 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-task Supervised Compression Model for Split Computing
Jan 02, 2025Split computing ($\neq$ split learning) is a promising approach to deep learning models for resource-constrained edge computing systems, where weak sensor (mobile) devices are wirelessly connected to stronger edge servers through channels with limited communication capacity. State-of-theart work on split computing presents methods for single tasks such as image classification, object detection, or semantic segmentation. The application of existing methods to multitask problems degrades model accuracy and/or significantly increase runtime latency. In this study, we propose Ladon, the first multi-task-head supervised compression model for multi-task split computing. Experimental results show that the multi-task supervised compression model either outperformed or rivaled strong lightweight baseline models in terms of predictive performance for ILSVRC 2012, COCO 2017, and PASCAL VOC 2012 datasets while learning compressed representations at its early layers. Furthermore, our models reduced end-to-end latency (by up to 95.4%) and energy consumption of mobile devices (by up to 88.2%) in multi-task split computing scenarios.
A Transformer Model for Symbolic Regression towards Scientific Discovery
Dec 13, 2023



Symbolic Regression (SR) searches for mathematical expressions which best describe numerical datasets. This allows to circumvent interpretation issues inherent to artificial neural networks, but SR algorithms are often computationally expensive. This work proposes a new Transformer model aiming at Symbolic Regression particularly focused on its application for Scientific Discovery. We propose three encoder architectures with increasing flexibility but at the cost of column-permutation equivariance violation. Training results indicate that the most flexible architecture is required to prevent from overfitting. Once trained, we apply our best model to the SRSD datasets (Symbolic Regression for Scientific Discovery datasets) which yields state-of-the-art results using the normalized tree-based edit distance, at no extra computational cost.
torchdistill Meets Hugging Face Libraries for Reproducible, Coding-Free Deep Learning Studies: A Case Study on NLP
Oct 26, 2023Reproducibility in scientific work has been becoming increasingly important in research communities such as machine learning, natural language processing, and computer vision communities due to the rapid development of the research domains supported by recent advances in deep learning. In this work, we present a significantly upgraded version of torchdistill, a modular-driven coding-free deep learning framework significantly upgraded from the initial release, which supports only image classification and object detection tasks for reproducible knowledge distillation experiments. To demonstrate that the upgraded framework can support more tasks with third-party libraries, we reproduce the GLUE benchmark results of BERT models using a script based on the upgraded torchdistill, harmonizing with various Hugging Face libraries. All the 27 fine-tuned BERT models and configurations to reproduce the results are published at Hugging Face, and the model weights have already been widely used in research communities. We also reimplement popular small-sized models and new knowledge distillation methods and perform additional experiments for computer vision tasks.
SplitBeam: Effective and Efficient Beamforming in Wi-Fi Networks Through Split Computing
Oct 12, 2023Modern IEEE 802.11 (Wi-Fi) networks extensively rely on multiple-input multiple-output (MIMO) to significantly improve throughput. To correctly beamform MIMO transmissions, the access point needs to frequently acquire a beamforming matrix (BM) from each connected station. However, the size of the matrix grows with the number of antennas and subcarriers, resulting in an increasing amount of airtime overhead and computational load at the station. Conventional approaches come with either excessive computational load or loss of beamforming precision. For this reason, we propose SplitBeam, a new framework where we train a split deep neural network (DNN) to directly output the BM given the channel state information (CSI) matrix as input. We formulate and solve a bottleneck optimization problem (BOP) to keep computation, airtime overhead, and bit error rate (BER) below application requirements. We perform extensive experimental CSI collection with off-the-shelf Wi-Fi devices in two distinct environments and compare the performance of SplitBeam with the standard IEEE 802.11 algorithm for BM feedback and the state-of-the-art DNN-based approach LB-SciFi. Our experimental results show that SplitBeam reduces the beamforming feedback size and computational complexity by respectively up to 81% and 84% while maintaining BER within about 10^-3 of existing approaches. We also implement the SplitBeam DNNs on FPGA hardware to estimate the end-to-end BM reporting delay, and show that the latter is less than 10 milliseconds in the most complex scenario, which is the target channel sounding frequency in realistic multi-user MIMO scenarios.
Cross-Lingual Knowledge Distillation for Answer Sentence Selection in Low-Resource Languages
May 25, 2023



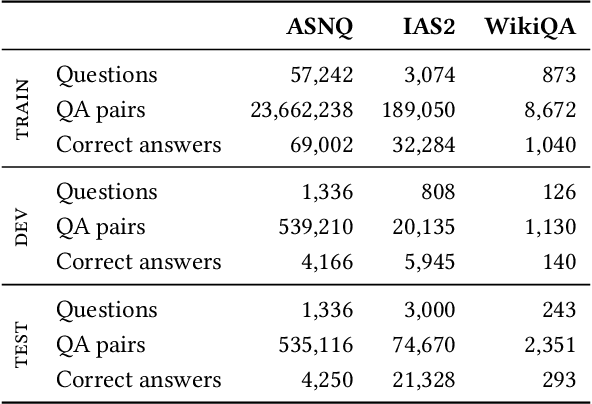
While impressive performance has been achieved on the task of Answer Sentence Selection (AS2) for English, the same does not hold for languages that lack large labeled datasets. In this work, we propose Cross-Lingual Knowledge Distillation (CLKD) from a strong English AS2 teacher as a method to train AS2 models for low-resource languages in the tasks without the need of labeled data for the target language. To evaluate our method, we introduce 1) Xtr-WikiQA, a translation-based WikiQA dataset for 9 additional languages, and 2) TyDi-AS2, a multilingual AS2 dataset with over 70K questions spanning 8 typologically diverse languages. We conduct extensive experiments on Xtr-WikiQA and TyDi-AS2 with multiple teachers, diverse monolingual and multilingual pretrained language models (PLMs) as students, and both monolingual and multilingual training. The results demonstrate that CLKD either outperforms or rivals even supervised fine-tuning with the same amount of labeled data and a combination of machine translation and the teacher model. Our method can potentially enable stronger AS2 models for low-resource languages, while TyDi-AS2 can serve as the largest multilingual AS2 dataset for further studies in the research community.
Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery
Jun 21, 2022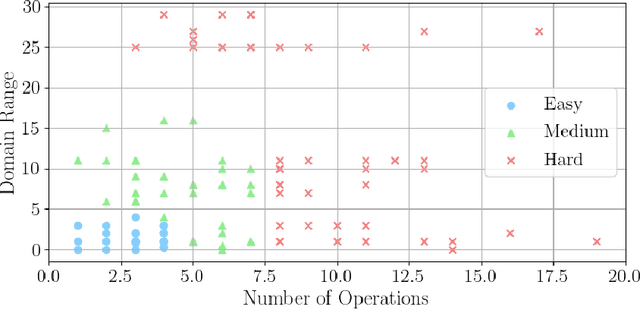
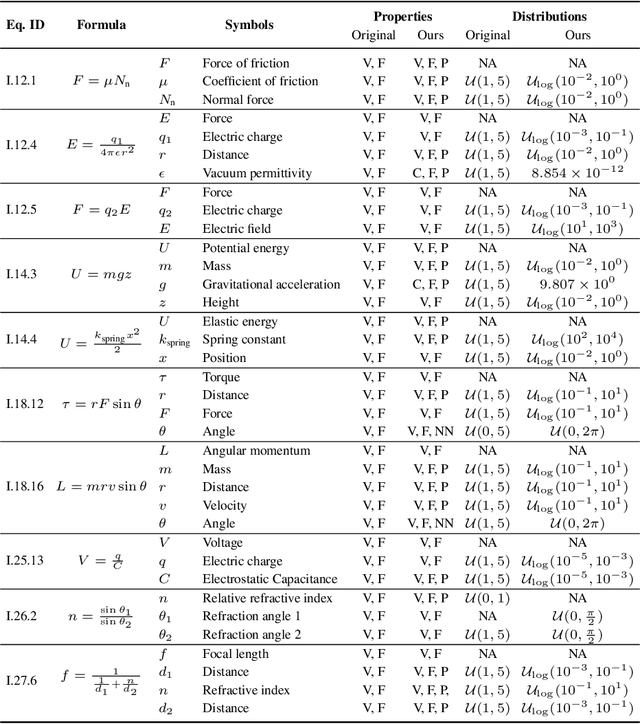


This paper revisits datasets and evaluation criteria for Symbolic Regression, a task of expressing given data using mathematical equations, specifically focused on its potential for scientific discovery. Focused on a set of formulas used in the existing datasets based on Feynman Lectures on Physics, we recreate 120 datasets to discuss the performance of symbolic regression for scientific discovery (SRSD). For each of the 120 SRSD datasets, we carefully review the properties of the formula and its variables to design reasonably realistic sampling range of values so that our new SRSD datasets can be used for evaluating the potential of SRSD such as whether or not an SR method con (re)discover physical laws from such datasets. As an evaluation metric, we also propose to use normalized edit distances between a predicted equation and the ground-truth equation trees. While existing metrics are either binary or errors between the target values and an SR model's predicted values for a given input, normalized edit distances evaluate a sort of similarity between the ground-truth and predicted equation trees. We have conducted experiments on our new SRSD datasets using five state-of-the-art SR methods in SRBench and a simple baseline based on a recent Transformer architecture. The results show that we provide a more realistic performance evaluation and open up a new machine learning-based approach for scientific discovery. Our datasets and code repository are publicly available.
SC2: Supervised Compression for Split Computing
Mar 16, 2022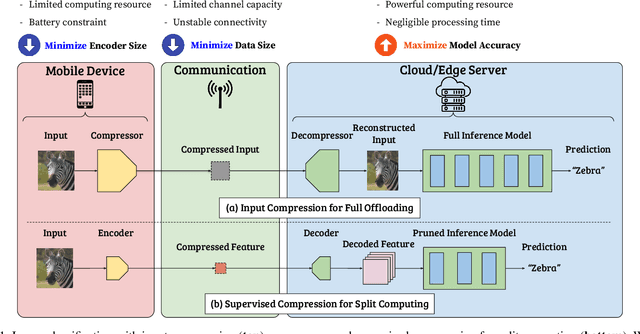
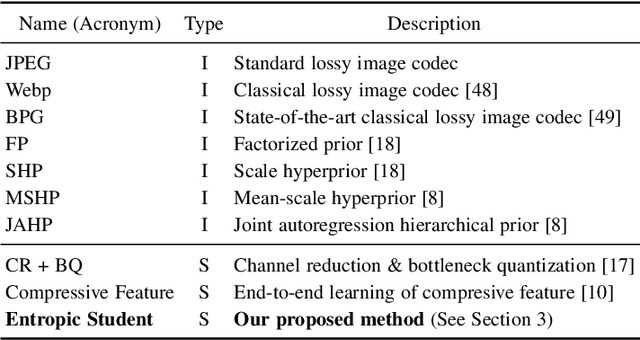
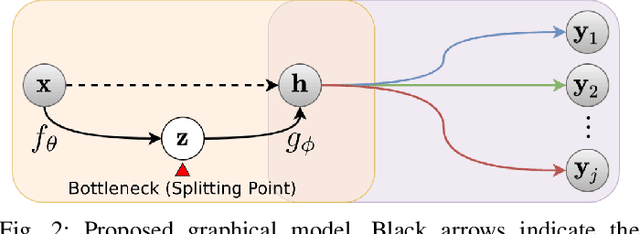
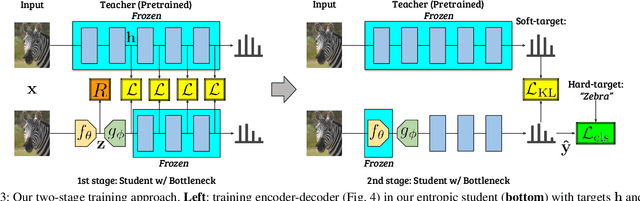
Split computing distributes the execution of a neural network (e.g., for a classification task) between a mobile device and a more powerful edge server. A simple alternative to splitting the network is to carry out the supervised task purely on the edge server while compressing and transmitting the full data, and most approaches have barely outperformed this baseline. This paper proposes a new approach for discretizing and entropy-coding intermediate feature activations to efficiently transmit them from the mobile device to the edge server. We show that a efficient splittable network architecture results from a three-way tradeoff between (a) minimizing the computation on the mobile device, (b) minimizing the size of the data to be transmitted, and (c) maximizing the model's prediction performance. We propose an architecture based on this tradeoff and train the splittable network and entropy model in a knowledge distillation framework. In an extensive set of experiments involving three vision tasks, three datasets, nine baselines, and more than 180 trained models, we show that our approach improves supervised rate-distortion tradeoffs while maintaining a considerably smaller encoder size. We also release sc2bench, an installable Python package, to encourage and facilitate future studies on supervised compression for split computing (SC2).
Ensemble Transformer for Efficient and Accurate Ranking Tasks: an Application to Question Answering Systems
Jan 15, 2022
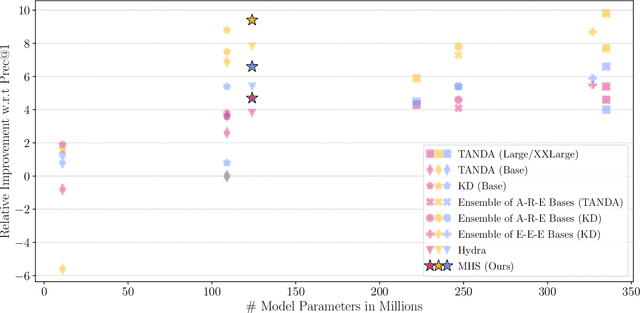

Large transformer models can highly improve Answer Sentence Selection (AS2) task, but their high computational costs prevent their use in many real world applications. In this paper, we explore the following research question: How can we make the AS2models more accurate without significantly increasing their model complexity? To address the question, we propose a Multiple Heads Student architecture (MHS), an efficient neural network designed to distill an ensemble of large transformers into a single smaller model. An MHS model consists of two components: a stack of transformer layers that is used to encode inputs, and a set of ranking heads; each of them is trained by distilling a different large transformer architecture. Unlike traditional distillation techniques, our approach leverages individual models in ensemble as teachers in a way that preserves the diversity of the ensemble members. The resulting model captures the knowledge of different types of transformer models by using just a few extra parameters. We show the effectiveness of MHS on three English datasets for AS2; our proposed approach outperforms all single-model distillations we consider, rivaling the state-of-the-art large AS2 models that have 2.7x more parameters and run 2.5x slower.
BottleFit: Learning Compressed Representations in Deep Neural Networks for Effective and Efficient Split Computing
Jan 07, 2022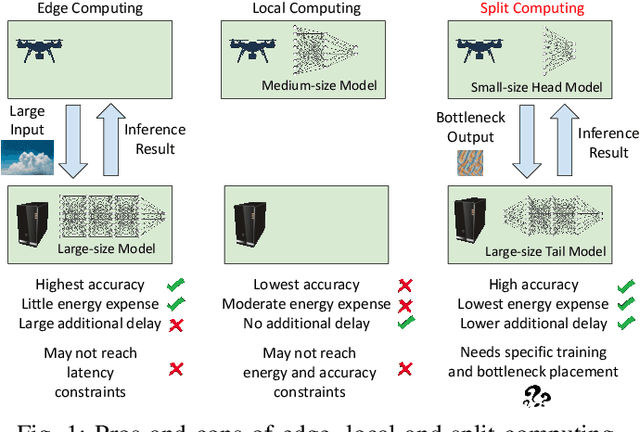
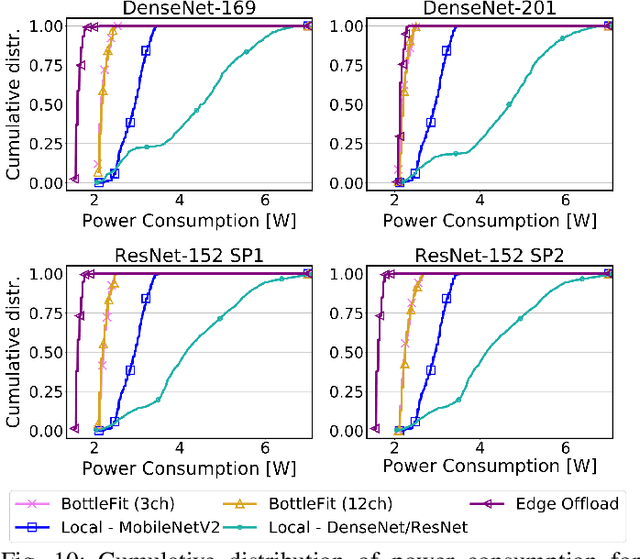
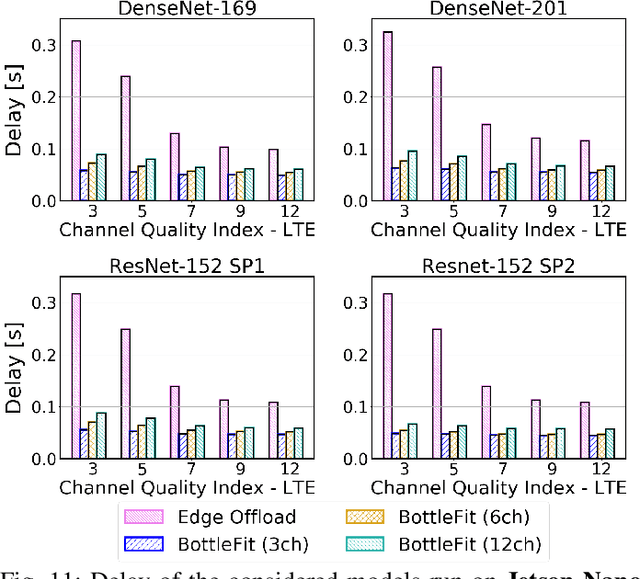
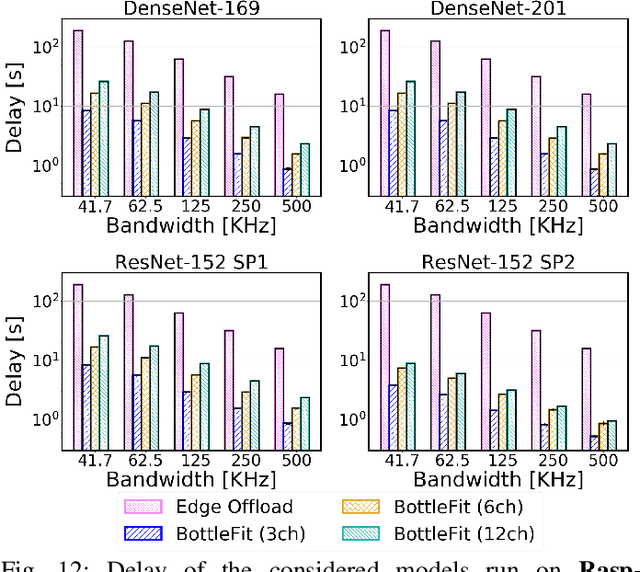
Although mission-critical applications require the use of deep neural networks (DNNs), their continuous execution at mobile devices results in a significant increase in energy consumption. While edge offloading can decrease energy consumption, erratic patterns in channel quality, network and edge server load can lead to severe disruption of the system's key operations. An alternative approach, called split computing, generates compressed representations within the model (called "bottlenecks"), to reduce bandwidth usage and energy consumption. Prior work has proposed approaches that introduce additional layers, to the detriment of energy consumption and latency. For this reason, we propose a new framework called BottleFit, which, in addition to targeted DNN architecture modifications, includes a novel training strategy to achieve high accuracy even with strong compression rates. We apply BottleFit on cutting-edge DNN models in image classification, and show that BottleFit achieves 77.1% data compression with up to 0.6% accuracy loss on ImageNet dataset, while state of the art such as SPINN loses up to 6% in accuracy. We experimentally measure the power consumption and latency of an image classification application running on an NVIDIA Jetson Nano board (GPU-based) and a Raspberry PI board (GPU-less). We show that BottleFit decreases power consumption and latency respectively by up to 49% and 89% with respect to (w.r.t.) local computing and by 37% and 55% w.r.t. edge offloading. We also compare BottleFit with state-of-the-art autoencoders-based approaches, and show that (i) BottleFit reduces power consumption and execution time respectively by up to 54% and 44% on the Jetson and 40% and 62% on Raspberry PI; (ii) the size of the head model executed on the mobile device is 83 times smaller. The code repository will be published for full reproducibility of the results.
Supervised Compression for Resource-constrained Edge Computing Systems
Aug 21, 2021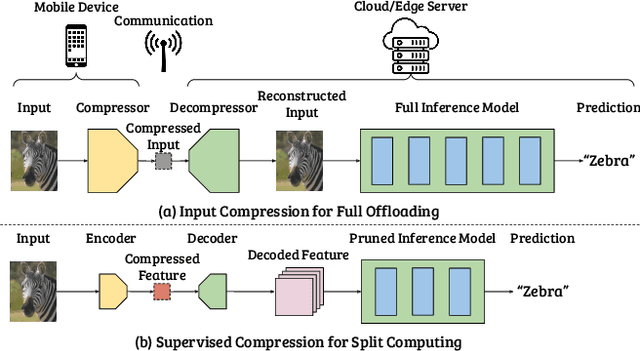
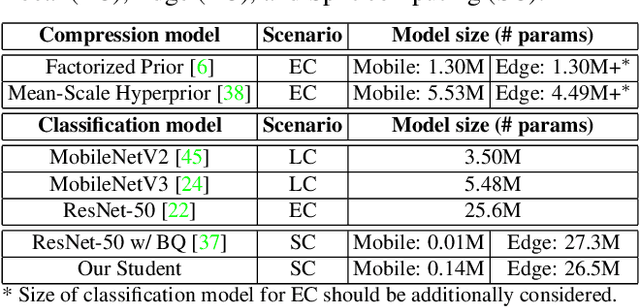
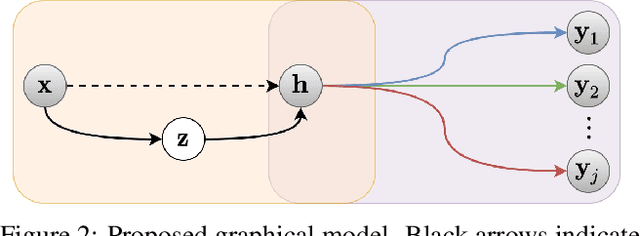
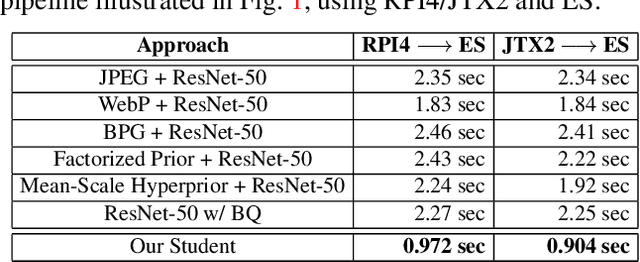
There has been much interest in deploying deep learning algorithms on low-powered devices, including smartphones, drones, and medical sensors. However, full-scale deep neural networks are often too resource-intensive in terms of energy and storage. As a result, the bulk part of the machine learning operation is therefore often carried out on an edge server, where the data is compressed and transmitted. However, compressing data (such as images) leads to transmitting information irrelevant to the supervised task. Another popular approach is to split the deep network between the device and the server while compressing intermediate features. To date, however, such split computing strategies have barely outperformed the aforementioned naive data compression baselines due to their inefficient approaches to feature compression. This paper adopts ideas from knowledge distillation and neural image compression to compress intermediate feature representations more efficiently. Our supervised compression approach uses a teacher model and a student model with a stochastic bottleneck and learnable prior for entropy coding. We compare our approach to various neural image and feature compression baselines in three vision tasks and found that it achieves better supervised rate-distortion performance while also maintaining smaller end-to-end latency. We furthermore show that the learned feature representations can be tuned to serve multiple downstream tasks.