 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Fair Classification with Mostly Private Sensitive Attributes
Paper and Code
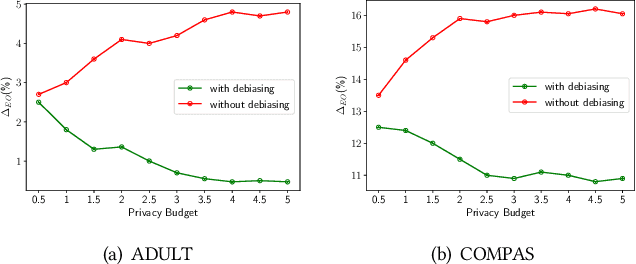
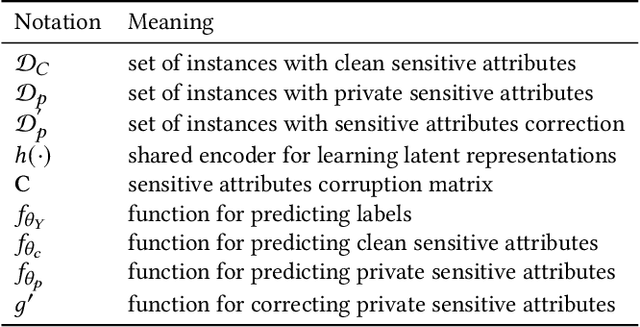
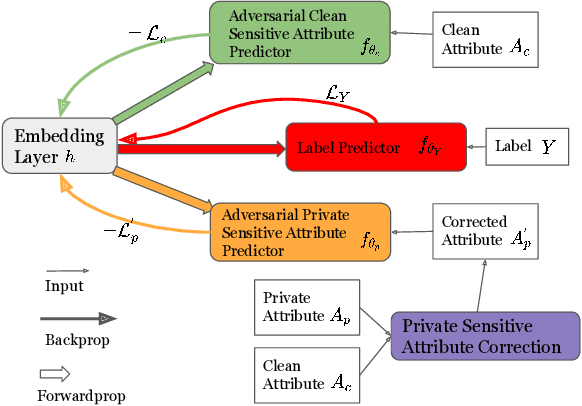
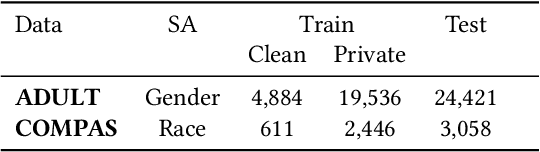
Machine learning models have demonstrated promising performance in many areas. However, the concerns that they can be biased against specific groups hinder their adoption in high-stake applications. Thus it is essential to ensure fairness in machine learning models. Most of the previous efforts require access to sensitive attributes for mitigating bias. Nonetheless, it is often infeasible to obtain large scale of data with sensitive attributes due to people's increasing awareness of privacy and the legal compliance. Therefore, an important research question is how to make fair predictions under privacy? In this paper, we study a novel problem on fair classification in a semi-private setting, where most of the sensitive attributes are private and only a small amount of clean sensitive attributes are available. To this end, we propose a novel framework FairSP that can first learn to correct the noisy sensitive attributes under privacy guarantee via exploiting the limited clean sensitive attributes. Then, it jointly models the corrected and clean data in an adversarial way for debiasing and prediction. Theoretical analysis shows that the proposed model can ensure fairness when most of the sensitive attributes are private. Experimental results on real-world datasets demonstrate the effectiveness of the proposed model for making fair predictions under privacy and maintaining high accuracy.