 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmix: A Framework for Data Mixing Throughout LM Development
Feb 12, 2026Data mixing -- determining the ratios of data from different domains -- is a first-order concern for training language models (LMs). While existing mixing methods show promise, they fall short when applied during real-world LM development. We present Olmix, a framework that addresses two such challenges. First, the configuration space for developing a mixing method is not well understood -- design choices across existing methods lack justification or consensus and overlook practical issues like data constraints. We conduct a comprehensive empirical study of this space, identifying which design choices lead to a strong mixing method. Second, in practice, the domain set evolves throughout LM development as datasets are added, removed, partitioned, and revised -- a problem setting largely unaddressed by existing works, which assume fixed domains. We study how to efficiently recompute the mixture after the domain set is updated, leveraging information from past mixtures. We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update. Over a sequence of five domain-set updates mirroring real-world LM development, mixture reuse matches the performance of fully recomputing the mix after each update with 74% less compute and improves over training without mixing by 11.6% on downstream tasks.
Overview of the TREC 2025 RAGTIME Track
Feb 10, 2026The principal goal of the RAG TREC Instrument for Multilingual Evaluation (RAGTIME) track at TREC is to study report generation from multilingual source documents. The track has created a document collection containing Arabic, Chinese, English, and Russian news stories. RAGTIME includes three task types: Multilingual Report Generation, English Report Generation, and Multilingual Information Retrieval (MLIR). A total of 125 runs were submitted by 13 participating teams (and as baselines by the track coordinators) for three tasks. This overview describes these three tasks and presents the available results.
How2Everything: Mining the Web for How-To Procedures to Evaluate and Improve LLMs
Feb 09, 2026Generating step-by-step "how-to" procedures is a key LLM capability: how-to advice is commonly requested in chatbots, and step-by-step planning is critical for reasoning over complex tasks. Yet, measuring and improving procedural validity at scale on real-world tasks remains challenging and understudied. To address this, we introduce How2Everything, a scalable framework to evaluate and improve goal-conditioned procedure generation. Our framework includes How2Mine, which mines 351K procedures from 980K web pages across 14 topics and readily scales to larger corpora. From this pool we build How2Bench, a 7K-example evaluation set balanced across topics. To reliably score model outputs, we develop How2Score, an evaluation protocol that uses an LLM judge to detect whether a generation contains any critical failure that would prevent achieving the goal. For low-cost, reproducible evaluation, we distill a frontier model into an open 8B model, achieving 80.5% agreement with human annotators. How2Bench reveals clear scaling trends across model sizes and training stages, providing signal early in pretraining. Finally, RL using How2Score as a reward improves performance on How2Bench by >10 points across three models without systematic regressions on standard benchmarks, with gains robust to superficial source-document memorization or format compliance. Taken together, How2Everything shows how pretraining web data can support a closed loop of capability evaluation and improvement at scale.
NeuCLIRTech: Chinese Monolingual and Cross-Language Information Retrieval Evaluation in a Challenging Domain
Feb 05, 2026Measuring advances in retrieval requires test collections with relevance judgments that can faithfully distinguish systems. This paper presents NeuCLIRTech, an evaluation collection for cross-language retrieval over technical information. The collection consists of technical documents written natively in Chinese and those same documents machine translated into English. It includes 110 queries with relevance judgments. The collection supports two retrieval scenarios: monolingual retrieval in Chinese, and cross-language retrieval with English as the query language. NeuCLIRTech combines the TREC NeuCLIR track topics of 2023 and 2024. The 110 queries with 35,962 document judgments provide strong statistical discriminatory power when trying to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included so that developers of reranking algorithms are not reliant on BM25 as their first stage retriever. The dataset and artifacts are released on Huggingface Datasets
Bolmo: Byteifying the Next Generation of Language Models
Dec 17, 2025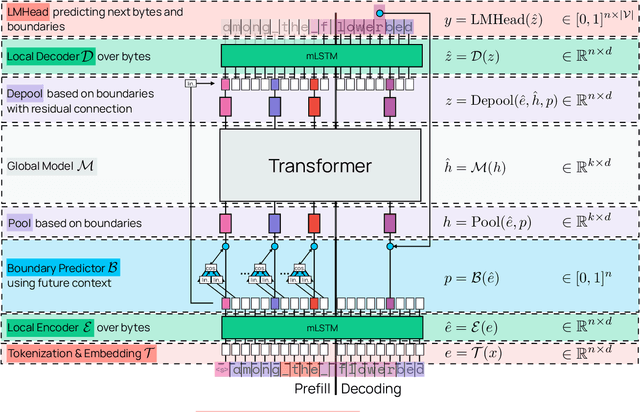
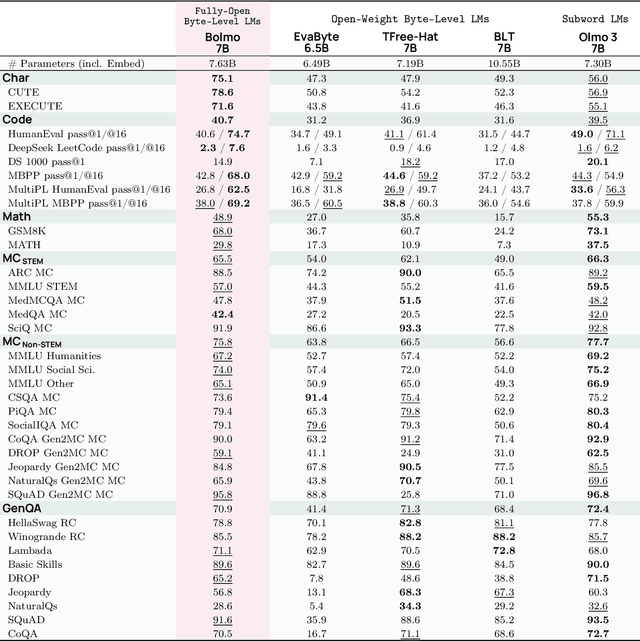
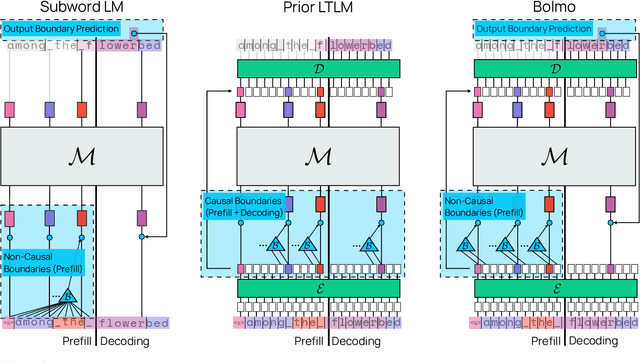
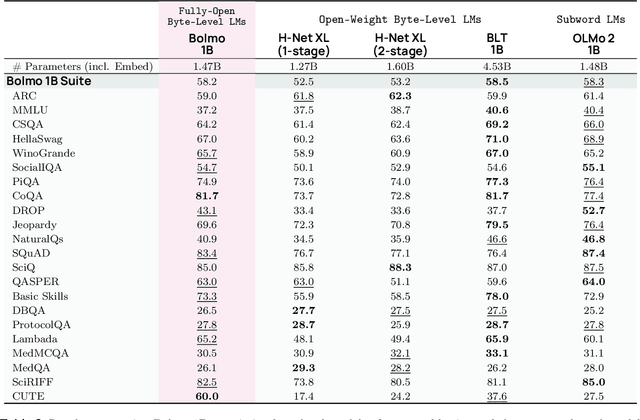
We introduce Bolmo, the first family of competitive fully open byte-level language models (LMs) at the 1B and 7B parameter scales. In contrast to prior research on byte-level LMs, which focuses predominantly on training from scratch, we train Bolmo by byteifying existing subword-level LMs. Byteification enables overcoming the limitations of subword tokenization - such as insufficient character understanding and efficiency constraints due to the fixed subword vocabulary - while performing at the level of leading subword-level LMs. Bolmo is specifically designed for byteification: our architecture resolves a mismatch between the expressivity of prior byte-level architectures and subword-level LMs, which makes it possible to employ an effective exact distillation objective between Bolmo and the source subword model. This allows for converting a subword-level LM to a byte-level LM by investing less than 1\% of a typical pretraining token budget. Bolmo substantially outperforms all prior byte-level LMs of comparable size, and outperforms the source subword-level LMs on character understanding and, in some cases, coding, while coming close to matching the original LMs' performance on other tasks. Furthermore, we show that Bolmo can achieve inference speeds competitive with subword-level LMs by training with higher token compression ratios, and can be cheaply and effectively post-trained by leveraging the existing ecosystem around the source subword-level LM. Our results finally make byte-level LMs a practical choice competitive with subword-level LMs across a wide set of use cases.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
olmOCR 2: Unit Test Rewards for Document OCR
Oct 22, 2025We present olmOCR 2, the latest in our family of powerful OCR systems for converting digitized print documents, like PDFs, into clean, naturally ordered plain text. olmOCR 2 is powered by olmOCR-2-7B-1025, a specialized, 7B vision language model (VLM) trained using reinforcement learning with verifiable rewards (RLVR), where our rewards are a diverse set of binary unit tests. To scale unit test creation, we develop a pipeline for generating synthetic documents with diverse and challenging layouts, known ground-truth HTML source code, and extracted test cases. We show that RL training on these test cases results in state-of-the-art performance on olmOCR-Bench, our English-language OCR benchmark, with the largest improvements in math formula conversion, table parsing, and multi-column layouts compared to previous versions. We release our model, data and code under permissive open licenses.
Overview of the TREC 2024 NeuCLIR Track
Sep 17, 2025The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the effect of neural approaches on cross-language information access. The track has created test collections containing Chinese, Persian, and Russian news stories and Chinese academic abstracts. NeuCLIR includes four task types: Cross-Language Information Retrieval (CLIR) from news, Multilingual Information Retrieval (MLIR) from news, Report Generation from news, and CLIR from technical documents. A total of 274 runs were submitted by five participating teams (and as baselines by the track coordinators) for eight tasks across these four task types. Task descriptions and the available results are presented.
FlexOlmo: Open Language Models for Flexible Data Use
Jul 09, 2025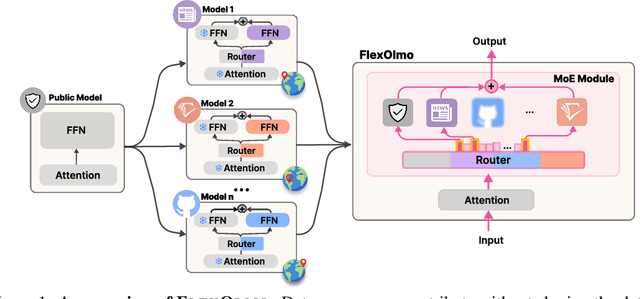
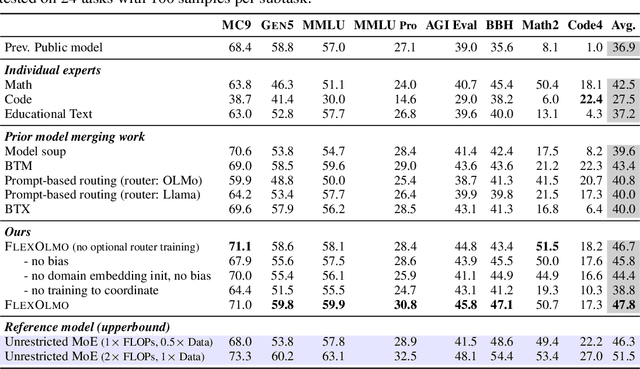
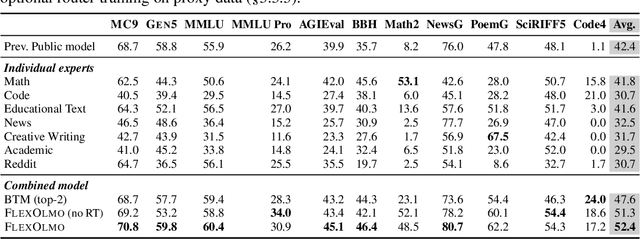
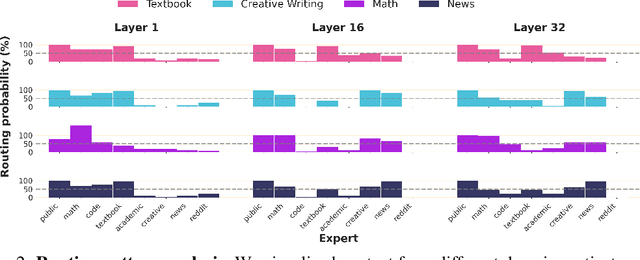
We introduce FlexOlmo, a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets. We evaluate models with up to 37 billion parameters (20 billion active) on 31 diverse downstream tasks. We show that a general expert trained on public data can be effectively combined with independently trained experts from other data owners, leading to an average 41% relative improvement while allowing users to opt out of certain data based on data licensing or permission requirements. Our approach also outperforms prior model merging methods by 10.1% on average and surpasses the standard MoE trained without data restrictions using the same training FLOPs. Altogether, this research presents a solution for both data owners and researchers in regulated industries with sensitive or protected data. FlexOlmo enables benefiting from closed data while respecting data owners' preferences by keeping their data local and supporting fine-grained control of data access during inference.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.