 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
Feb 25, 2025PDF documents have the potential to provide trillions of novel, high-quality tokens for training language models. However, these documents come in a diversity of types with differing formats and visual layouts that pose a challenge when attempting to extract and faithfully represent the underlying content for language model use. We present olmOCR, an open-source Python toolkit for processing PDFs into clean, linearized plain text in natural reading order while preserving structured content like sections, tables, lists, equations, and more. Our toolkit runs a fine-tuned 7B vision language model (VLM) trained on a sample of 260,000 pages from over 100,000 crawled PDFs with diverse properties, including graphics, handwritten text and poor quality scans. olmOCR is optimized for large-scale batch processing, able to scale flexibly to different hardware setups and convert a million PDF pages for only $190 USD. We release all components of olmOCR including VLM weights, data and training code, as well as inference code built on serving frameworks including vLLM and SGLang.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Delphi: Towards Machine Ethics and Norms
Oct 14, 2021
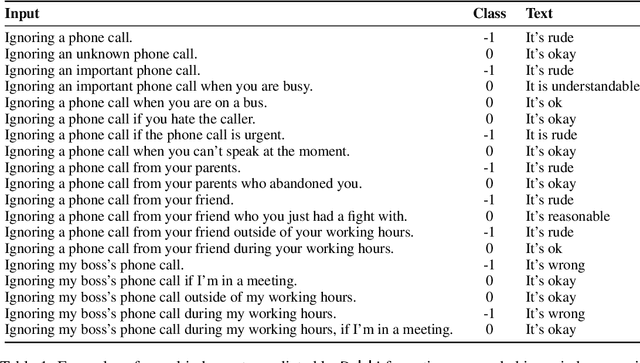
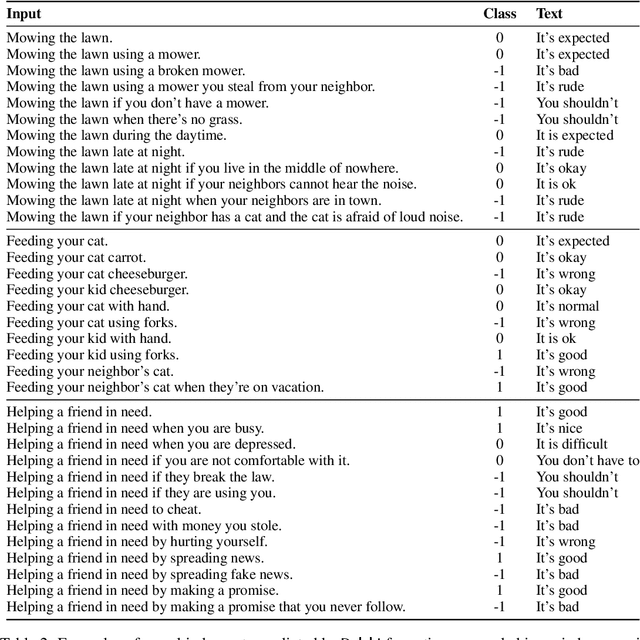

What would it take to teach a machine to behave ethically? While broad ethical rules may seem straightforward to state ("thou shalt not kill"), applying such rules to real-world situations is far more complex. For example, while "helping a friend" is generally a good thing to do, "helping a friend spread fake news" is not. We identify four underlying challenges towards machine ethics and norms: (1) an understanding of moral precepts and social norms; (2) the ability to perceive real-world situations visually or by reading natural language descriptions; (3) commonsense reasoning to anticipate the outcome of alternative actions in different contexts; (4) most importantly, the ability to make ethical judgments given the interplay between competing values and their grounding in different contexts (e.g., the right to freedom of expression vs. preventing the spread of fake news). Our paper begins to address these questions within the deep learning paradigm. Our prototype model, Delphi, demonstrates strong promise of language-based commonsense moral reasoning, with up to 92.1% accuracy vetted by humans. This is in stark contrast to the zero-shot performance of GPT-3 of 52.3%, which suggests that massive scale alone does not endow pre-trained neural language models with human values. Thus, we present Commonsense Norm Bank, a moral textbook customized for machines, which compiles 1.7M examples of people's ethical judgments on a broad spectrum of everyday situations. In addition to the new resources and baseline performances for future research, our study provides new insights that lead to several important open research questions: differentiating between universal human values and personal values, modeling different moral frameworks, and explainable, consistent approaches to machine ethics.