 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Rules for Extreme-Edge Scientific Computing on AI Engines
Apr 21, 2026Extreme-edge scientific applications use machine learning models to analyze sensor data and make real-time decisions. Their stringent latency and throughput requirements demand small batch sizes and require that model weights remain fully on-chip. Spatial dataflow implementations are common for extreme-edge applications. Spatial dataflow works well for small networks, but it fails to scale to larger models due to inherent resource scaling limitations. AI Engines on modern FPGA SoCs offer a promising alternative with high compute density and additional on-chip memory. However, the architecture, programming model, and performance-scaling behavior of AI Engines differ fundamentally from those of the programmable logic, making direct comparison non-trivial and the benefits of using AI Engines unclear. This work addresses how and when extreme-edge scientific neural networks should be implemented on AI Engines versus programmable logic. We provide systematic architectural characterization and micro-benchmarking and introduce a latency-adjusted resource equivalence (LARE) metric that identifies when AI Engine implementations outperform programmable logic designs. We further propose spatial and API-level dataflow optimizations tailored to low-latency scientific inference. Finally, we demonstrate the successful deployment of end-to-end neural networks on AI Engines that cannot fit on programmable logic when using the hlsml toolchain.
TinySense: Effective CSI Compression for Scalable and Accurate Wi-Fi Sensing
Jan 22, 2026With the growing demand for device-free and privacy-preserving sensing solutions, Wi-Fi sensing has emerged as a promising approach for human pose estimation (HPE). However, existing methods often process vast amounts of channel state information (CSI) data directly, ultimately straining networking resources. This paper introduces TinySense, an efficient compression framework that enhances the scalability of Wi-Fi-based human sensing. Our approach is based on a new vector quantization-based generative adversarial network (VQGAN). Specifically, by leveraging a VQGAN-learned codebook, TinySense significantly reduces CSI data while maintaining the accuracy required for reliable HPE. To optimize compression, we employ the K-means algorithm to dynamically adjust compression bitrates to cluster a large-scale pre-trained codebook into smaller subsets. Furthermore, a Transformer model is incorporated to mitigate bitrate loss, enhancing robustness in unreliable networking conditions. We prototype TinySense on an experimental testbed using Jetson Nano and Raspberry Pi to measure latency and network resource use. Extensive results demonstrate that TinySense significantly outperforms state-of-the-art compression schemes, achieving up to 1.5x higher HPE accuracy score (PCK20) under the same compression rate. It also reduces latency and networking overhead, respectively, by up to 5x and 2.5x. The code repository is available online at here.
Semantic Multiplexing
Nov 16, 2025Mobile devices increasingly require the parallel execution of several computing tasks offloaded at the wireless edge. Existing communication systems only support parallel transmissions at the bit level, which fundamentally limits the number of tasks that can be concurrently processed. To address this bottleneck, this paper introduces the new concept of Semantic Multiplexing. Our approach shifts stream multiplexing from bits to tasks by merging multiple task-related compressed representations into a single semantic representation. As such, Semantic Multiplexing can multiplex more tasks than the number of physical channels without adding antennas or widening bandwidth by extending the effective degrees of freedom at the semantic layer, without contradicting Shannon capacity rules. We have prototyped Semantic Multiplexing on an experimental testbed with Jetson Orin Nano and millimeter-wave software-defined radios and tested its performance on image classification and sentiment analysis while comparing to several existing baselines in semantic communications. Our experiments demonstrate that Semantic Multiplexing allows jointly processing multiple tasks at the semantic level while maintaining sufficient task accuracy. For example, image classification accuracy drops by less than 4% when increasing from 2 to 8 the number of tasks multiplexed over a 4$\times$4 channel. Semantic Multiplexing reduces latency, energy consumption, and communication load respectively by up to 8$\times$, 25$\times$, and 54$\times$ compared to the baselines while keeping comparable performance. We pledge to publicly share the complete software codebase and the collected datasets for reproducibility.
Semantic Edge Computing and Semantic Communications in 6G Networks: A Unifying Survey and Research Challenges
Nov 27, 2024Semantic Edge Computing (SEC) and Semantic Communications (SemComs) have been proposed as viable approaches to achieve real-time edge-enabled intelligence in sixth-generation (6G) wireless networks. On one hand, SemCom leverages the strength of Deep Neural Networks (DNNs) to encode and communicate the semantic information only, while making it robust to channel distortions by compensating for wireless effects. Ultimately, this leads to an improvement in the communication efficiency. On the other hand, SEC has leveraged distributed DNNs to divide the computation of a DNN across different devices based on their computational and networking constraints. Although significant progress has been made in both fields, the literature lacks a systematic view to connect both fields. In this work, we fulfill the current gap by unifying the SEC and SemCom fields. We summarize the research problems in these two fields and provide a comprehensive review of the state of the art with a focus on their technical strengths and challenges.
DARDA: Domain-Aware Real-Time Dynamic Neural Network Adaptation
Sep 15, 2024Test Time Adaptation (TTA) has emerged as a practical solution to mitigate the performance degradation of Deep Neural Networks (DNNs) in the presence of corruption/ noise affecting inputs. Existing approaches in TTA continuously adapt the DNN, leading to excessive resource consumption and performance degradation due to accumulation of error stemming from lack of supervision. In this work, we propose Domain-Aware Real-Time Dynamic Adaptation (DARDA) to address such issues. Our key approach is to proactively learn latent representations of some corruption types, each one associated with a sub-network state tailored to correctly classify inputs affected by that corruption. After deployment, DARDA adapts the DNN to previously unseen corruptions in an unsupervised fashion by (i) estimating the latent representation of the ongoing corruption; (ii) selecting the sub-network whose associated corruption is the closest in the latent space to the ongoing corruption; and (iii) adapting DNN state, so that its representation matches the ongoing corruption. This way, DARDA is more resource efficient and can swiftly adapt to new distributions caused by different corruptions without requiring a large variety of input data. Through experiments with two popular mobile edge devices - Raspberry Pi and NVIDIA Jetson Nano - we show that DARDA reduces energy consumption and average cache memory footprint respectively by 1.74x and 2.64x with respect to the state of the art, while increasing the performance by 10.4%, 5.7% and 4.4% on CIFAR-10, CIFAR-100 and TinyImagenet.
CGRA4ML: A Framework to Implement Modern Neural Networks for Scientific Edge Computing
Aug 29, 2024Scientific edge computing increasingly relies on hardware-accelerated neural networks to implement complex, near-sensor processing at extremely high throughputs and low latencies. Existing frameworks like HLS4ML are effective for smaller models, but struggle with larger, modern neural networks due to their requirement of spatially implementing the neural network layers and storing all weights in on-chip memory. CGRA4ML is an open-source, modular framework designed to bridge the gap between neural network model complexity and extreme performance requirements. CGRA4ML extends the capabilities of HLS4ML by allowing off-chip data storage and supporting a broader range of neural network architectures, including models like ResNet, PointNet, and transformers. Unlike HLS4ML, CGRA4ML generates SystemVerilog RTL, making it more suitable for targeting ASIC and FPGA design flows. We demonstrate the effectiveness of our framework by implementing and scaling larger models that were previously unattainable with HLS4ML, showcasing its adaptability and efficiency in handling complex computations. CGRA4ML also introduces an extensive verification framework, with a generated runtime firmware that enables its integration into different SoC platforms. CGRA4ML's minimal and modular infrastructure of Python API, SystemVerilog hardware, Tcl toolflows, and C runtime, facilitates easy integration and experimentation, allowing scientists to focus on innovation rather than the intricacies of hardware design and optimization.
Resilience and Security of Deep Neural Networks Against Intentional and Unintentional Perturbations: Survey and Research Challenges
Aug 03, 2024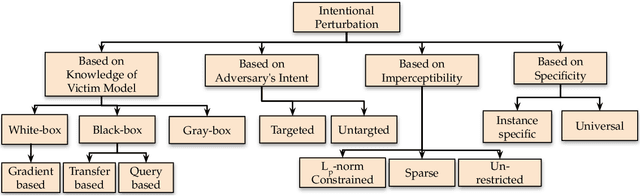
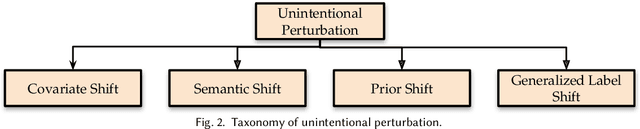
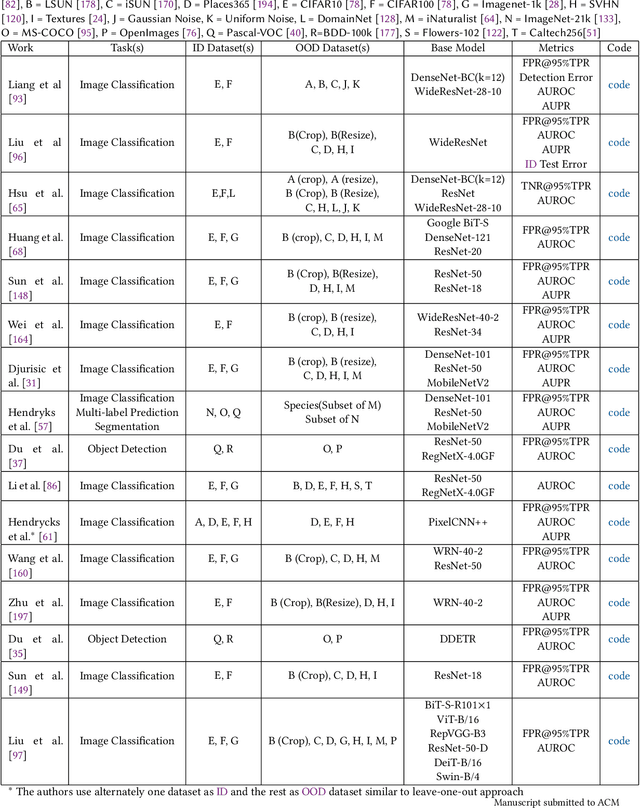
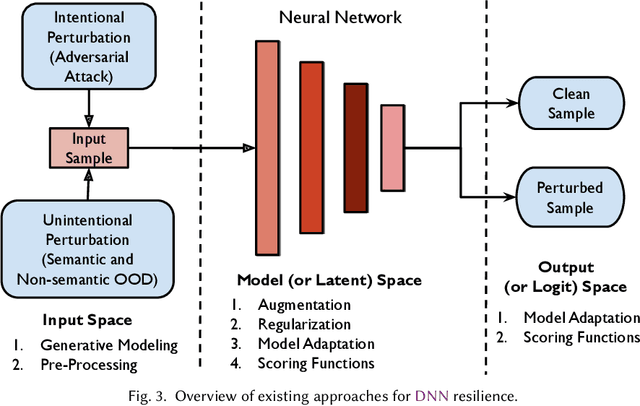
In order to deploy deep neural networks (DNNs) in high-stakes scenarios, it is imperative that DNNs provide inference robust to external perturbations - both intentional and unintentional. Although the resilience of DNNs to intentional and unintentional perturbations has been widely investigated, a unified vision of these inherently intertwined problem domains is still missing. In this work, we fill this gap by providing a survey of the state of the art and highlighting the similarities of the proposed approaches.We also analyze the research challenges that need to be addressed to deploy resilient and secure DNNs. As there has not been any such survey connecting the resilience of DNNs to intentional and unintentional perturbations, we believe this work can help advance the frontier in both domains by enabling the exchange of ideas between the two communities.
Resilience of Entropy Model in Distributed Neural Networks
Mar 01, 2024Distributed deep neural networks (DNNs) have emerged as a key technique to reduce communication overhead without sacrificing performance in edge computing systems. Recently, entropy coding has been introduced to further reduce the communication overhead. The key idea is to train the distributed DNN jointly with an entropy model, which is used as side information during inference time to adaptively encode latent representations into bit streams with variable length. To the best of our knowledge, the resilience of entropy models is yet to be investigated. As such, in this paper we formulate and investigate the resilience of entropy models to intentional interference (e.g., adversarial attacks) and unintentional interference (e.g., weather changes and motion blur). Through an extensive experimental campaign with 3 different DNN architectures, 2 entropy models and 4 rate-distortion trade-off factors, we demonstrate that the entropy attacks can increase the communication overhead by up to 95%. By separating compression features in frequency and spatial domain, we propose a new defense mechanism that can reduce the transmission overhead of the attacked input by about 9% compared to unperturbed data, with only about 2% accuracy loss. Importantly, the proposed defense mechanism is a standalone approach which can be applied in conjunction with approaches such as adversarial training to further improve robustness. Code will be shared for reproducibility.
SAWEC: Sensing-Assisted Wireless Edge Computing
Feb 15, 2024



Emerging mobile virtual reality (VR) systems will require to continuously perform complex computer vision tasks on ultra-high-resolution video frames through the execution of deep neural networks (DNNs)-based algorithms. Since state-of-the-art DNNs require computational power that is excessive for mobile devices, techniques based on wireless edge computing (WEC) have been recently proposed. However, existing WEC methods require the transmission and processing of a high amount of video data which may ultimately saturate the wireless link. In this paper, we propose a novel Sensing-Assisted Wireless Edge Computing (SAWEC) paradigm to address this issue. SAWEC leverages knowledge about the physical environment to reduce the end-to-end latency and overall computational burden by transmitting to the edge server only the relevant data for the delivery of the service. Our intuition is that the transmission of the portion of the video frames where there are no changes with respect to previous frames can be avoided. Specifically, we leverage wireless sensing techniques to estimate the location of objects in the environment and obtain insights about the environment dynamics. Hence, only the part of the frames where any environmental change is detected is transmitted and processed. We evaluated SAWEC by using a 10K 360$^{\circ}$ camera with a Wi-Fi 6 sensing system operating at 160 MHz and performing localization and tracking. We perform experiments in an anechoic chamber and a hall room with two human subjects in six different setups. Experimental results show that SAWEC reduces the channel occupation, and end-to-end latency by 93.81%, and 96.19% respectively while improving the instance segmentation performance by 46.98% with respect to state-of-the-art WEC approaches. For reproducibility purposes, we pledge to share our whole dataset and code repository.
Sensing in Bi-Static ISAC Systems with Clock Asynchronism: A Signal Processing Perspective
Feb 14, 2024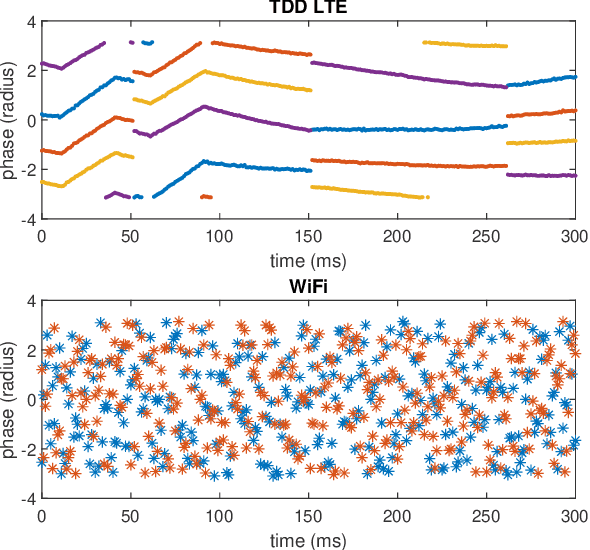
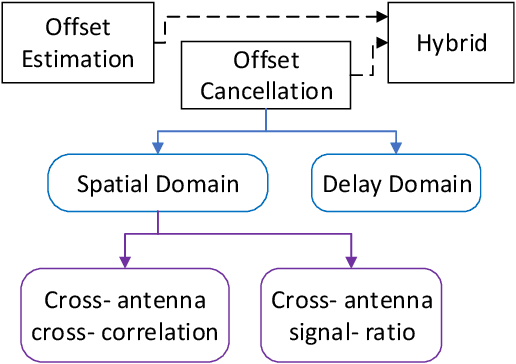
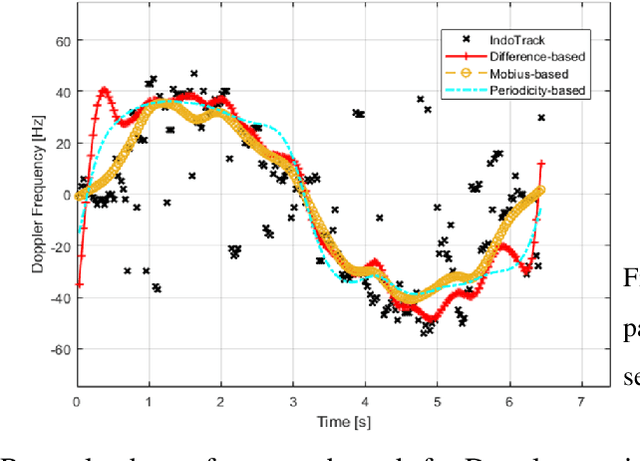
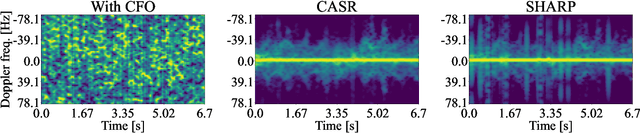
Integrated Sensing and Communications (ISAC) has been identified as a pillar usage scenario for the impending 6G era. Bi-static sensing, a major type of sensing in \ac{isac}, is promising to expedite ISAC in the near future, as it requires minimal changes to the existing network infrastructure. However, a critical challenge for bi-static sensing is clock asynchronism due to the use of different clocks at far separated transmitter and receiver. This causes the received signal to be affected by time-varying random phase offsets, severely degrading, or even failing, direct sensing. Considerable research attention has been directed toward addressing the clock asynchronism issue in bi-static sensing. In this white paper, we endeavor to fill the gap by providing an overview of the issue and existing techniques developed in an ISAC background. Based on the review and comparison, we also draw insights into the future research directions and open problems, aiming to nurture the maturation of bi-static sensing in ISAC.