 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Feature Importance Scores via Feature Occlusion and Permutation
Feb 09, 2026As machine learning models increasingly impact society, their opaque nature poses challenges to trust and accountability, particularly in fairness contexts. Understanding how individual features influence model outcomes is crucial for building interpretable and equitable models. While feature importance metrics for accuracy are well-established, methods for assessing feature contributions to fairness remain underexplored. We propose two model-agnostic approaches to measure fair feature importance. First, we propose to compare model fairness before and after permuting feature values. This simple intervention-based approach decouples a feature and model predictions to measure its contribution to training. Second, we evaluate the fairness of models trained with and without a given feature. This occlusion-based score enjoys dramatic computational simplification via minipatch learning. Our empirical results reflect the simplicity and effectiveness of our proposed metrics for multiple predictive tasks. Both methods offer simple, scalable, and interpretable solutions to quantify the influence of features on fairness, providing new tools for responsible machine learning development.
Stationarity and Spectral Characterization of Random Signals on Simplicial Complexes
Feb 03, 2026It is increasingly common for data to possess intricate structure, necessitating new models and analytical tools. Graphs, a prominent type of structure, can encode the relationships between any two entities (nodes). However, graphs neither allow connections that are not dyadic nor permit relationships between sets of nodes. We thus turn to simplicial complexes for connecting more than two nodes as well as modeling relationships between simplices, such as edges and triangles. Our data then consist of signals lying on topological spaces, represented by simplicial complexes. Much recent work explores these topological signals, albeit primarily through deterministic formulations. We propose a probabilistic framework for random signals defined on simplicial complexes. Specifically, we generalize the classical notion of stationarity. By spectral dualities of Hodge and Dirac theory, we define stationary topological signals as the outputs of topological filters given white noise. This definition naturally extends desirable properties of stationarity that hold for both time-series and graph signals. Crucially, we properly define topological power spectral density (PSD) through a clear spectral characterization. We then discuss the advantages of topological stationarity due to spectral properties via the PSD. In addition, we empirically demonstrate the practicality of these benefits through multiple synthetic and real-world simulations.
Prior-Informed Flow Matching for Graph Reconstruction
Jan 29, 2026We introduce Prior-Informed Flow Matching (PIFM), a conditional flow model for graph reconstruction. Reconstructing graphs from partial observations remains a key challenge; classical embedding methods often lack global consistency, while modern generative models struggle to incorporate structural priors. PIFM bridges this gap by integrating embedding-based priors with continuous-time flow matching. Grounded in a permutation equivariant version of the distortion-perception theory, our method first uses a prior, such as graphons or GraphSAGE/node2vec, to form an informed initial estimate of the adjacency matrix based on local information. It then applies rectified flow matching to refine this estimate, transporting it toward the true distribution of clean graphs and learning a global coupling. Experiments on different datasets demonstrate that PIFM consistently enhances classical embeddings, outperforming them and state-of-the-art generative baselines in reconstruction accuracy.
Sampling with Shielded Langevin Monte Carlo Using Navigation Potentials
Dec 15, 2025We introduce shielded Langevin Monte Carlo (LMC), a constrained sampler inspired by navigation functions, capable of sampling from unnormalized target distributions defined over punctured supports. In other words, this approach samples from non-convex spaces defined as convex sets with convex holes. This defines a novel and challenging problem in constrained sampling. To do so, the sampler incorporates a combination of a spatially adaptive temperature and a repulsive drift to ensure that samples remain within the feasible region. Experiments on a 2D Gaussian mixture and multiple-input multiple-output (MIMO) symbol detection showcase the advantages of the proposed shielded LMC in contrast to unconstrained cases.
A Differentiable Digital Twin of Distributed Link Scheduling for Contention-Aware Networking
Dec 11, 2025



Many routing and flow optimization problems in wired networks can be solved efficiently using minimum cost flow formulations. However, this approach does not extend to wireless multi-hop networks, where the assumptions of fixed link capacity and linear cost structure collapse due to contention for shared spectrum resources. The key challenge is that the long-term capacity of a wireless link becomes a non-linear function of its network context, including network topology, link quality, and the traffic assigned to neighboring links. In this work, we pursue a new direction of modeling wireless network under randomized medium access control by developing an analytical network digital twin (NDT) that predicts link duty cycles from network context. We generalize randomized contention as finding a Maximal Independent Set (MIS) on the conflict graph using weighted Luby's algorithm, derive an analytical model of link duty cycles, and introduce an iterative procedure that resolves the circular dependency among duty cycle, link capacity, and contention probability. Our numerical experiments show that the proposed NDT accurately predicts link duty cycles and congestion patterns with up to a 5000x speedup over packet-level simulation, and enables us to optimize link scheduling using gradient descent for reduced congestion and radio footprint.
Gromov-Wasserstein Graph Coarsening
Nov 11, 2025We study the problem of graph coarsening within the Gromov-Wasserstein geometry. Specifically, we propose two algorithms that leverage a novel representation of the distortion induced by merging pairs of nodes. The first method, termed Greedy Pair Coarsening (GPC), iteratively merges pairs of nodes that locally minimize a measure of distortion until the desired size is achieved. The second method, termed $k$-means Greedy Pair Coarsening (KGPC), leverages clustering based on pairwise distortion metrics to directly merge clusters of nodes. We provide conditions guaranteeing optimal coarsening for our methods and validate their performance on six large-scale datasets and a downstream clustering task. Results show that the proposed methods outperform existing approaches on a wide range of parameters and scenarios.
Adapting to Heterophilic Graph Data with Structure-Guided Neighbor Discovery
Jun 10, 2025Graph Neural Networks (GNNs) often struggle with heterophilic data, where connected nodes may have dissimilar labels, as they typically assume homophily and rely on local message passing. To address this, we propose creating alternative graph structures by linking nodes with similar structural attributes (e.g., role-based or global), thereby fostering higher label homophily on these new graphs. We theoretically prove that GNN performance can be improved by utilizing graphs with fewer false positive edges (connections between nodes of different classes) and that considering multiple graph views increases the likelihood of finding such beneficial structures. Building on these insights, we introduce Structure-Guided GNN (SG-GNN), an architecture that processes the original graph alongside the newly created structural graphs, adaptively learning to weigh their contributions. Extensive experiments on various benchmark datasets, particularly those with heterophilic characteristics, demonstrate that our SG-GNN achieves state-of-the-art or highly competitive performance, highlighting the efficacy of exploiting structural information to guide GNNs.
Model-Driven Graph Contrastive Learning
Jun 06, 2025We propose $\textbf{MGCL}$, a model-driven graph contrastive learning (GCL) framework that leverages graphons (probabilistic generative models for graphs) to guide contrastive learning by accounting for the data's underlying generative process. GCL has emerged as a powerful self-supervised framework for learning expressive node or graph representations without relying on annotated labels, which are often scarce in real-world data. By contrasting augmented views of graph data, GCL has demonstrated strong performance across various downstream tasks, such as node and graph classification. However, existing methods typically rely on manually designed or heuristic augmentation strategies that are not tailored to the underlying data distribution and operate at the individual graph level, ignoring similarities among graphs generated from the same model. Conversely, in our proposed approach, MGCL first estimates the graphon associated with the observed data and then defines a graphon-informed augmentation process, enabling data-adaptive and principled augmentations. Additionally, for graph-level tasks, MGCL clusters the dataset and estimates a graphon per group, enabling contrastive pairs to reflect shared semantics and structure. Extensive experiments on benchmark datasets demonstrate that MGCL achieves state-of-the-art performance, highlighting the advantages of incorporating generative models into GCL.
Infinity Search: Approximate Vector Search with Projections on q-Metric Spaces
Jun 06, 2025Despite the ubiquity of vector search applications, prevailing search algorithms overlook the metric structure of vector embeddings, treating it as a constraint rather than exploiting its underlying properties. In this paper, we demonstrate that in $q$-metric spaces, metric trees can leverage a stronger version of the triangle inequality to reduce comparisons for exact search. Notably, as $q$ approaches infinity, the search complexity becomes logarithmic. Therefore, we propose a novel projection method that embeds vector datasets with arbitrary dissimilarity measures into $q$-metric spaces while preserving the nearest neighbor. We propose to learn an approximation of this projection to efficiently transform query points to a space where euclidean distances satisfy the desired properties. Our experimental results with text and image vector embeddings show that learning $q$-metric approximations enables classic metric tree algorithms -- which typically underperform with high-dimensional data -- to achieve competitive performance against state-of-the-art search methods.
A Few Moments Please: Scalable Graphon Learning via Moment Matching
Jun 04, 2025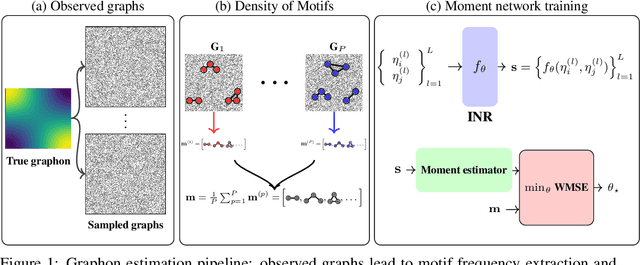
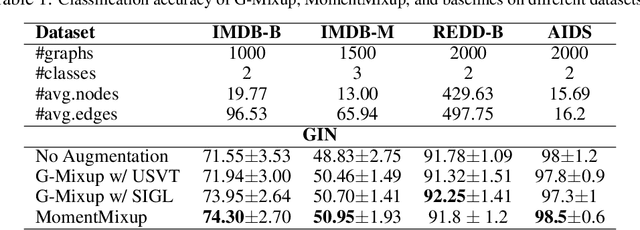
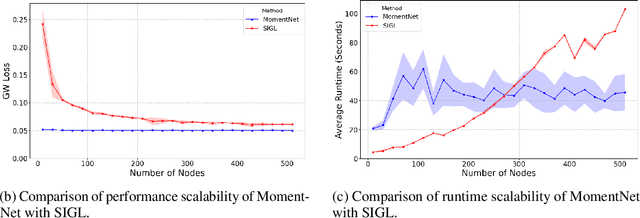
Graphons, as limit objects of dense graph sequences, play a central role in the statistical analysis of network data. However, existing graphon estimation methods often struggle with scalability to large networks and resolution-independent approximation, due to their reliance on estimating latent variables or costly metrics such as the Gromov-Wasserstein distance. In this work, we propose a novel, scalable graphon estimator that directly recovers the graphon via moment matching, leveraging implicit neural representations (INRs). Our approach avoids latent variable modeling by training an INR--mapping coordinates to graphon values--to match empirical subgraph counts (i.e., moments) from observed graphs. This direct estimation mechanism yields a polynomial-time solution and crucially sidesteps the combinatorial complexity of Gromov-Wasserstein optimization. Building on foundational results, we establish a theoretical guarantee: when the observed subgraph motifs sufficiently represent those of the true graphon (a condition met with sufficiently large or numerous graph samples), the estimated graphon achieves a provable upper bound in cut distance from the ground truth. Additionally, we introduce MomentMixup, a data augmentation technique that performs mixup in the moment space to enhance graphon-based learning. Our graphon estimation method achieves strong empirical performance--demonstrating high accuracy on small graphs and superior computational efficiency on large graphs--outperforming state-of-the-art scalable estimators in 75\% of benchmark settings and matching them in the remaining cases. Furthermore, MomentMixup demonstrated improved graph classification accuracy on the majority of our benchmarks.