks for CIFAR datasets. Furthermore, this approach can be used to gather insights on the actual symmetries underlying a learning task.