 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
CGRA4ML: A Framework to Implement Modern Neural Networks for Scientific Edge Computing
Aug 29, 2024Scientific edge computing increasingly relies on hardware-accelerated neural networks to implement complex, near-sensor processing at extremely high throughputs and low latencies. Existing frameworks like HLS4ML are effective for smaller models, but struggle with larger, modern neural networks due to their requirement of spatially implementing the neural network layers and storing all weights in on-chip memory. CGRA4ML is an open-source, modular framework designed to bridge the gap between neural network model complexity and extreme performance requirements. CGRA4ML extends the capabilities of HLS4ML by allowing off-chip data storage and supporting a broader range of neural network architectures, including models like ResNet, PointNet, and transformers. Unlike HLS4ML, CGRA4ML generates SystemVerilog RTL, making it more suitable for targeting ASIC and FPGA design flows. We demonstrate the effectiveness of our framework by implementing and scaling larger models that were previously unattainable with HLS4ML, showcasing its adaptability and efficiency in handling complex computations. CGRA4ML also introduces an extensive verification framework, with a generated runtime firmware that enables its integration into different SoC platforms. CGRA4ML's minimal and modular infrastructure of Python API, SystemVerilog hardware, Tcl toolflows, and C runtime, facilitates easy integration and experimentation, allowing scientists to focus on innovation rather than the intricacies of hardware design and optimization.
Within-Camera Multilayer Perceptron DVS Denoising
Apr 15, 2023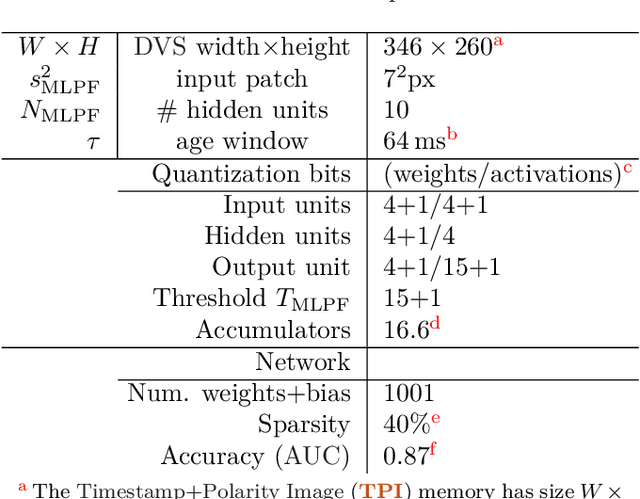
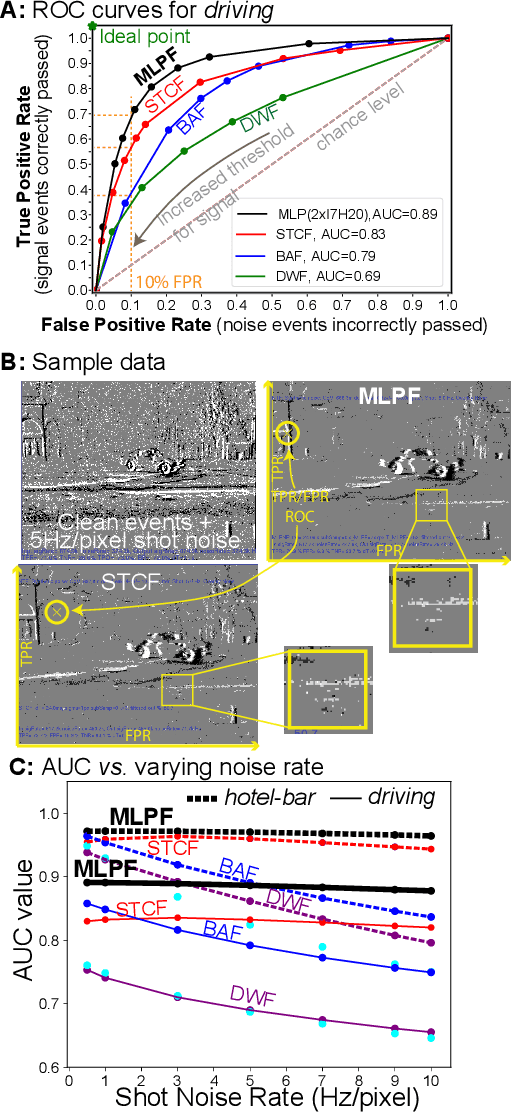

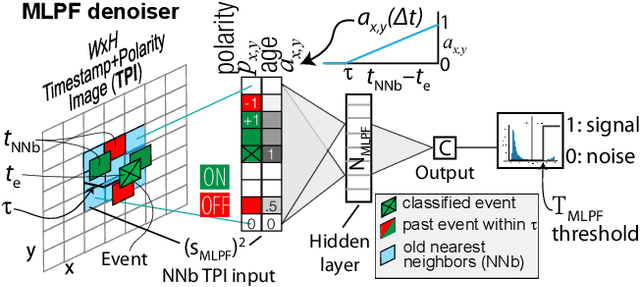
In-camera event denoising reduces the data rate of event cameras by filtering out noise at the source. A lightweight multilayer perceptron denoising filter (MLPF) provides state-of-the-art low-cost denoising accuracy. It processes a small neighborhood of pixels from the timestamp image around each event to discriminate signal and noise events. This paper proposes two digital logic implementations of the MLPF denoiser and quantifies their resource cost, power, and latency. The hardware MLPF quantizes the weights and hidden unit activations to 4 bits and has about 1k weights with about 40% sparsity. The Area-Under-Curve Receiver Operating Characteristic accuracy is nearly indistinguishable from that of the floating point network. The FPGA MLPF processes each event in 10 clock cycles. In FPGA, it uses 3.5k flip flops and 11.5k LUTs. Our ASIC implementation in 65nm digital technology for a 346x260 pixel camera occupies an area of 4.3mm^2 and consumes 4nJ of energy per event at event rates up to 25MHz. The MLPF can be easily integrated into an event camera using an FPGA or as an ASIC directly on the camera chip or in the same package. This denoising could dramatically reduce the energy consumed by the communication and host processor and open new areas of always-on event camera application under scavenged and battery power. Code: https://github.com/SensorsINI/dnd_hls