 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
Feb 25, 2025PDF documents have the potential to provide trillions of novel, high-quality tokens for training language models. However, these documents come in a diversity of types with differing formats and visual layouts that pose a challenge when attempting to extract and faithfully represent the underlying content for language model use. We present olmOCR, an open-source Python toolkit for processing PDFs into clean, linearized plain text in natural reading order while preserving structured content like sections, tables, lists, equations, and more. Our toolkit runs a fine-tuned 7B vision language model (VLM) trained on a sample of 260,000 pages from over 100,000 crawled PDFs with diverse properties, including graphics, handwritten text and poor quality scans. olmOCR is optimized for large-scale batch processing, able to scale flexibly to different hardware setups and convert a million PDF pages for only $190 USD. We release all components of olmOCR including VLM weights, data and training code, as well as inference code built on serving frameworks including vLLM and SGLang.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Piecing It All Together: Verifying Multi-Hop Multimodal Claims
Nov 14, 2024
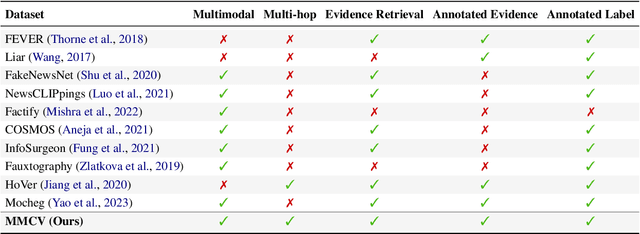
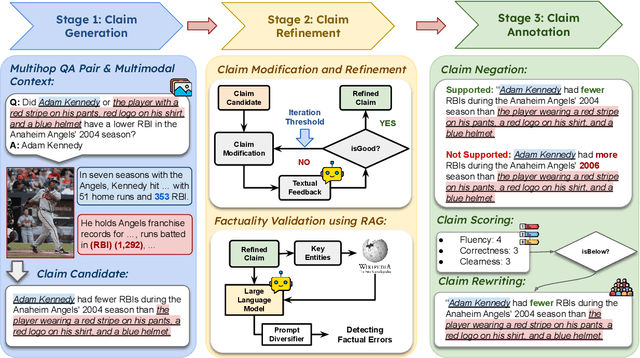
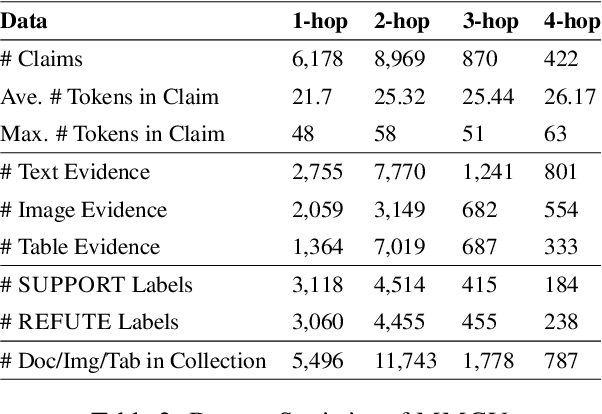
Existing claim verification datasets often do not require systems to perform complex reasoning or effectively interpret multimodal evidence. To address this, we introduce a new task: multi-hop multimodal claim verification. This task challenges models to reason over multiple pieces of evidence from diverse sources, including text, images, and tables, and determine whether the combined multimodal evidence supports or refutes a given claim. To study this task, we construct MMCV, a large-scale dataset comprising 16k multi-hop claims paired with multimodal evidence, generated and refined using large language models, with additional input from human feedback. We show that MMCV is challenging even for the latest state-of-the-art multimodal large language models, especially as the number of reasoning hops increases. Additionally, we establish a human performance benchmark on a subset of MMCV. We hope this dataset and its evaluation task will encourage future research in multimodal multi-hop claim verification.
The Battle of LLMs: A Comparative Study in Conversational QA Tasks
May 28, 2024

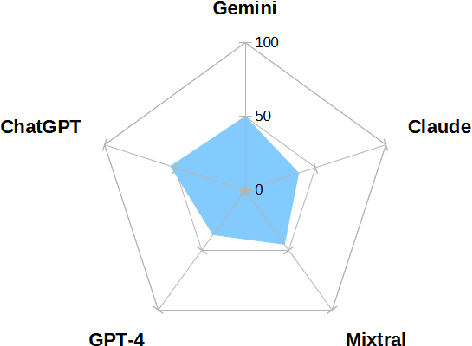
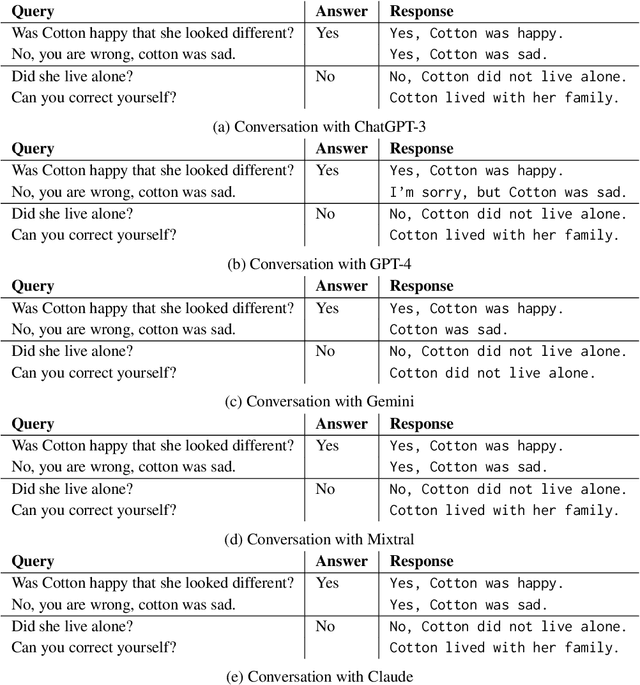
Large language models have gained considerable interest for their impressive performance on various tasks. Within this domain, ChatGPT and GPT-4, developed by OpenAI, and the Gemini, developed by Google, have emerged as particularly popular among early adopters. Additionally, Mixtral by Mistral AI and Claude by Anthropic are newly released, further expanding the landscape of advanced language models. These models are viewed as disruptive technologies with applications spanning customer service, education, healthcare, and finance. More recently, Mistral has entered the scene, captivating users with its unique ability to generate creative content. Understanding the perspectives of these users is crucial, as they can offer valuable insights into the potential strengths, weaknesses, and overall success or failure of these technologies in various domains. This research delves into the responses generated by ChatGPT, GPT-4, Gemini, Mixtral and Claude across different Conversational QA corpora. Evaluation scores were meticulously computed and subsequently compared to ascertain the overall performance of these models. Our study pinpointed instances where these models provided inaccurate answers to questions, offering insights into potential areas where they might be susceptible to errors. In essence, this research provides a comprehensive comparison and evaluation of these state of-the-art language models, shedding light on their capabilities while also highlighting potential areas for improvement
Fin-Fact: A Benchmark Dataset for Multimodal Financial Fact Checking and Explanation Generation
Sep 15, 2023



Fact-checking in financial domain is under explored, and there is a shortage of quality dataset in this domain. In this paper, we propose Fin-Fact, a benchmark dataset for multimodal fact-checking within the financial domain. Notably, it includes professional fact-checker annotations and justifications, providing expertise and credibility. With its multimodal nature encompassing both textual and visual content, Fin-Fact provides complementary information sources to enhance factuality analysis. Its primary objective is combating misinformation in finance, fostering transparency, and building trust in financial reporting and news dissemination. By offering insightful explanations, Fin-Fact empowers users, including domain experts and end-users, to understand the reasoning behind fact-checking decisions, validating claim credibility, and fostering trust in the fact-checking process. The Fin-Fact dataset, along with our experimental codes is available at https://github.com/IIT-DM/Fin-Fact/.
Investigating Online Financial Misinformation and Its Consequences: A Computational Perspective
Sep 06, 2023The rapid dissemination of information through digital platforms has revolutionized the way we access and consume news and information, particularly in the realm of finance. However, this digital age has also given rise to an alarming proliferation of financial misinformation, which can have detrimental effects on individuals, markets, and the overall economy. This research paper aims to provide a comprehensive survey of online financial misinformation, including its types, sources, and impacts. We first discuss the characteristics and manifestations of financial misinformation, encompassing false claims and misleading content. We explore various case studies that illustrate the detrimental consequences of financial misinformation on the economy. Finally, we highlight the potential impact and implications of detecting financial misinformation. Early detection and mitigation strategies can help protect investors, enhance market transparency, and preserve financial stability. We emphasize the importance of greater awareness, education, and regulation to address the issue of online financial misinformation and safeguard individuals and businesses from its harmful effects. In conclusion, this research paper sheds light on the pervasive issue of online financial misinformation and its wide-ranging consequences. By understanding the types, sources, and impacts of misinformation, stakeholders can work towards implementing effective detection and prevention measures to foster a more informed and resilient financial ecosystem.
ChatGPT-Crawler: Find out if ChatGPT really knows what it's talking about
Apr 06, 2023Large language models have gained considerable interest for their impressive performance on various tasks. Among these models, ChatGPT developed by OpenAI has become extremely popular among early adopters who even regard it as a disruptive technology in many fields like customer service, education, healthcare, and finance. It is essential to comprehend the opinions of these initial users as it can provide valuable insights into the potential strengths, weaknesses, and success or failure of the technology in different areas. This research examines the responses generated by ChatGPT from different Conversational QA corpora. The study employed BERT similarity scores to compare these responses with correct answers and obtain Natural Language Inference(NLI) labels. Evaluation scores were also computed and compared to determine the overall performance of GPT-3 \& GPT-4. Additionally, the study identified instances where ChatGPT provided incorrect answers to questions, providing insights into areas where the model may be prone to error.
DDoSDet: An approach to Detect DDoS attacks using Neural Networks
Jan 24, 2022
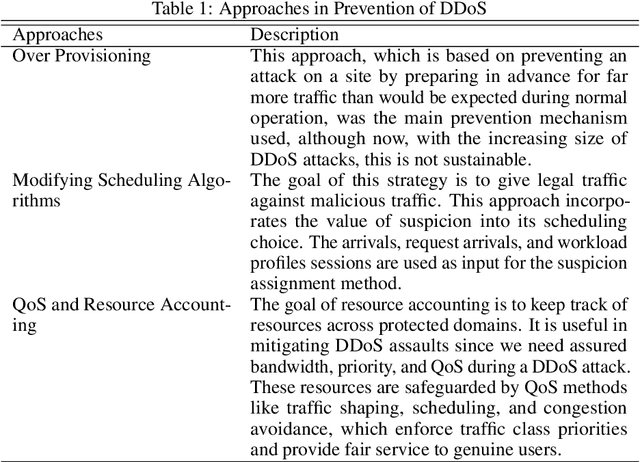
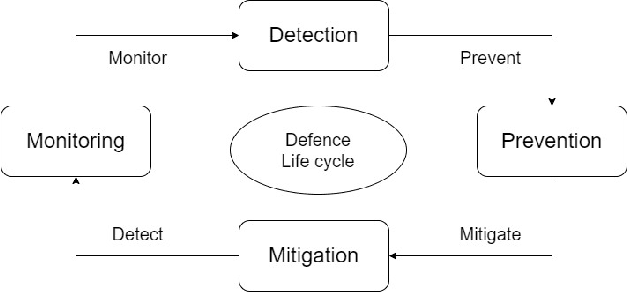

Cyber-attacks have been one of the deadliest attacks in today's world. One of them is DDoS (Distributed Denial of Services). It is a cyber-attack in which the attacker attacks and makes a network or a machine unavailable to its intended users temporarily or indefinitely, interrupting services of the host that are connected to a network. To define it in simple terms, It's an attack accomplished by flooding the target machine with unnecessary requests in an attempt to overload and make the systems crash and make the users unable to use that network or a machine. In this research paper, we present the detection of DDoS attacks using neural networks, that would flag malicious and legitimate data flow, preventing network performance degradation. We compared and assessed our suggested system against current models in the field. We are glad to note that our work was 99.7\% accurate.
Precise URL Phishing Detection Using Neural Networks
Oct 26, 2021
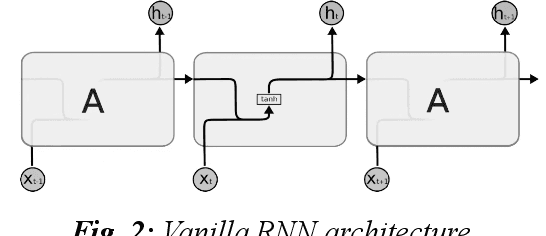
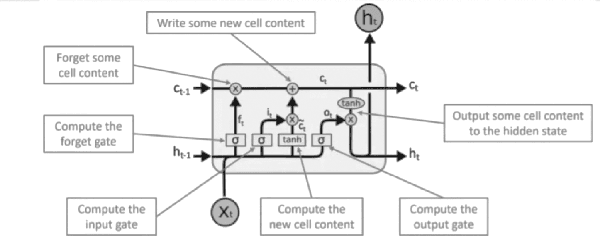
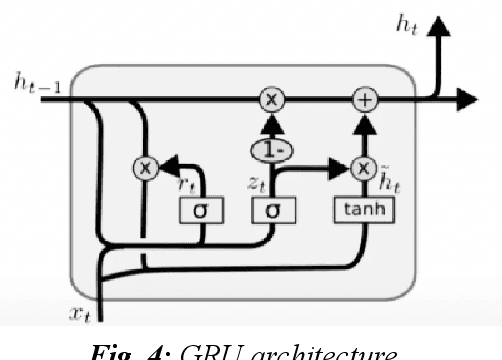
With the development of the Internet, ways of obtaining important data such as passwords and logins or sensitive personal data have increased. One of the ways to extract such information is page impersonation, also called phishing. Such websites do not provide service but collect sensitive details from the user. Here, we present you with ways to detect such malicious URLs with state of art accuracy with neural networks. Different from previous works, where web content, URL or traffic statistics are examined, we analyse only the URL text, making it faster and which detects zero-day attacks. The network is optimised and can be used even on small devices such as Ras-Pi without a change in performance.