 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Task Offloading and Routing in Wireless Multi-hop Networks Using Biased Backpressure Algorithm
Dec 19, 2024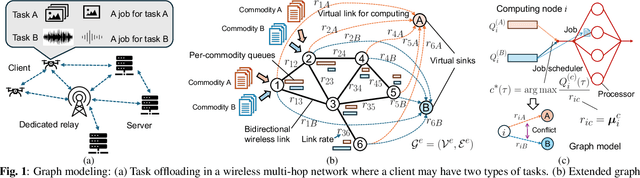
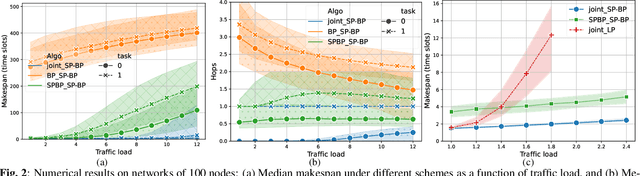
A significant challenge for computation offloading in wireless multi-hop networks is the complex interaction among traffic flows in the presence of interference. Existing approaches often ignore these key effects and/or rely on outdated queueing and channel state information. To fill these gaps, we reformulate joint offloading and routing as a routing problem on an extended graph with physical and virtual links. We adopt the state-of-the-art shortest path-biased Backpressure routing algorithm, which allows the destination and the route of a job to be dynamically adjusted at every time step based on network-wide long-term information and real-time states of local neighborhoods. In large networks, our approach achieves smaller makespan than existing approaches, such as separated Backpressure offloading and joint offloading and routing based on linear programming.
Fully Distributed Online Training of Graph Neural Networks in Networked Systems
Dec 08, 2024


Graph neural networks (GNNs) are powerful tools for developing scalable, decentralized artificial intelligence in large-scale networked systems, such as wireless networks, power grids, and transportation networks. Currently, GNNs in networked systems mostly follow a paradigm of `centralized training, distributed execution', which limits their adaptability and slows down their development cycles. In this work, we fill this gap for the first time by developing a communication-efficient, fully distributed online training approach for GNNs applied to large networked systems. For a mini-batch with $B$ samples, our approach of training an $L$-layer GNN only adds $L$ rounds of message passing to the $LB$ rounds required by GNN inference, with doubled message sizes. Through numerical experiments in graph-based node regression, power allocation, and link scheduling in wireless networks, we demonstrate the effectiveness of our approach in training GNNs under supervised, unsupervised, and reinforcement learning paradigms.
MMBind: Unleashing the Potential of Distributed and Heterogeneous Data for Multimodal Learning in IoT
Nov 18, 2024



Multimodal sensing systems are increasingly prevalent in various real-world applications. Most existing multimodal learning approaches heavily rely on training with a large amount of complete multimodal data. However, such a setting is impractical in real-world IoT sensing applications where data is typically collected by distributed nodes with heterogeneous data modalities, and is also rarely labeled. In this paper, we propose MMBind, a new framework for multimodal learning on distributed and heterogeneous IoT data. The key idea of MMBind is to construct a pseudo-paired multimodal dataset for model training by binding data from disparate sources and incomplete modalities through a sufficiently descriptive shared modality. We demonstrate that data of different modalities observing similar events, even captured at different times and locations, can be effectively used for multimodal training. Moreover, we propose an adaptive multimodal learning architecture capable of training models with heterogeneous modality combinations, coupled with a weighted contrastive learning approach to handle domain shifts among disparate data. Evaluations on ten real-world multimodal datasets highlight that MMBind outperforms state-of-the-art baselines under varying data incompleteness and domain shift, and holds promise for advancing multimodal foundation model training in IoT applications.
Biased Backpressure Routing Using Link Features and Graph Neural Networks
Jul 13, 2024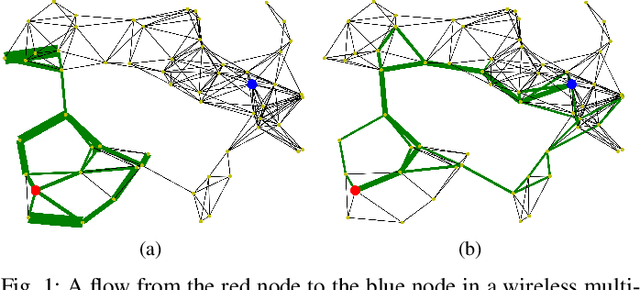

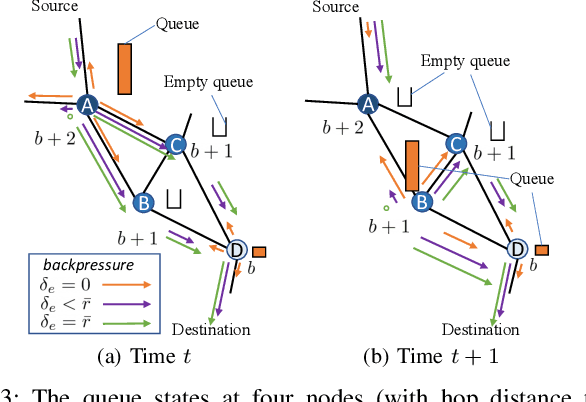

To reduce the latency of Backpressure (BP) routing in wireless multi-hop networks, we propose to enhance the existing shortest path-biased BP (SP-BP) and sojourn time-based backlog metrics, since they introduce no additional time step-wise signaling overhead to the basic BP. Rather than relying on hop-distance, we introduce a new edge-weighted shortest path bias built on the scheduling duty cycle of wireless links, which can be predicted by a graph convolutional neural network based on the topology and traffic of wireless networks. Additionally, we tackle three long-standing challenges associated with SP-BP: optimal bias scaling, efficient bias maintenance, and integration of delay awareness. Our proposed solutions inherit the throughput optimality of the basic BP, as well as its practical advantages of low complexity and fully distributed implementation. Our approaches rely on common link features and introduces only a one-time constant overhead to previous SP-BP schemes, or a one-time overhead linear in the network size to the basic BP. Numerical experiments show that our solutions can effectively address the major drawbacks of slow startup, random walk, and the last packet problem in basic BP, improving the end-to-end delay of existing low-overhead BP algorithms under various settings of network traffic, interference, and mobility.
Distributed and Rate-Adaptive Feature Compression
Apr 02, 2024



We study the problem of distributed and rate-adaptive feature compression for linear regression. A set of distributed sensors collect disjoint features of regressor data. A fusion center is assumed to contain a pretrained linear regression model, trained on a dataset of the entire uncompressed data. At inference time, the sensors compress their observations and send them to the fusion center through communication-constrained channels, whose rates can change with time. Our goal is to design a feature compression {scheme} that can adapt to the varying communication constraints, while maximizing the inference performance at the fusion center. We first obtain the form of optimal quantizers assuming knowledge of underlying regressor data distribution. Under a practically reasonable approximation, we then propose a distributed compression scheme which works by quantizing a one-dimensional projection of the sensor data. We also propose a simple adaptive scheme for handling changes in communication constraints. We demonstrate the effectiveness of the distributed adaptive compression scheme through simulated experiments.
Learning Non-myopic Power Allocation in Constrained Scenarios
Jan 18, 2024

We propose a learning-based framework for efficient power allocation in ad hoc interference networks under episodic constraints. The problem of optimal power allocation -- for maximizing a given network utility metric -- under instantaneous constraints has recently gained significant popularity. Several learnable algorithms have been proposed to obtain fast, effective, and near-optimal performance. However, a more realistic scenario arises when the utility metric has to be optimized for an entire episode under time-coupled constraints. In this case, the instantaneous power needs to be regulated so that the given utility can be optimized over an entire sequence of wireless network realizations while satisfying the constraint at all times. Solving each instance independently will be myopic as the long-term constraint cannot modulate such a solution. Instead, we frame this as a constrained and sequential decision-making problem, and employ an actor-critic algorithm to obtain the constraint-aware power allocation at each step. We present experimental analyses to illustrate the effectiveness of our method in terms of superior episodic network-utility performance and its efficiency in terms of time and computational complexity.
Congestion-aware Distributed Task Offloading in Wireless Multi-hop Networks Using Graph Neural Networks
Dec 05, 2023Computational offloading has become an enabling component for edge intelligence in mobile and smart devices. Existing offloading schemes mainly focus on mobile devices and servers, while ignoring the potential network congestion caused by tasks from multiple mobile devices, especially in wireless multi-hop networks. To fill this gap, we propose a low-overhead, congestion-aware distributed task offloading scheme by augmenting a distributed greedy framework with graph-based machine learning. In simulated wireless multi-hop networks with 20-110 nodes and a resource allocation scheme based on shortest path routing and contention-based link scheduling, our approach is demonstrated to be effective in reducing congestion or unstable queues under the context-agnostic baseline, while improving the execution latency over local computing.
Enhanced Backpressure Routing Using Wireless Link Features
Oct 14, 2023Backpressure (BP) routing is a well-established framework for distributed routing and scheduling in wireless multi-hop networks. However, the basic BP scheme suffers from poor end-to-end delay due to the drawbacks of slow startup, random walk, and the last packet problem. Biased BP with shortest path awareness can address the first two drawbacks, and sojourn time-based backlog metrics were proposed for the last packet problem. Furthermore, these BP variations require no additional signaling overhead in each time step compared to the basic BP. In this work, we further address three long-standing challenges associated with the aforementioned low-cost BP variations, including optimal scaling of the biases, bias maintenance under mobility, and incorporating sojourn time awareness into biased BP. Our analysis and experimental results show that proper scaling of biases can be achieved with the help of common link features, which can effectively reduce end-to-end delay of BP by mitigating the random walk of packets under low-to-medium traffic, including the last packet scenario. In addition, our low-overhead bias maintenance scheme is shown to be effective under mobility, and our bio-inspired sojourn time-aware backlog metric is demonstrated to be more efficient and effective for the last packet problem than existing approaches when incorporated into biased BP.
Learnable Digital Twin for Efficient Wireless Network Evaluation
Jun 11, 2023Network digital twins (NDTs) facilitate the estimation of key performance indicators (KPIs) before physically implementing a network, thereby enabling efficient optimization of the network configuration. In this paper, we propose a learning-based NDT for network simulators. The proposed method offers a holistic representation of information flow in a wireless network by integrating node, edge, and path embeddings. Through this approach, the model is trained to map the network configuration to KPIs in a single forward pass. Hence, it offers a more efficient alternative to traditional simulation-based methods, thus allowing for rapid experimentation and optimization. Our proposed method has been extensively tested through comprehensive experimentation in various scenarios, including wired and wireless networks. Results show that it outperforms baseline learning models in terms of accuracy and robustness. Moreover, our approach achieves comparable performance to simulators but with significantly higher computational efficiency.
Deep Graph Unfolding for Beamforming in MU-MIMO Interference Networks
Apr 02, 2023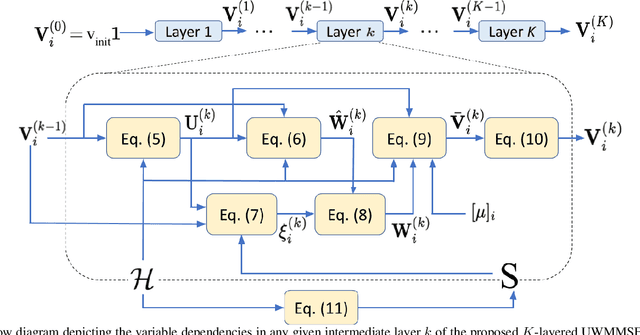
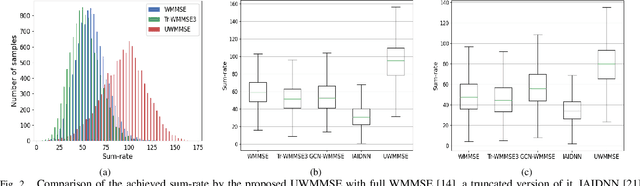
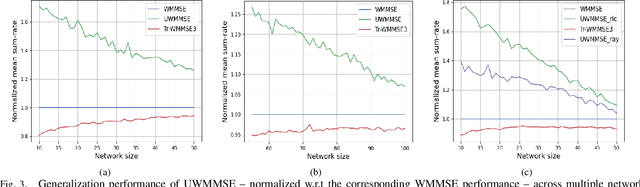
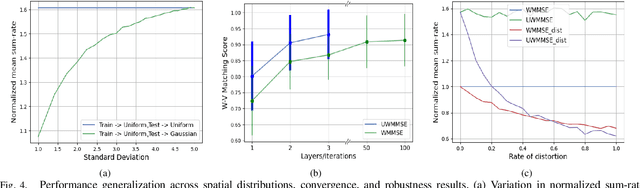
We develop an efficient and near-optimal solution for beamforming in multi-user multiple-input-multiple-output single-hop wireless ad-hoc interference networks. Inspired by the weighted minimum mean squared error (WMMSE) method, a classical approach to solving this problem, and the principle of algorithm unfolding, we present unfolded WMMSE (UWMMSE) for MU-MIMO. This method learns a parameterized functional transformation of key WMMSE parameters using graph neural networks (GNNs), where the channel and interference components of a wireless network constitute the underlying graph. These GNNs are trained through gradient descent on a network utility metric using multiple instances of the beamforming problem. Comprehensive experimental analyses illustrate the superiority of UWMMSE over the classical WMMSE and state-of-the-art learning-based methods in terms of performance, generalizability, and robustness.