 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multimodal LLMs Perform Time Series Anomaly Detection?
Feb 25, 2025



Large language models (LLMs) have been increasingly used in time series analysis. However, the potential of multimodal LLMs (MLLMs), particularly vision-language models, for time series remains largely under-explored. One natural way for humans to detect time series anomalies is through visualization and textual description. Motivated by this, we raise a critical and practical research question: Can multimodal LLMs perform time series anomaly detection? To answer this, we propose VisualTimeAnomaly benchmark to evaluate MLLMs in time series anomaly detection (TSAD). Our approach transforms time series numerical data into the image format and feed these images into various MLLMs, including proprietary models (GPT-4o and Gemini-1.5) and open-source models (LLaVA-NeXT and Qwen2-VL), each with one larger and one smaller variant. In total, VisualTimeAnomaly contains 12.4k time series images spanning 3 scenarios and 3 anomaly granularities with 9 anomaly types across 8 MLLMs. Starting with the univariate case (point- and range-wise anomalies), we extend our evaluation to more practical scenarios, including multivariate and irregular time series scenarios, and variate-wise anomalies. Our study reveals several key insights: 1) MLLMs detect range- and variate-wise anomalies more effectively than point-wise anomalies. 2) MLLMs are highly robust to irregular time series, even with 25% of the data missing. 3) Open-source MLLMs perform comparably to proprietary models in TSAD. While open-source MLLMs excel on univariate time series, proprietary MLLMs demonstrate superior effectiveness on multivariate time series. To the best of our knowledge, this is the first work to comprehensively investigate MLLMs for TSAD, particularly for multivariate and irregular time series scenarios. We release our dataset and code at https://github.com/mllm-ts/VisualTimeAnomaly to support future research.
Benchmarking LLMs for Political Science: A United Nations Perspective
Feb 19, 2025Large Language Models (LLMs) have achieved significant advances in natural language processing, yet their potential for high-stake political decision-making remains largely unexplored. This paper addresses the gap by focusing on the application of LLMs to the United Nations (UN) decision-making process, where the stakes are particularly high and political decisions can have far-reaching consequences. We introduce a novel dataset comprising publicly available UN Security Council (UNSC) records from 1994 to 2024, including draft resolutions, voting records, and diplomatic speeches. Using this dataset, we propose the United Nations Benchmark (UNBench), the first comprehensive benchmark designed to evaluate LLMs across four interconnected political science tasks: co-penholder judgment, representative voting simulation, draft adoption prediction, and representative statement generation. These tasks span the three stages of the UN decision-making process--drafting, voting, and discussing--and aim to assess LLMs' ability to understand and simulate political dynamics. Our experimental analysis demonstrates the potential and challenges of applying LLMs in this domain, providing insights into their strengths and limitations in political science. This work contributes to the growing intersection of AI and political science, opening new avenues for research and practical applications in global governance. The UNBench Repository can be accessed at: https://github.com/yueqingliang1/UNBench.
Graph-Sequential Alignment and Uniformity: Toward Enhanced Recommendation Systems
Dec 05, 2024



Graph-based and sequential methods are two popular recommendation paradigms, each excelling in its domain but lacking the ability to leverage signals from the other. To address this, we propose a novel method that integrates both approaches for enhanced performance. Our framework uses Graph Neural Network (GNN)-based and sequential recommenders as separate submodules while sharing a unified embedding space optimized jointly. To enable positive knowledge transfer, we design a loss function that enforces alignment and uniformity both within and across submodules. Experiments on three real-world datasets demonstrate that the proposed method significantly outperforms using either approach alone and achieves state-of-the-art results. Our implementations are publicly available at https://github.com/YuweiCao-UIC/GSAU.git.
Piecing It All Together: Verifying Multi-Hop Multimodal Claims
Nov 14, 2024
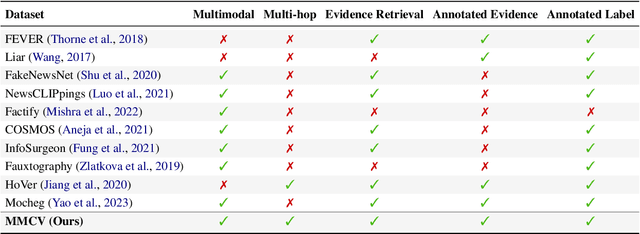
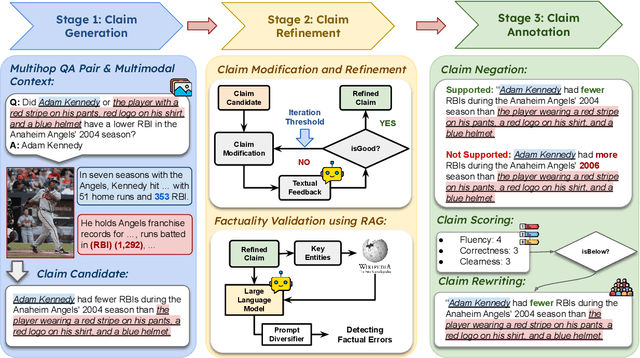
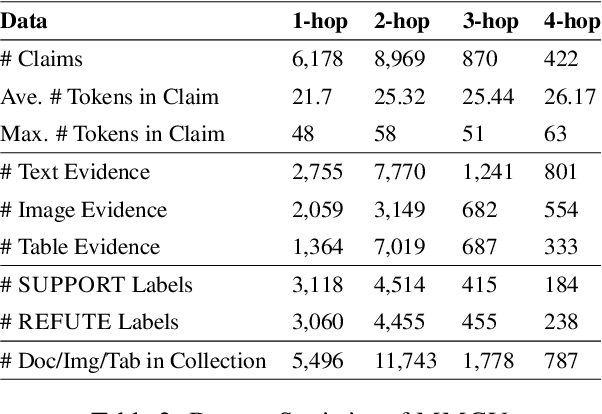
Existing claim verification datasets often do not require systems to perform complex reasoning or effectively interpret multimodal evidence. To address this, we introduce a new task: multi-hop multimodal claim verification. This task challenges models to reason over multiple pieces of evidence from diverse sources, including text, images, and tables, and determine whether the combined multimodal evidence supports or refutes a given claim. To study this task, we construct MMCV, a large-scale dataset comprising 16k multi-hop claims paired with multimodal evidence, generated and refined using large language models, with additional input from human feedback. We show that MMCV is challenging even for the latest state-of-the-art multimodal large language models, especially as the number of reasoning hops increases. Additionally, we establish a human performance benchmark on a subset of MMCV. We hope this dataset and its evaluation task will encourage future research in multimodal multi-hop claim verification.
Taxonomy-Guided Zero-Shot Recommendations with LLMs
Jun 20, 2024With the emergence of large language models (LLMs) and their ability to perform a variety of tasks, their application in recommender systems (RecSys) has shown promise. However, we are facing significant challenges when deploying LLMs into RecSys, such as limited prompt length, unstructured item information, and un-constrained generation of recommendations, leading to sub-optimal performance. To address these issues, we propose a novel method using a taxonomy dictionary. This method provides a systematic framework for categorizing and organizing items, improving the clarity and structure of item information. By incorporating the taxonomy dictionary into LLM prompts, we achieve efficient token utilization and controlled feature generation, leading to more accurate and contextually relevant recommendations. Our Taxonomy-guided Recommendation (TaxRec) approach features a two-step process: one-time taxonomy categorization and LLM-based recommendation, enabling zero-shot recommendations without the need for domain-specific fine-tuning. Experimental results demonstrate TaxRec significantly enhances recommendation quality compared to traditional zero-shot approaches, showcasing its efficacy as personal recommender with LLMs. Code is available at https://github.com/yueqingliang1/TaxRec.
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Apr 23, 2024
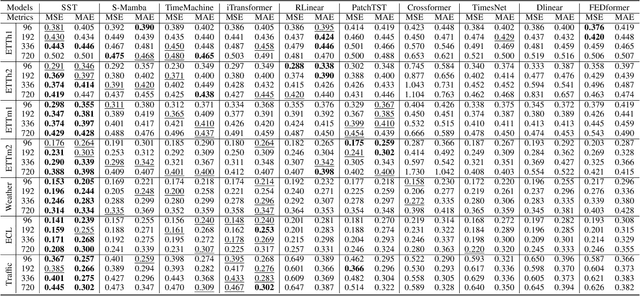
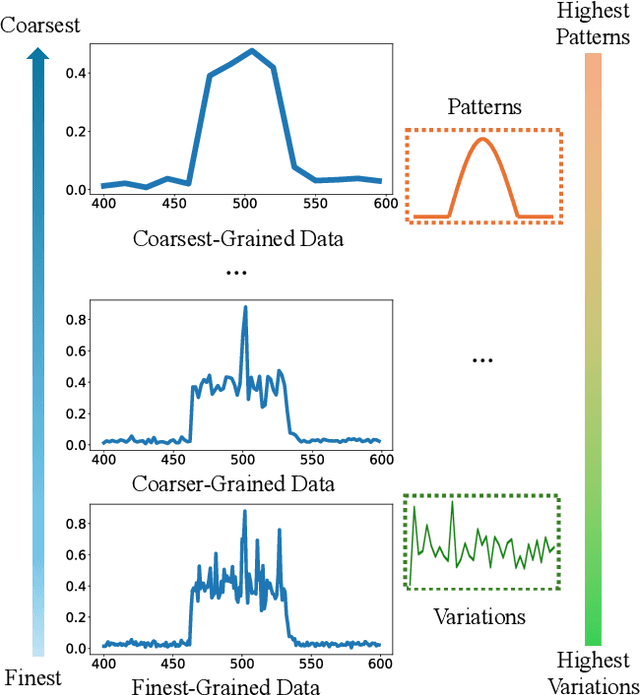
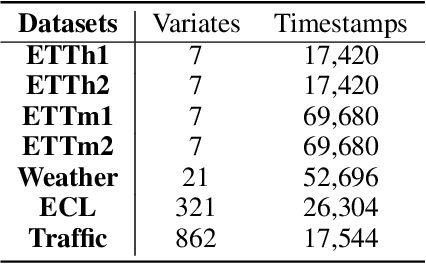
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
Confidence-aware Fine-tuning of Sequential Recommendation Systems via Conformal Prediction
Feb 14, 2024
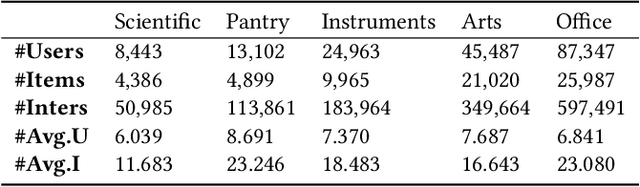
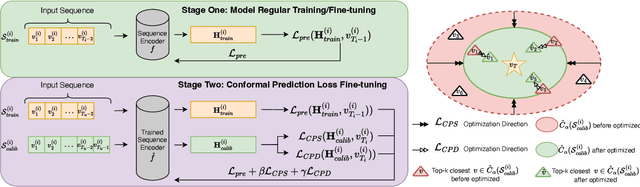

In Sequential Recommendation Systems, Cross-Entropy (CE) loss is commonly used but fails to harness item confidence scores during training. Recognizing the critical role of confidence in aligning training objectives with evaluation metrics, we propose CPFT, a versatile framework that enhances recommendation confidence by integrating Conformal Prediction (CP)-based losses with CE loss during fine-tuning. CPFT dynamically generates a set of items with a high probability of containing the ground truth, enriching the training process by incorporating validation data without compromising its role in model selection. This innovative approach, coupled with CP-based losses, sharpens the focus on refining recommendation sets, thereby elevating the confidence in potential item predictions. By fine-tuning item confidence through CP-based losses, CPFT significantly enhances model performance, leading to more precise and trustworthy recommendations that increase user trust and satisfaction. Our extensive evaluation across five diverse datasets and four distinct sequential models confirms CPFT's substantial impact on improving recommendation quality through strategic confidence optimization. Access to the framework's code will be provided following the acceptance of the paper.
Beyond Detection: Unveiling Fairness Vulnerabilities in Abusive Language Models
Dec 05, 2023



This work investigates the potential of undermining both fairness and detection performance in abusive language detection. In a dynamic and complex digital world, it is crucial to investigate the vulnerabilities of these detection models to adversarial fairness attacks to improve their fairness robustness. We propose a simple yet effective framework FABLE that leverages backdoor attacks as they allow targeted control over the fairness and detection performance. FABLE explores three types of trigger designs (i.e., rare, artificial, and natural triggers) and novel sampling strategies. Specifically, the adversary can inject triggers into samples in the minority group with the favored outcome (i.e., "non-abusive") and flip their labels to the unfavored outcome, i.e., "abusive". Experiments on benchmark datasets demonstrate the effectiveness of FABLE attacking fairness and utility in abusive language detection.
Collaborative Contextualization: Bridging the Gap between Collaborative Filtering and Pre-trained Language Model
Oct 13, 2023



Traditional recommender systems have heavily relied on identity representations (IDs) to model users and items, while the ascendancy of pre-trained language model (PLM) encoders has enriched the modeling of contextual item descriptions. However, PLMs, although effective in addressing few-shot, zero-shot, or unified modeling scenarios, often neglect the crucial collaborative filtering signal. This neglect gives rise to two pressing challenges: (1) Collaborative Contextualization, the seamless integration of collaborative signals with contextual representations. (2) the imperative to bridge the representation gap between ID-based representations and contextual representations while preserving their contextual semantics. In this paper, we propose CollabContext, a novel model that adeptly combines collaborative filtering signals with contextual representations and aligns these representations within the contextual space, preserving essential contextual semantics. Experimental results across three real-world datasets demonstrate substantial improvements. Leveraging collaborative contextualization, CollabContext can also be effectively applied to cold-start scenarios, achieving remarkable enhancements in recommendation performance. The code is available after the conference accepts the paper.
On Fair Classification with Mostly Private Sensitive Attributes
Jul 18, 2022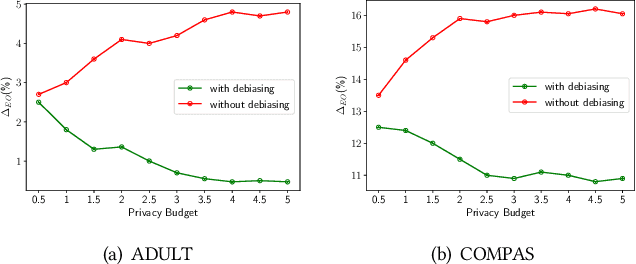
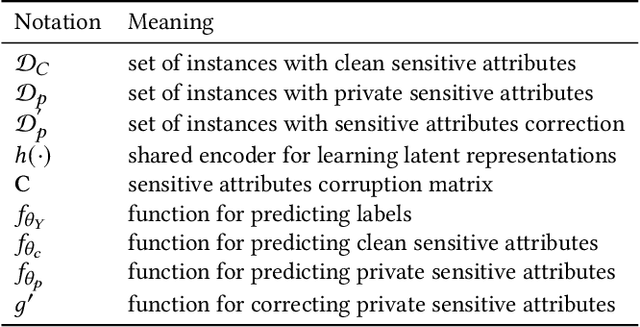
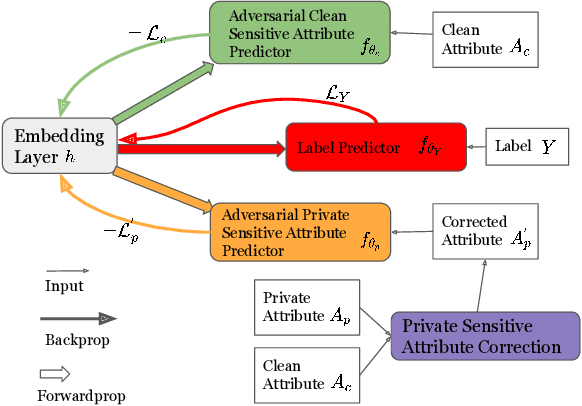
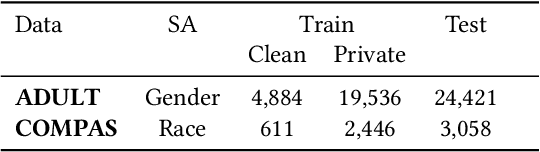
Machine learning models have demonstrated promising performance in many areas. However, the concerns that they can be biased against specific groups hinder their adoption in high-stake applications. Thus it is essential to ensure fairness in machine learning models. Most of the previous efforts require access to sensitive attributes for mitigating bias. Nonetheless, it is often infeasible to obtain large scale of data with sensitive attributes due to people's increasing awareness of privacy and the legal compliance. Therefore, an important research question is how to make fair predictions under privacy? In this paper, we study a novel problem on fair classification in a semi-private setting, where most of the sensitive attributes are private and only a small amount of clean sensitive attributes are available. To this end, we propose a novel framework FairSP that can first learn to correct the noisy sensitive attributes under privacy guarantee via exploiting the limited clean sensitive attributes. Then, it jointly models the corrected and clean data in an adversarial way for debiasing and prediction. Theoretical analysis shows that the proposed model can ensure fairness when most of the sensitive attributes are private. Experimental results on real-world datasets demonstrate the effectiveness of the proposed model for making fair predictions under privacy and maintaining high accuracy.