 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom PINNs to PIKANs: Recent Advances in Physics-Informed Machine Learning
Oct 17, 2024



Physics-Informed Neural Networks (PINNs) have emerged as a key tool in Scientific Machine Learning since their introduction in 2017, enabling the efficient solution of ordinary and partial differential equations using sparse measurements. Over the past few years, significant advancements have been made in the training and optimization of PINNs, covering aspects such as network architectures, adaptive refinement, domain decomposition, and the use of adaptive weights and activation functions. A notable recent development is the Physics-Informed Kolmogorov-Arnold Networks (PIKANS), which leverage a representation model originally proposed by Kolmogorov in 1957, offering a promising alternative to traditional PINNs. In this review, we provide a comprehensive overview of the latest advancements in PINNs, focusing on improvements in network design, feature expansion, optimization techniques, uncertainty quantification, and theoretical insights. We also survey key applications across a range of fields, including biomedicine, fluid and solid mechanics, geophysics, dynamical systems, heat transfer, chemical engineering, and beyond. Finally, we review computational frameworks and software tools developed by both academia and industry to support PINN research and applications.
Activation thresholds and expressiveness of polynomial neural networks
Aug 08, 2024Polynomial neural networks have been implemented in a range of applications and present an advantageous framework for theoretical machine learning. A polynomial neural network of fixed architecture and activation degree gives an algebraic map from the network's weights to a set of polynomials. The image of this map is the space of functions representable by the network. Its Zariski closure is an affine variety known as a neurovariety. The dimension of a polynomial neural network's neurovariety provides a measure of its expressivity. In this work, we introduce the notion of the activation threshold of a network architecture which expresses when the dimension of a neurovariety achieves its theoretical maximum. In addition, we prove expressiveness results for polynomial neural networks with equi-width~architectures.
GPT vs Human for Scientific Reviews: A Dual Source Review on Applications of ChatGPT in Science
Dec 05, 2023



The new polymath Large Language Models (LLMs) can speed-up greatly scientific reviews, possibly using more unbiased quantitative metrics, facilitating cross-disciplinary connections, and identifying emerging trends and research gaps by analyzing large volumes of data. However, at the present time, they lack the required deep understanding of complex methodologies, they have difficulty in evaluating innovative claims, and they are unable to assess ethical issues and conflicts of interest. Herein, we consider 13 GPT-related papers across different scientific domains, reviewed by a human reviewer and SciSpace, a large language model, with the reviews evaluated by three distinct types of evaluators, namely GPT-3.5, a crowd panel, and GPT-4. We found that 50% of SciSpace's responses to objective questions align with those of a human reviewer, with GPT-4 (informed evaluator) often rating the human reviewer higher in accuracy, and SciSpace higher in structure, clarity, and completeness. In subjective questions, the uninformed evaluators (GPT-3.5 and crowd panel) showed varying preferences between SciSpace and human responses, with the crowd panel showing a preference for the human responses. However, GPT-4 rated them equally in accuracy and structure but favored SciSpace for completeness.
DYNAP-SE2: a scalable multi-core dynamic neuromorphic asynchronous spiking neural network processor
Oct 01, 2023With the remarkable progress that technology has made, the need for processing data near the sensors at the edge has increased dramatically. The electronic systems used in these applications must process data continuously, in real-time, and extract relevant information using the smallest possible energy budgets. A promising approach for implementing always-on processing of sensory signals that supports on-demand, sparse, and edge-computing is to take inspiration from biological nervous system. Following this approach, we present a brain-inspired platform for prototyping real-time event-based Spiking Neural Networks (SNNs). The system proposed supports the direct emulation of dynamic and realistic neural processing phenomena such as short-term plasticity, NMDA gating, AMPA diffusion, homeostasis, spike frequency adaptation, conductance-based dendritic compartments and spike transmission delays. The analog circuits that implement such primitives are paired with a low latency asynchronous digital circuits for routing and mapping events. This asynchronous infrastructure enables the definition of different network architectures, and provides direct event-based interfaces to convert and encode data from event-based and continuous-signal sensors. Here we describe the overall system architecture, we characterize the mixed signal analog-digital circuits that emulate neural dynamics, demonstrate their features with experimental measurements, and present a low- and high-level software ecosystem that can be used for configuring the system. The flexibility to emulate different biologically plausible neural networks, and the chip's ability to monitor both population and single neuron signals in real-time, allow to develop and validate complex models of neural processing for both basic research and edge-computing applications.
Artificial to Spiking Neural Networks Conversion for Scientific Machine Learning
Aug 31, 2023We introduce a method to convert Physics-Informed Neural Networks (PINNs), commonly used in scientific machine learning, to Spiking Neural Networks (SNNs), which are expected to have higher energy efficiency compared to traditional Artificial Neural Networks (ANNs). We first extend the calibration technique of SNNs to arbitrary activation functions beyond ReLU, making it more versatile, and we prove a theorem that ensures the effectiveness of the calibration. We successfully convert PINNs to SNNs, enabling computational efficiency for diverse regression tasks in solving multiple differential equations, including the unsteady Navier-Stokes equations. We demonstrate great gains in terms of overall efficiency, including Separable PINNs (SPINNs), which accelerate the training process. Overall, this is the first work of this kind and the proposed method achieves relatively good accuracy with low spike rates.
Functional dimension of feedforward ReLU neural networks
Sep 08, 2022
It is well-known that the parameterized family of functions representable by fully-connected feedforward neural networks with ReLU activation function is precisely the class of piecewise linear functions with finitely many pieces. It is less well-known that for every fixed architecture of ReLU neural network, the parameter space admits positive-dimensional spaces of symmetries, and hence the local functional dimension near any given parameter is lower than the parametric dimension. In this work we carefully define the notion of functional dimension, show that it is inhomogeneous across the parameter space of ReLU neural network functions, and continue an investigation - initiated in [14] and [5] - into when the functional dimension achieves its theoretical maximum. We also study the quotient space and fibers of the realization map from parameter space to function space, supplying examples of fibers that are disconnected, fibers upon which functional dimension is non-constant, and fibers upon which the symmetry group acts non-transitively.
A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks
Jul 21, 2022


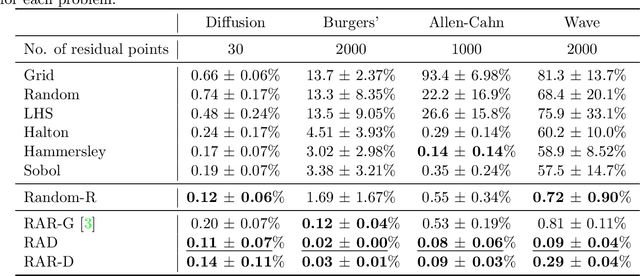
Physics-informed neural networks (PINNs) have shown to be an effective tool for solving forward and inverse problems of partial differential equations (PDEs). PINNs embed the PDEs into the loss of the neural network, and this PDE loss is evaluated at a set of scattered residual points. The distribution of these points are highly important to the performance of PINNs. However, in the existing studies on PINNs, only a few simple residual point sampling methods have mainly been used. Here, we present a comprehensive study of two categories of sampling: non-adaptive uniform sampling and adaptive nonuniform sampling. We consider six uniform sampling, including (1) equispaced uniform grid, (2) uniformly random sampling, (3) Latin hypercube sampling, (4) Halton sequence, (5) Hammersley sequence, and (6) Sobol sequence. We also consider a resampling strategy for uniform sampling. To improve the sampling efficiency and the accuracy of PINNs, we propose two new residual-based adaptive sampling methods: residual-based adaptive distribution (RAD) and residual-based adaptive refinement with distribution (RAR-D), which dynamically improve the distribution of residual points based on the PDE residuals during training. Hence, we have considered a total of 10 different sampling methods, including six non-adaptive uniform sampling, uniform sampling with resampling, two proposed adaptive sampling, and an existing adaptive sampling. We extensively tested the performance of these sampling methods for four forward problems and two inverse problems in many setups. Our numerical results presented in this study are summarized from more than 6000 simulations of PINNs. We show that the proposed adaptive sampling methods of RAD and RAR-D significantly improve the accuracy of PINNs with fewer residual points. The results obtained in this study can also be used as a practical guideline in choosing sampling methods.
Towards hardware Implementation of WTA for CPG-based control of a Spiking Robotic Arm
Feb 14, 2022



Biological nervous systems typically perform the control of numerous degrees of freedom for example in animal limbs. Neuromorphic engineers study these systems by emulating them in hardware for a deeper understanding and its possible application to solve complex problems in engineering and robotics. Central-Pattern-Generators (CPGs) are part of neuro-controllers, typically used at their last steps to produce rhythmic patterns for limbs movement. Different patterns and gaits typically compete through winner-take-all (WTA) circuits to produce the right movements. In this work we present a WTA circuit implemented in a Spiking-Neural-Network (SNN) processor to produce such patterns for controlling a robotic arm in real-time. The robot uses spike-based proportional-integrativederivative (SPID) controllers to keep a commanded joint position from the winner population of neurons of the WTA circuit. Experiments demonstrate the feasibility of robotic control with spiking circuits following brain-inspiration.
Identification of mental fatigue in language comprehension tasks based on EEG and deep learning
Apr 14, 2021



Mental fatigue increases the risk of operator error in language comprehension tasks. In order to prevent operator performance degradation, we used EEG signals to assess the mental fatigue of operators in human-computer systems. This study presents an experimental design for fatigue detection in language comprehension tasks. We obtained EEG signals from a 14-channel wireless EEG detector in 15 healthy participants. Each participant was given a cognitive test of a language comprehension task, in the form of multiple choice questions, in which pronoun references were selected between nominal and surrogate sentences. In this paper, the 2400 EEG fragments collected are divided into three data sets according to different utilization rates, namely 1200s data set with 50% utilization rate, 1500s data set with 62.5% utilization rate, and 1800s data set with 75% utilization rate. In the aspect of feature extraction, different EEG features were extracted, including time domain features, frequency domain features and entropy features, and the effects of different features and feature combinations on classification accuracy were explored. In terms of classification, we introduced the Convolutional Neural Network (CNN) method as the preferred method, It was compared with Least Squares Support Vector Machines(LSSVM),Support Vector Machines(SVM),Logistic Regression (LR), Random Forest(RF), Naive Bayes (NB), K-Nearest Neighbor (KNN) and Decision Tree(DT).According to the results, the classification accuracy of convolutional neural network (CNN) is higher than that of other classification methods. The classification results show that the classification accuracy of 1200S dataset is higher than the other two datasets. The combination of Frequency and entropy feature and CNN has the highest classification accuracy, which is 85.34%.