 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Explainable Divide-and-Conquer Learning for Intrusion Detection
May 03, 2026Machine learning-based intrusion detection requires complex models to capture patterns in high-dimensional, noisy, and class-imbalanced raw network traffic, yet deploying such models remains impractical on resource-constrained devices with limited processing power and memory. In this paper, we present a correlation-aware divide-and-conquer learning technique that decomposes a complex learning problem into smaller, more manageable subproblems. This enables lightweight models as simple as decision trees to be trained on focused subtasks, yielding up to 43.3% higher local accuracy and up to 257 times reduction in model size on real-world network intrusion detection datasets, while also improving adversarial robustness and explainability.
Reinforcement Learning from Multi-Source Imperfect Preferences: Best-of-Both-Regimes Regret
Mar 20, 2026Reinforcement learning from human feedback (RLHF) replaces hard-to-specify rewards with pairwise trajectory preferences, yet regret-oriented theory often assumes that preference labels are generated consistently from a single ground-truth objective. In practical RLHF systems, however, feedback is typically \emph{multi-source} (annotators, experts, reward models, heuristics) and can exhibit systematic, persistent mismatches due to subjectivity, expertise variation, and annotation/modeling artifacts. We study episodic RL from \emph{multi-source imperfect preferences} through a cumulative imperfection budget: for each source, the total deviation of its preference probabilities from an ideal oracle is at most $ω$ over $K$ episodes. We propose a unified algorithm with regret $\tilde{O}(\sqrt{K/M}+ω)$, which exhibits a best-of-both-regimes behavior: it achieves $M$-dependent statistical gains when imperfection is small (where $M$ is the number of sources), while remaining robust with unavoidable additive dependence on $ω$ when imperfection is large. We complement this with a lower bound $\tildeΩ(\max\{\sqrt{K/M},ω\})$, which captures the best possible improvement with respect to $M$ and the unavoidable dependence on $ω$, and a counterexample showing that naïvely treating imperfect feedback as as oracle-consistent can incur regret as large as $\tildeΩ(\min\{ω\sqrt{K},K\})$. Technically, our approach involves imperfection-adaptive weighted comparison learning, value-targeted transition estimation to control hidden feedback-induced distribution shift, and sub-importance sampling to keep the weighted objectives analyzable, yielding regret guarantees that quantify when multi-source feedback provably improves RLHF and how cumulative imperfection fundamentally limits it.
SPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
FlowSymm: Physics Aware, Symmetry Preserving Graph Attention for Network Flow Completion
Jan 29, 2026Recovering missing flows on the edges of a network, while exactly respecting local conservation laws, is a fundamental inverse problem that arises in many systems such as transportation, energy, and mobility. We introduce FlowSymm, a novel architecture that combines (i) a group-action on divergence-free flows, (ii) a graph-attention encoder to learn feature-conditioned weights over these symmetry-preserving actions, and (iii) a lightweight Tikhonov refinement solved via implicit bilevel optimization. The method first anchors the given observation on a minimum-norm divergence-free completion. We then compute an orthonormal basis for all admissible group actions that leave the observed flows invariant and parameterize the valid solution subspace, which shows an Abelian group structure under vector addition. A stack of GATv2 layers then encodes the graph and its edge features into per-edge embeddings, which are pooled over the missing edges and produce per-basis attention weights. This attention-guided process selects a set of physics-aware group actions that preserve the observed flows. Finally, a scalar Tikhonov penalty refines the missing entries via a convex least-squares solver, with gradients propagated implicitly through Cholesky factorization. Across three real-world flow benchmarks (traffic, power, bike), FlowSymm outperforms state-of-the-art baselines in RMSE, MAE and correlation metrics.
PRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
A Differentiable Digital Twin of Distributed Link Scheduling for Contention-Aware Networking
Dec 11, 2025



Many routing and flow optimization problems in wired networks can be solved efficiently using minimum cost flow formulations. However, this approach does not extend to wireless multi-hop networks, where the assumptions of fixed link capacity and linear cost structure collapse due to contention for shared spectrum resources. The key challenge is that the long-term capacity of a wireless link becomes a non-linear function of its network context, including network topology, link quality, and the traffic assigned to neighboring links. In this work, we pursue a new direction of modeling wireless network under randomized medium access control by developing an analytical network digital twin (NDT) that predicts link duty cycles from network context. We generalize randomized contention as finding a Maximal Independent Set (MIS) on the conflict graph using weighted Luby's algorithm, derive an analytical model of link duty cycles, and introduce an iterative procedure that resolves the circular dependency among duty cycle, link capacity, and contention probability. Our numerical experiments show that the proposed NDT accurately predicts link duty cycles and congestion patterns with up to a 5000x speedup over packet-level simulation, and enables us to optimize link scheduling using gradient descent for reduced congestion and radio footprint.
Topology Identification and Inference over Graphs
Dec 11, 2025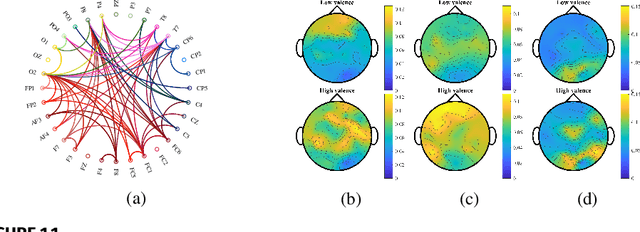
Topology identification and inference of processes evolving over graphs arise in timely applications involving brain, transportation, financial, power, as well as social and information networks. This chapter provides an overview of graph topology identification and statistical inference methods for multidimensional relational data. Approaches for undirected links connecting graph nodes are outlined, going all the way from correlation metrics to covariance selection, and revealing ties with smooth signal priors. To account for directional (possibly causal) relations among nodal variables and address the limitations of linear time-invariant models in handling dynamic as well as nonlinear dependencies, a principled framework is surveyed to capture these complexities through judiciously selected kernels from a prescribed dictionary. Generalizations are also described via structural equations and vector autoregressions that can exploit attributes such as low rank, sparsity, acyclicity, and smoothness to model dynamic processes over possibly time-evolving topologies. It is argued that this approach supports both batch and online learning algorithms with convergence rate guarantees, is amenable to tensor (that is, multi-way array) formulations as well as decompositions that are well-suited for multidimensional network data, and can seamlessly leverage high-order statistical information.
SeLR: Sparsity-enhanced Lagrangian Relaxation for Computation Offloading at the Edge
May 01, 2025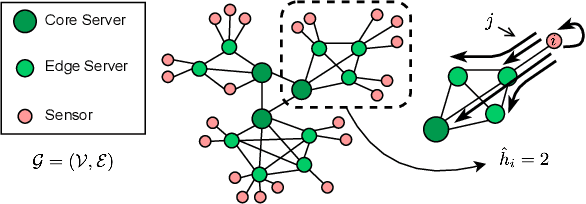
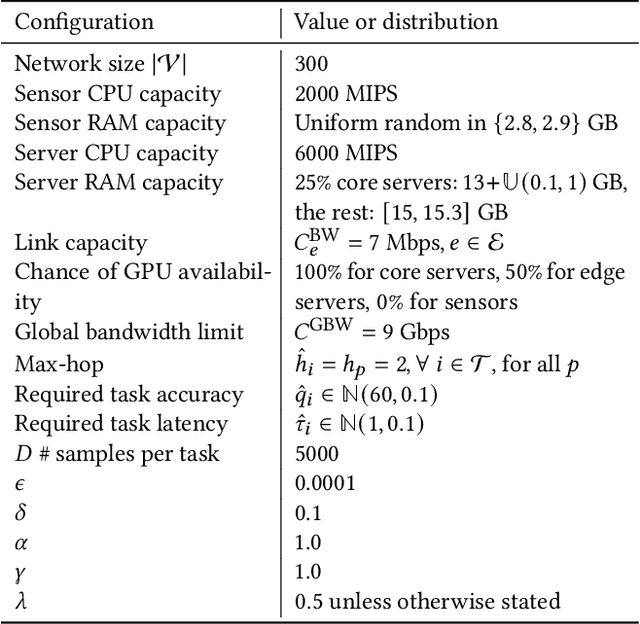
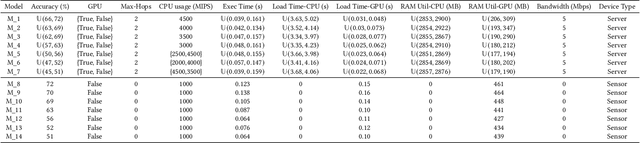
This paper introduces a novel computational approach for offloading sensor data processing tasks to servers in edge networks for better accuracy and makespan. A task is assigned with one of several offloading options, each comprises a server, a route for uploading data to the server, and a service profile that specifies the performance and resource consumption at the server and in the network. This offline offloading and routing problem is formulated as mixed integer programming (MIP), which is non-convex and HP-hard due to the discrete decision variables associated to the offloading options. The novelty of our approach is to transform this non-convex problem into iterative convex optimization by relaxing integer decision variables into continuous space, combining primal-dual optimization for penalizing constraint violations and reweighted $L_1$-minimization for promoting solution sparsity, which achieves better convergence through a smoother path in a continuous search space. Compared to existing greedy heuristics, our approach can achieve a better Pareto frontier in accuracy and latency, scales better to larger problem instances, and can achieve a 7.72--9.17$\times$ reduction in computational overhead of scheduling compared to the optimal solver in hierarchically organized edge networks with 300 nodes and 50--100 tasks.
Generalizing Biased Backpressure Routing and Scheduling to Wireless Multi-hop Networks with Advanced Air-interfaces
Apr 30, 2025
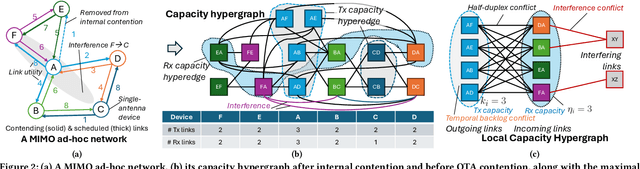
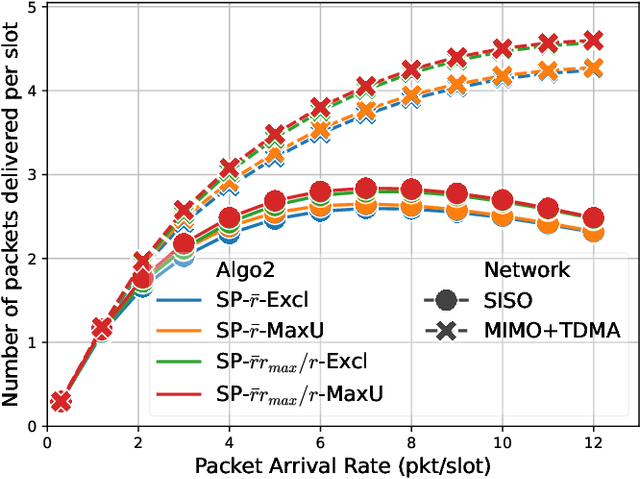
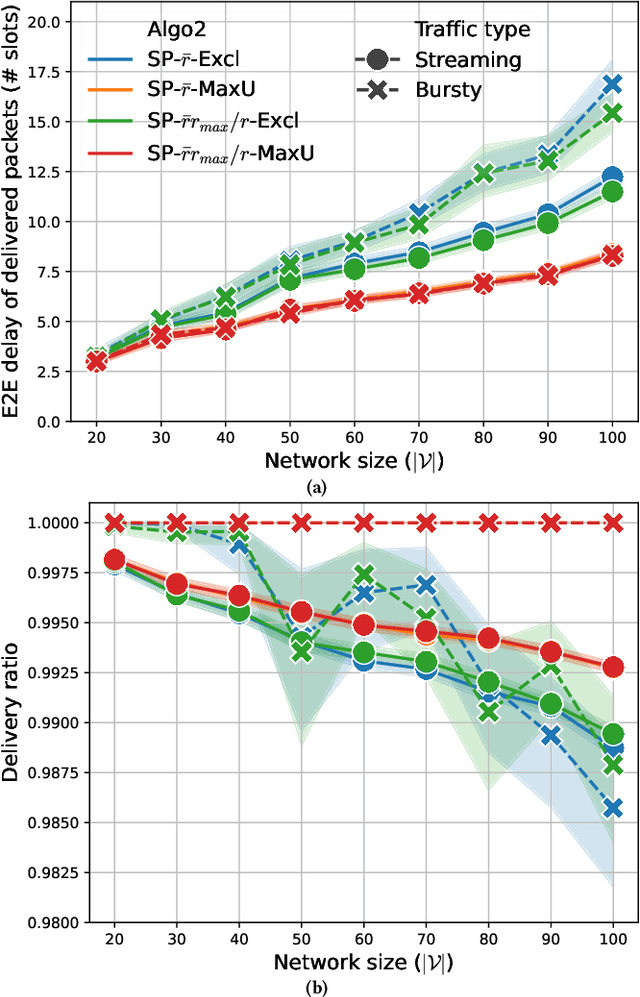
Backpressure (BP) routing and scheduling is a well-established resource allocation method for wireless multi-hop networks, known for its fully distributed operations and proven maximum queue stability. Recent advances in shortest path-biased BP routing (SP-BP) mitigate shortcomings such as slow startup and random walk, but exclusive link-level commodity selection still suffers from the last-packet problem and bandwidth underutilization. Moreover, classic BP routing implicitly assumes single-input-single-output (SISO) transceivers, which can lead to the same packets being scheduled on multiple outgoing links for multiple-input-multiple-output (MIMO) transceivers, causing detouring and looping in MIMO networks. In this paper, we revisit the foundational Lyapunov drift theory underlying BP routing and demonstrate that exclusive commodity selection is unnecessary, and instead propose a Max-Utility link-sharing method. Additionally, we generalize MaxWeight scheduling to MIMO networks by introducing attributed capacity hypergraphs (ACH), an extension of traditional conflict graphs for SISO networks, and by incorporating backlog reassignment into scheduling iterations to prevent redundant packet routing. Numerical evaluations show that our approach substantially mitigates the last-packet problem in state-of-the-art (SOTA) SP-BP under lightweight traffic, and slightly expands the network capacity region for heavier traffic.
Joint Task Offloading and Routing in Wireless Multi-hop Networks Using Biased Backpressure Algorithm
Dec 19, 2024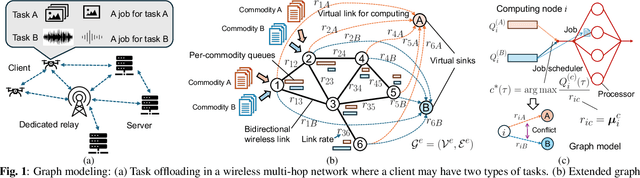
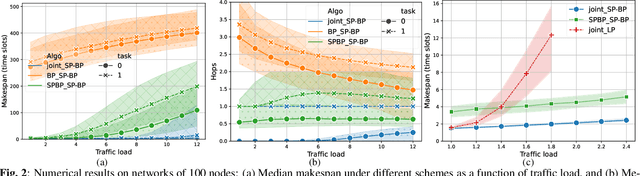
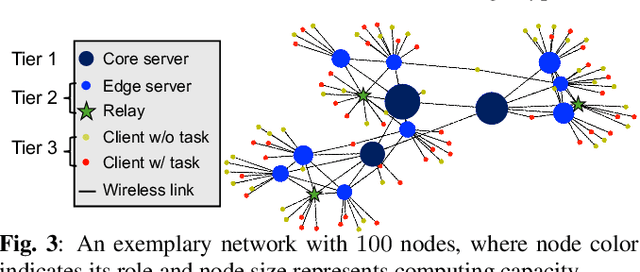
A significant challenge for computation offloading in wireless multi-hop networks is the complex interaction among traffic flows in the presence of interference. Existing approaches often ignore these key effects and/or rely on outdated queueing and channel state information. To fill these gaps, we reformulate joint offloading and routing as a routing problem on an extended graph with physical and virtual links. We adopt the state-of-the-art shortest path-biased Backpressure routing algorithm, which allows the destination and the route of a job to be dynamically adjusted at every time step based on network-wide long-term information and real-time states of local neighborhoods. In large networks, our approach achieves smaller makespan than existing approaches, such as separated Backpressure offloading and joint offloading and routing based on linear programming.