 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Activation Function Dependence of the Spectral Bias of Neural Networks
Aug 10, 2022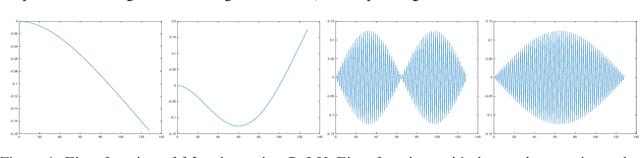
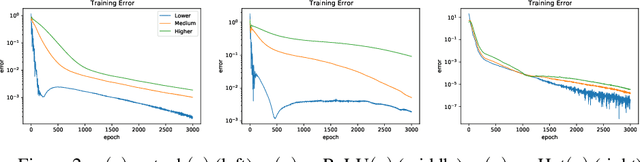
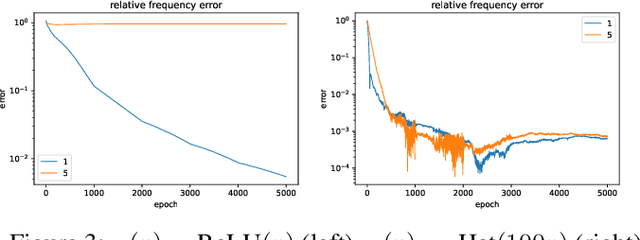
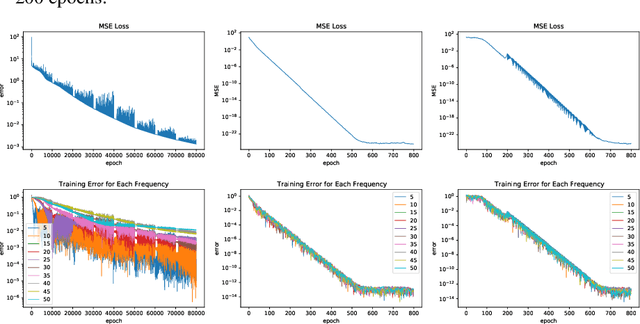
Neural networks are universal function approximators which are known to generalize well despite being dramatically overparameterized. We study this phenomenon from the point of view of the spectral bias of neural networks. Our contributions are two-fold. First, we provide a theoretical explanation for the spectral bias of ReLU neural networks by leveraging connections with the theory of finite element methods. Second, based upon this theory we predict that switching the activation function to a piecewise linear B-spline, namely the Hat function, will remove this spectral bias, which we verify empirically in a variety of settings. Our empirical studies also show that neural networks with the Hat activation function are trained significantly faster using stochastic gradient descent and ADAM. Combined with previous work showing that the Hat activation function also improves generalization accuracy on image classification tasks, this indicates that using the Hat activation provides significant advantages over the ReLU on certain problems.
A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks
Jul 21, 2022


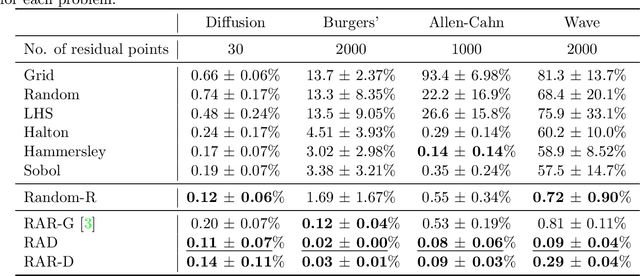
Physics-informed neural networks (PINNs) have shown to be an effective tool for solving forward and inverse problems of partial differential equations (PDEs). PINNs embed the PDEs into the loss of the neural network, and this PDE loss is evaluated at a set of scattered residual points. The distribution of these points are highly important to the performance of PINNs. However, in the existing studies on PINNs, only a few simple residual point sampling methods have mainly been used. Here, we present a comprehensive study of two categories of sampling: non-adaptive uniform sampling and adaptive nonuniform sampling. We consider six uniform sampling, including (1) equispaced uniform grid, (2) uniformly random sampling, (3) Latin hypercube sampling, (4) Halton sequence, (5) Hammersley sequence, and (6) Sobol sequence. We also consider a resampling strategy for uniform sampling. To improve the sampling efficiency and the accuracy of PINNs, we propose two new residual-based adaptive sampling methods: residual-based adaptive distribution (RAD) and residual-based adaptive refinement with distribution (RAR-D), which dynamically improve the distribution of residual points based on the PDE residuals during training. Hence, we have considered a total of 10 different sampling methods, including six non-adaptive uniform sampling, uniform sampling with resampling, two proposed adaptive sampling, and an existing adaptive sampling. We extensively tested the performance of these sampling methods for four forward problems and two inverse problems in many setups. Our numerical results presented in this study are summarized from more than 6000 simulations of PINNs. We show that the proposed adaptive sampling methods of RAD and RAR-D significantly improve the accuracy of PINNs with fewer residual points. The results obtained in this study can also be used as a practical guideline in choosing sampling methods.