 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrystalFramer: Rethinking the Role of Frames for SE(3)-Invariant Crystal Structure Modeling
Mar 04, 2025



Crystal structure modeling with graph neural networks is essential for various applications in materials informatics, and capturing SE(3)-invariant geometric features is a fundamental requirement for these networks. A straightforward approach is to model with orientation-standardized structures through structure-aligned coordinate systems, or"frames." However, unlike molecules, determining frames for crystal structures is challenging due to their infinite and highly symmetric nature. In particular, existing methods rely on a statically fixed frame for each structure, determined solely by its structural information, regardless of the task under consideration. Here, we rethink the role of frames, questioning whether such simplistic alignment with the structure is sufficient, and propose the concept of dynamic frames. While accommodating the infinite and symmetric nature of crystals, these frames provide each atom with a dynamic view of its local environment, focusing on actively interacting atoms. We demonstrate this concept by utilizing the attention mechanism in a recent transformer-based crystal encoder, resulting in a new architecture called CrystalFramer. Extensive experiments show that CrystalFramer outperforms conventional frames and existing crystal encoders in various crystal property prediction tasks.
MaterialBENCH: Evaluating College-Level Materials Science Problem-Solving Abilities of Large Language Models
Sep 05, 2024



A college-level benchmark dataset for large language models (LLMs) in the materials science field, MaterialBENCH, is constructed. This dataset consists of problem-answer pairs, based on university textbooks. There are two types of problems: one is the free-response answer type, and the other is the multiple-choice type. Multiple-choice problems are constructed by adding three incorrect answers as choices to a correct answer, so that LLMs can choose one of the four as a response. Most of the problems for free-response answer and multiple-choice types overlap except for the format of the answers. We also conduct experiments using the MaterialBENCH on LLMs, including ChatGPT-3.5, ChatGPT-4, Bard (at the time of the experiments), and GPT-3.5 and GPT-4 with the OpenAI API. The differences and similarities in the performance of LLMs measured by the MaterialBENCH are analyzed and discussed. Performance differences between the free-response type and multiple-choice type in the same models and the influence of using system massages on multiple-choice problems are also studied. We anticipate that MaterialBENCH will encourage further developments of LLMs in reasoning abilities to solve more complicated problems and eventually contribute to materials research and discovery.
Crystalformer: Infinitely Connected Attention for Periodic Structure Encoding
Mar 18, 2024



Predicting physical properties of materials from their crystal structures is a fundamental problem in materials science. In peripheral areas such as the prediction of molecular properties, fully connected attention networks have been shown to be successful. However, unlike these finite atom arrangements, crystal structures are infinitely repeating, periodic arrangements of atoms, whose fully connected attention results in infinitely connected attention. In this work, we show that this infinitely connected attention can lead to a computationally tractable formulation, interpreted as neural potential summation, that performs infinite interatomic potential summations in a deeply learned feature space. We then propose a simple yet effective Transformer-based encoder architecture for crystal structures called Crystalformer. Compared to an existing Transformer-based model, the proposed model requires only 29.4% of the number of parameters, with minimal modifications to the original Transformer architecture. Despite the architectural simplicity, the proposed method outperforms state-of-the-art methods for various property regression tasks on the Materials Project and JARVIS-DFT datasets.
A Transformer Model for Symbolic Regression towards Scientific Discovery
Dec 13, 2023



Symbolic Regression (SR) searches for mathematical expressions which best describe numerical datasets. This allows to circumvent interpretation issues inherent to artificial neural networks, but SR algorithms are often computationally expensive. This work proposes a new Transformer model aiming at Symbolic Regression particularly focused on its application for Scientific Discovery. We propose three encoder architectures with increasing flexibility but at the cost of column-permutation equivariance violation. Training results indicate that the most flexible architecture is required to prevent from overfitting. Once trained, we apply our best model to the SRSD datasets (Symbolic Regression for Scientific Discovery datasets) which yields state-of-the-art results using the normalized tree-based edit distance, at no extra computational cost.
Rethinking Symbolic Regression Datasets and Benchmarks for Scientific Discovery
Jun 21, 2022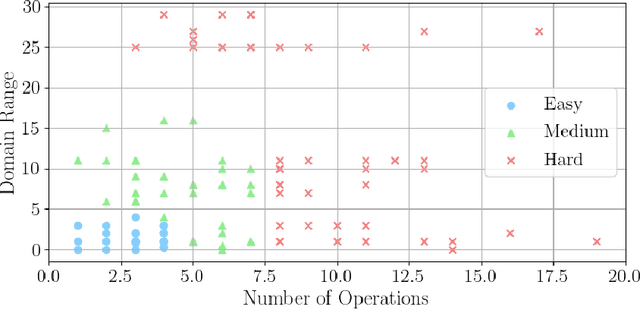
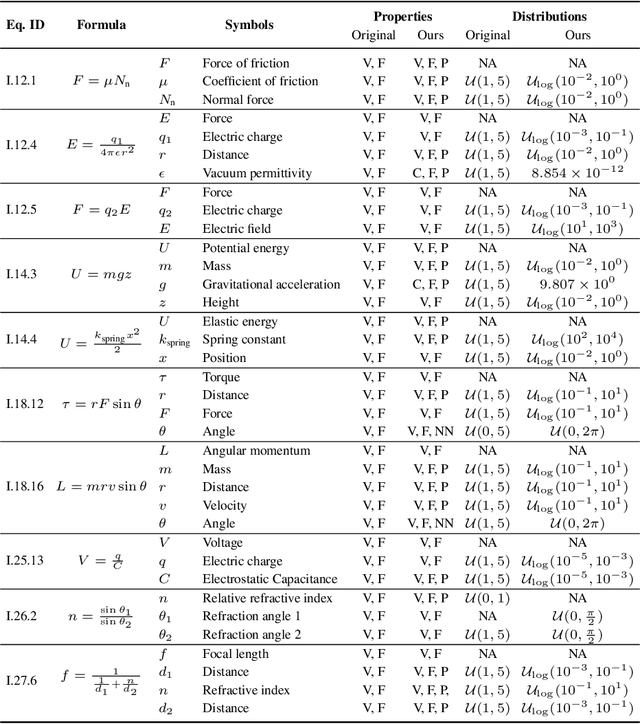


This paper revisits datasets and evaluation criteria for Symbolic Regression, a task of expressing given data using mathematical equations, specifically focused on its potential for scientific discovery. Focused on a set of formulas used in the existing datasets based on Feynman Lectures on Physics, we recreate 120 datasets to discuss the performance of symbolic regression for scientific discovery (SRSD). For each of the 120 SRSD datasets, we carefully review the properties of the formula and its variables to design reasonably realistic sampling range of values so that our new SRSD datasets can be used for evaluating the potential of SRSD such as whether or not an SR method con (re)discover physical laws from such datasets. As an evaluation metric, we also propose to use normalized edit distances between a predicted equation and the ground-truth equation trees. While existing metrics are either binary or errors between the target values and an SR model's predicted values for a given input, normalized edit distances evaluate a sort of similarity between the ground-truth and predicted equation trees. We have conducted experiments on our new SRSD datasets using five state-of-the-art SR methods in SRBench and a simple baseline based on a recent Transformer architecture. The results show that we provide a more realistic performance evaluation and open up a new machine learning-based approach for scientific discovery. Our datasets and code repository are publicly available.