 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
LoRTA: Low Rank Tensor Adaptation of Large Language Models
Oct 15, 2024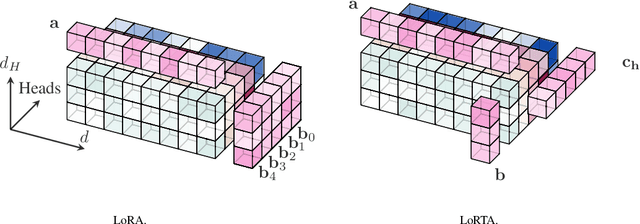

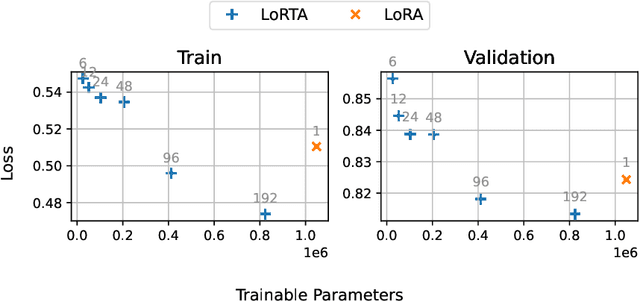

Low Rank Adaptation (LoRA) is a popular Parameter Efficient Fine Tuning (PEFT) method that effectively adapts large pre-trained models for downstream tasks. LoRA parameterizes model updates using low-rank matrices at each layer, significantly reducing the number of trainable parameters and, consequently, resource requirements during fine-tuning. However, the lower bound on the number of trainable parameters remains high due to the use of the low-rank matrix model. In this paper, we address this limitation by proposing a novel approach that employs a low rank tensor parametrization for model updates. The proposed low rank tensor model can significantly reduce the number of trainable parameters, while also allowing for finer-grained control over adapter size. Our experiments on Natural Language Understanding, Instruction Tuning, Preference Optimization and Protein Folding benchmarks demonstrate that our method is both efficient and effective for fine-tuning large language models, achieving a substantial reduction in the number of parameters while maintaining comparable performance.
Deceptive Alignment Monitoring
Jul 26, 2023As the capabilities of large machine learning models continue to grow, and as the autonomy afforded to such models continues to expand, the spectre of a new adversary looms: the models themselves. The threat that a model might behave in a seemingly reasonable manner, while secretly and subtly modifying its behavior for ulterior reasons is often referred to as deceptive alignment in the AI Safety & Alignment communities. Consequently, we call this new direction Deceptive Alignment Monitoring. In this work, we identify emerging directions in diverse machine learning subfields that we believe will become increasingly important and intertwined in the near future for deceptive alignment monitoring, and we argue that advances in these fields present both long-term challenges and new research opportunities. We conclude by advocating for greater involvement by the adversarial machine learning community in these emerging directions.
FACADE: A Framework for Adversarial Circuit Anomaly Detection and Evaluation
Jul 20, 2023
We present FACADE, a novel probabilistic and geometric framework designed for unsupervised mechanistic anomaly detection in deep neural networks. Its primary goal is advancing the understanding and mitigation of adversarial attacks. FACADE aims to generate probabilistic distributions over circuits, which provide critical insights to their contribution to changes in the manifold properties of pseudo-classes, or high-dimensional modes in activation space, yielding a powerful tool for uncovering and combating adversarial attacks. Our approach seeks to improve model robustness, enhance scalable model oversight, and demonstrates promising applications in real-world deployment settings.