 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWithin-Camera Multilayer Perceptron DVS Denoising
Apr 15, 2023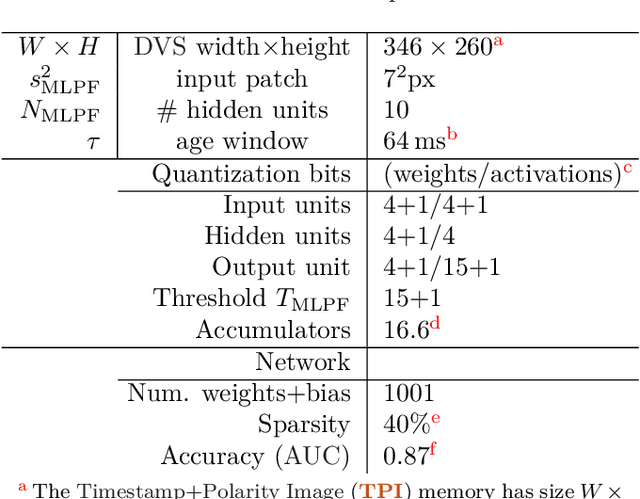
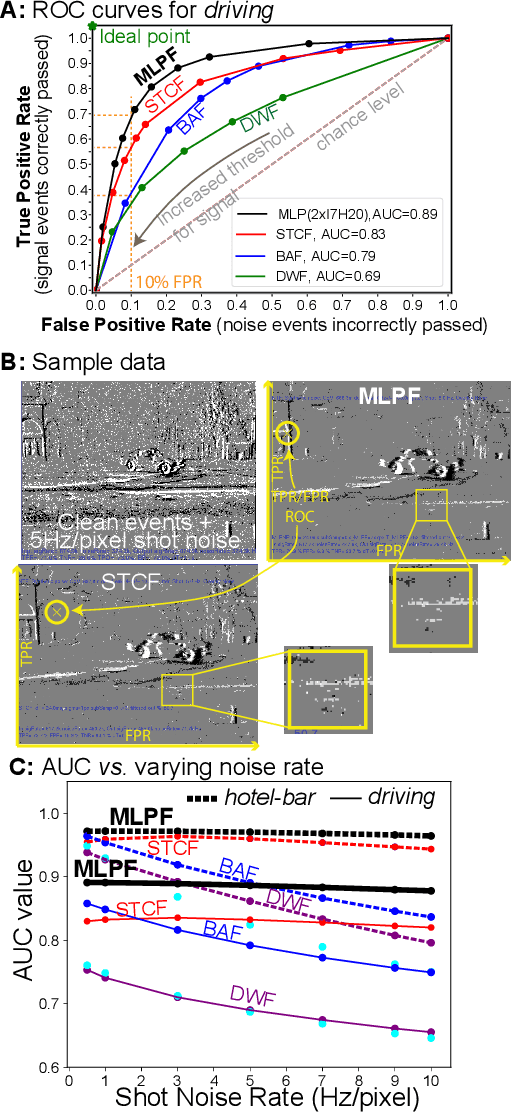

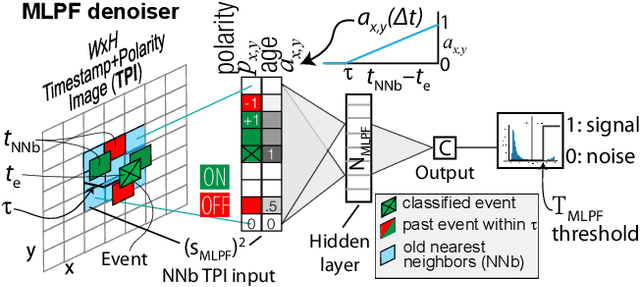
In-camera event denoising reduces the data rate of event cameras by filtering out noise at the source. A lightweight multilayer perceptron denoising filter (MLPF) provides state-of-the-art low-cost denoising accuracy. It processes a small neighborhood of pixels from the timestamp image around each event to discriminate signal and noise events. This paper proposes two digital logic implementations of the MLPF denoiser and quantifies their resource cost, power, and latency. The hardware MLPF quantizes the weights and hidden unit activations to 4 bits and has about 1k weights with about 40% sparsity. The Area-Under-Curve Receiver Operating Characteristic accuracy is nearly indistinguishable from that of the floating point network. The FPGA MLPF processes each event in 10 clock cycles. In FPGA, it uses 3.5k flip flops and 11.5k LUTs. Our ASIC implementation in 65nm digital technology for a 346x260 pixel camera occupies an area of 4.3mm^2 and consumes 4nJ of energy per event at event rates up to 25MHz. The MLPF can be easily integrated into an event camera using an FPGA or as an ASIC directly on the camera chip or in the same package. This denoising could dramatically reduce the energy consumed by the communication and host processor and open new areas of always-on event camera application under scavenged and battery power. Code: https://github.com/SensorsINI/dnd_hls
Towards hardware Implementation of WTA for CPG-based control of a Spiking Robotic Arm
Feb 14, 2022



Biological nervous systems typically perform the control of numerous degrees of freedom for example in animal limbs. Neuromorphic engineers study these systems by emulating them in hardware for a deeper understanding and its possible application to solve complex problems in engineering and robotics. Central-Pattern-Generators (CPGs) are part of neuro-controllers, typically used at their last steps to produce rhythmic patterns for limbs movement. Different patterns and gaits typically compete through winner-take-all (WTA) circuits to produce the right movements. In this work we present a WTA circuit implemented in a Spiking-Neural-Network (SNN) processor to produce such patterns for controlling a robotic arm in real-time. The robot uses spike-based proportional-integrativederivative (SPID) controllers to keep a commanded joint position from the winner population of neurons of the WTA circuit. Experiments demonstrate the feasibility of robotic control with spiking circuits following brain-inspiration.
Comprehensive Evaluation of OpenCL-based Convolutional Neural Network Accelerators in Xilinx and Altera FPGAs
Sep 29, 2016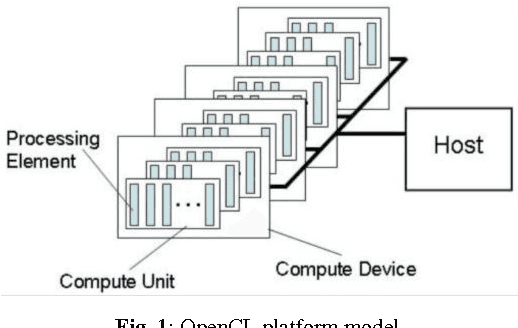



Deep learning has significantly advanced the state of the art in artificial intelligence, gaining wide popularity from both industry and academia. Special interest is around Convolutional Neural Networks (CNN), which take inspiration from the hierarchical structure of the visual cortex, to form deep layers of convolutional operations, along with fully connected classifiers. Hardware implementations of these deep CNN architectures are challenged with memory bottlenecks that require many convolution and fully-connected layers demanding large amount of communication for parallel computation. Multi-core CPU based solutions have demonstrated their inadequacy for this problem due to the memory wall and low parallelism. Many-core GPU architectures show superior performance but they consume high power and also have memory constraints due to inconsistencies between cache and main memory. FPGA design solutions are also actively being explored, which allow implementing the memory hierarchy using embedded BlockRAM. This boosts the parallel use of shared memory elements between multiple processing units, avoiding data replicability and inconsistencies. This makes FPGAs potentially powerful solutions for real-time classification of CNNs. Both Altera and Xilinx have adopted OpenCL co-design framework from GPU for FPGA designs as a pseudo-automatic development solution. In this paper, a comprehensive evaluation and comparison of Altera and Xilinx OpenCL frameworks for a 5-layer deep CNN is presented. Hardware resources, temporal performance and the OpenCL architecture for CNNs are discussed. Xilinx demonstrates faster synthesis, better FPGA resource utilization and more compact boards. Altera provides multi-platforms tools, mature design community and better execution times.