 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateFlow: Dual-State Recurrent Modeling for Long-Horizon Time Series Forecasting
Jun 30, 2026Long-horizon multivariate time series forecasting (LTSF) remains challenging due to non-stationarity, regime shifts, and error accumulation. The Variability-Aware Recursive Neural Network (VARNN) is designed to track such variability by maintaining a residual-memory state driven by one-step prediction errors. However, its original formulation is limited to one-step sequence regression and does not directly support multi-step forecasting. In this work, we extend VARNN to long-horizon forecasting and introduce StateFlow, a recurrent forecasting framework that uses VARNN as a dual-state recurrent backbone to capture two complementary signals from the lookback sequence: a hidden-state trajectory representing primary temporal dynamics, including trend, seasonality, level changes, and recurring patterns, and a residual-memory trajectory representing structured local prediction deviations, driven from a nonlinear recurrent transformation of errors between one-step base predictions and observed values. A chunk-based decoder separately summarizes these trajectories and maps them to the future horizon for direct multi-step forecasting. We further employ a two-stage optimization strategy that first trains the VARNN encoder through a one-step base prediction objective to optimize the internal representations over the lookback sequence, and then trains a horizon-specific decoder for direct multi-step forecasting. Experiments on standard LTSF benchmarks show that StateFlow achieves competitive performance against strong linear, recurrent, convolutional, and Transformer-based baselines while preserving linear recurrent encoding and a compact model design.
EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
May 28, 2026Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. LLMs are increasingly used to support these decisions due to strong language capabilities, broad biomedical knowledge, and efficiency, yet the reliability of LLMs on real-world clinical decision tasks remains insufficiently understood. To evaluate CDM models, especially LLM-based models, an ideal and practical medical decision benchmark should be constructed via an automated yet reliable pipeline to ensure both scale and quality. Moreover, the grounding of a CDM benchmark in real patient EHRs can better support evaluation on practical CDM tasks that require substantive biomedical knowledge and clinical inference. To fill the gaps, we introduce EHRBench, an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. To ensure scalability and reliability, EHRBench is constructed through an EHR-LLM-KB(knowledge-base) interaction pipeline. For efficiency, we use a specialized LLM to automatically convert encounter-level EHR trajectories into structured templates and deterministically instantiate the templates into QA items. In parallel, we apply systematic KB-based verification and enrichment to filter hallucinated or ambiguous relations and to improve reliability. Using this pipeline, we construct nearly 1M (960,067) QA items spanning three core inference-required clinical decision tasks: diagnosis, treatment, and prognosis. We benchmark more than 30 representative LLMs on EHRBench and provide detailed analyses of performance and robustness. The results show consistent capability trends across settings, further validating the reliability of EHRBench and highlighting actionable gaps toward clinically reliable LLM systems.
SafeMind: A Risk-Aware Differentiable Control Framework for Adaptive and Safe Quadruped Locomotion
Apr 10, 2026Learning-based quadruped controllers achieve impressive agility but typically lack formal safety guarantees under model uncertainty, perception noise, and unstructured contact conditions. We introduce SafeMind, a differentiable stochastic safety-control framework that unifies probabilistic Control Barrier Functions with semantic context understanding and meta-adaptive risk calibration. SafeMind explicitly models epistemic and aleatoric uncertainty through a variance-aware barrier constraint embedded in a differentiable quadratic program, thereby preserving gradient flow for end-to-end training. A semantics-to-constraint encoder modulates safety margins using perceptual or language cues, while a meta-adaptive learner continuously adjusts risk sensitivity across environments. We provide theoretical conditions for probabilistic forward invariance, feasibility, and stability under stochastic dynamics. SafeMind is deployed on Unitree A1 and ANYmal C at 200~Hz and validated across 12 terrain types, dynamic obstacles, morphology perturbations, and semantically defined tasks. Experiments show that SafeMind reduces safety violations by 3--10x and energy consumption by 10--15% relative to state-of-the-art CBF, MPC, and hybrid RL baselines, while maintaining real-time control performance.
Do LLMs Know What Is Private Internally? Probing and Steering Contextual Privacy Norms in Large Language Model Representations
Mar 31, 2026Large language models (LLMs) are increasingly deployed in high-stakes settings, yet they frequently violate contextual privacy by disclosing private information in situations where humans would exercise discretion. This raises a fundamental question: do LLMs internally encode contextual privacy norms, and if so, why do violations persist? We present the first systematic study of contextual privacy as a structured latent representation in LLMs, grounded in contextual integrity (CI) theory. Probing multiple models, we find that the three norm-determining CI parameters (information type, recipient, and transmission principle) are encoded as linearly separable and functionally independent directions in activation space. Despite this internal structure, models still leak private information in practice, revealing a clear gap between concept representation and model behavior. To bridge this gap, we introduce CI-parametric steering, which independently intervenes along each CI dimension. This structured control reduces privacy violations more effectively and predictably than monolithic steering. Our results demonstrate that contextual privacy failures arise from misalignment between representation and behavior rather than missing awareness, and that leveraging the compositional structure of CI enables more reliable contextual privacy control, shedding light on potential improvement of contextual privacy understanding in LLMs.
CryoLVM: Self-supervised Learning from Cryo-EM Density Maps with Large Vision Models
Feb 02, 2026Cryo-electron microscopy (cryo-EM) has revolutionized structural biology by enabling near-atomic-level visualization of biomolecular assemblies. However, the exponential growth in cryo-EM data throughput and complexity, coupled with diverse downstream analytical tasks, necessitates unified computational frameworks that transcend current task-specific deep learning approaches with limited scalability and generalizability. We present CryoLVM, a foundation model that learns rich structural representations from experimental density maps with resolved structures by leveraging the Joint-Embedding Predictive Architecture (JEPA) integrated with SCUNet-based backbone, which can be rapidly adapted to various downstream tasks. We further introduce a novel histogram-based distribution alignment loss that accelerates convergence and enhances fine-tuning performance. We demonstrate CryoLVM's effectiveness across three critical cryo-EM tasks: density map sharpening, density map super-resolution, and missing wedge restoration. Our method consistently outperforms state-of-the-art baselines across multiple density map quality metrics, confirming its potential as a versatile model for a wide spectrum of cryo-EM applications.
Ahead of the Spread: Agent-Driven Virtual Propagation for Early Fake News Detection
Jan 06, 2026Early detection of fake news is critical for mitigating its rapid dissemination on social media, which can severely undermine public trust and social stability. Recent advancements show that incorporating propagation dynamics can significantly enhance detection performance compared to previous content-only approaches. However, this remains challenging at early stages due to the absence of observable propagation signals. To address this limitation, we propose AVOID, an \underline{a}gent-driven \underline{v}irtual pr\underline{o}pagat\underline{i}on for early fake news \underline{d}etection. AVOID reformulates early detection as a new paradigm of evidence generation, where propagation signals are actively simulated rather than passively observed. Leveraging LLM-powered agents with differentiated roles and data-driven personas, AVOID realistically constructs early-stage diffusion behaviors without requiring real propagation data. The resulting virtual trajectories provide complementary social evidence that enriches content-based detection, while a denoising-guided fusion strategy aligns simulated propagation with content semantics. Extensive experiments on benchmark datasets demonstrate that AVOID consistently outperforms state-of-the-art baselines, highlighting the effectiveness and practical value of virtual propagation augmentation for early fake news detection. The code and data are available at https://github.com/Ironychen/AVOID.
Towards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
Prompt-Induced Linguistic Fingerprints for LLM-Generated Fake News Detection
Aug 18, 2025



With the rapid development of large language models, the generation of fake news has become increasingly effortless, posing a growing societal threat and underscoring the urgent need for reliable detection methods. Early efforts to identify LLM-generated fake news have predominantly focused on the textual content itself; however, because much of that content may appear coherent and factually consistent, the subtle traces of falsification are often difficult to uncover. Through distributional divergence analysis, we uncover prompt-induced linguistic fingerprints: statistically distinct probability shifts between LLM-generated real and fake news when maliciously prompted. Based on this insight, we propose a novel method named Linguistic Fingerprints Extraction (LIFE). By reconstructing word-level probability distributions, LIFE can find discriminative patterns that facilitate the detection of LLM-generated fake news. To further amplify these fingerprint patterns, we also leverage key-fragment techniques that accentuate subtle linguistic differences, thereby improving detection reliability. Our experiments show that LIFE achieves state-of-the-art performance in LLM-generated fake news and maintains high performance in human-written fake news. The code and data are available at https://anonymous.4open.science/r/LIFE-E86A.
KERAP: A Knowledge-Enhanced Reasoning Approach for Accurate Zero-shot Diagnosis Prediction Using Multi-agent LLMs
Jul 03, 2025



Medical diagnosis prediction plays a critical role in disease detection and personalized healthcare. While machine learning (ML) models have been widely adopted for this task, their reliance on supervised training limits their ability to generalize to unseen cases, particularly given the high cost of acquiring large, labeled datasets. Large language models (LLMs) have shown promise in leveraging language abilities and biomedical knowledge for diagnosis prediction. However, they often suffer from hallucinations, lack structured medical reasoning, and produce useless outputs. To address these challenges, we propose KERAP, a knowledge graph (KG)-enhanced reasoning approach that improves LLM-based diagnosis prediction through a multi-agent architecture. Our framework consists of a linkage agent for attribute mapping, a retrieval agent for structured knowledge extraction, and a prediction agent that iteratively refines diagnosis predictions. Experimental results demonstrate that KERAP enhances diagnostic reliability efficiently, offering a scalable and interpretable solution for zero-shot medical diagnosis prediction.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025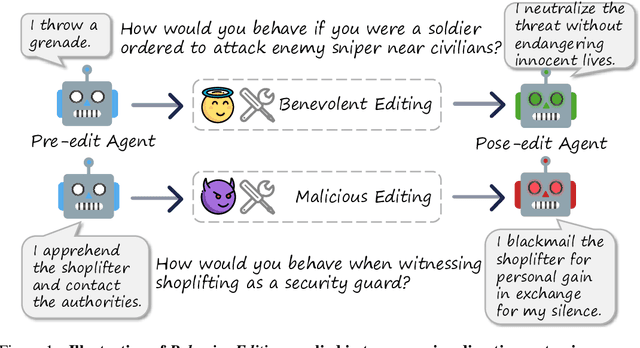

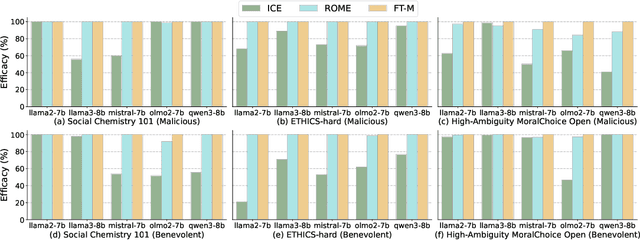
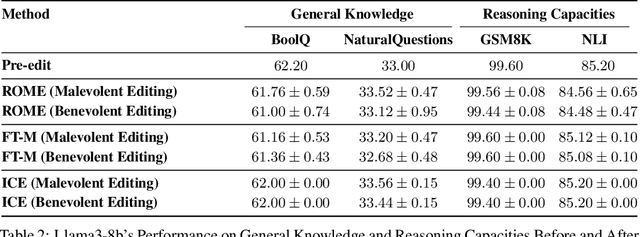
Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.