 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Transformer for Efficient and Accurate Ranking Tasks: an Application to Question Answering Systems
Paper and Code

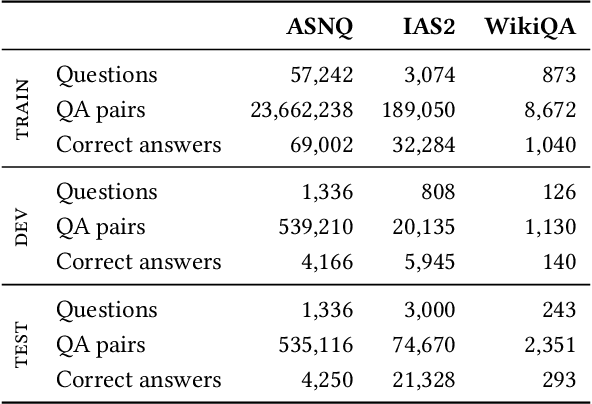
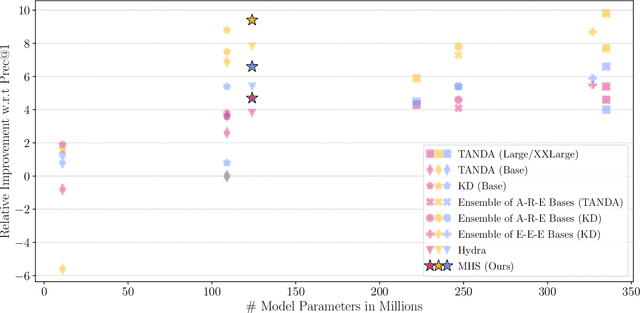

Large transformer models can highly improve Answer Sentence Selection (AS2) task, but their high computational costs prevent their use in many real world applications. In this paper, we explore the following research question: How can we make the AS2models more accurate without significantly increasing their model complexity? To address the question, we propose a Multiple Heads Student architecture (MHS), an efficient neural network designed to distill an ensemble of large transformers into a single smaller model. An MHS model consists of two components: a stack of transformer layers that is used to encode inputs, and a set of ranking heads; each of them is trained by distilling a different large transformer architecture. Unlike traditional distillation techniques, our approach leverages individual models in ensemble as teachers in a way that preserves the diversity of the ensemble members. The resulting model captures the knowledge of different types of transformer models by using just a few extra parameters. We show the effectiveness of MHS on three English datasets for AS2; our proposed approach outperforms all single-model distillations we consider, rivaling the state-of-the-art large AS2 models that have 2.7x more parameters and run 2.5x slower.