 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
May 28, 2026Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. LLMs are increasingly used to support these decisions due to strong language capabilities, broad biomedical knowledge, and efficiency, yet the reliability of LLMs on real-world clinical decision tasks remains insufficiently understood. To evaluate CDM models, especially LLM-based models, an ideal and practical medical decision benchmark should be constructed via an automated yet reliable pipeline to ensure both scale and quality. Moreover, the grounding of a CDM benchmark in real patient EHRs can better support evaluation on practical CDM tasks that require substantive biomedical knowledge and clinical inference. To fill the gaps, we introduce EHRBench, an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. To ensure scalability and reliability, EHRBench is constructed through an EHR-LLM-KB(knowledge-base) interaction pipeline. For efficiency, we use a specialized LLM to automatically convert encounter-level EHR trajectories into structured templates and deterministically instantiate the templates into QA items. In parallel, we apply systematic KB-based verification and enrichment to filter hallucinated or ambiguous relations and to improve reliability. Using this pipeline, we construct nearly 1M (960,067) QA items spanning three core inference-required clinical decision tasks: diagnosis, treatment, and prognosis. We benchmark more than 30 representative LLMs on EHRBench and provide detailed analyses of performance and robustness. The results show consistent capability trends across settings, further validating the reliability of EHRBench and highlighting actionable gaps toward clinically reliable LLM systems.
LLM-MINE: Large Language Model based Alzheimer's Disease and Related Dementias Phenotypes Mining from Clinical Notes
Mar 14, 2026Accurate extraction of Alzheimer's Disease and Related Dementias (ADRD) phenotypes from electronic health records (EHR) is critical for early-stage detection and disease staging. However, this information is usually embedded in unstructured textual data rather than tabular data, making it difficult to be extracted accurately. We therefore propose LLM-MINE, a Large Language Model-based phenotype mining framework for automatic extraction of ADRD phenotypes from clinical notes. Using two expert-defined phenotype lists, we evaluate the extracted phenotypes by examining their statistical significance across cohorts and their utility for unsupervised disease staging. Chi-square analyses confirm statistically significant phenotype differences across cohorts, with memory impairment being the strongest discriminator. Few-shot prompting with the combined phenotype lists achieves the best clustering performance (ARI=0.290, NMI=0.232), substantially outperforming biomedical NER and dictionary-based baselines. Our results demonstrate that LLM-based phenotype extraction is a promising tool for discovering clinically meaningful ADRD signals from unstructured notes.
BioMedJImpact: A Comprehensive Dataset and LLM Pipeline for AI Engagement and Scientific Impact Analysis of Biomedical Journals
Nov 16, 2025Assessing journal impact is central to scholarly communication, yet existing open resources rarely capture how collaboration structures and artificial intelligence (AI) research jointly shape venue prestige in biomedicine. We present BioMedJImpact, a large-scale, biomedical-oriented dataset designed to advance journal-level analysis of scientific impact and AI engagement. Built from 1.74 million PubMed Central articles across 2,744 journals, BioMedJImpact integrates bibliometric indicators, collaboration features, and LLM-derived semantic indicators for AI engagement. Specifically, the AI engagement feature is extracted through a reproducible three-stage LLM pipeline that we propose. Using this dataset, we analyze how collaboration intensity and AI engagement jointly influence scientific impact across pre- and post-pandemic periods (2016-2019, 2020-2023). Two consistent trends emerge: journals with higher collaboration intensity, particularly those with larger and more diverse author teams, tend to achieve greater citation impact, and AI engagement has become an increasingly strong correlate of journal prestige, especially in quartile rankings. To further validate the three-stage LLM pipeline we proposed for deriving the AI engagement feature, we conduct human evaluation, confirming substantial agreement in AI relevance detection and consistent subfield classification. Together, these contributions demonstrate that BioMedJImpact serves as both a comprehensive dataset capturing the intersection of biomedicine and AI, and a validated methodological framework enabling scalable, content-aware scientometric analysis of scientific impact and innovation dynamics. Code is available at https://github.com/JonathanWry/BioMedJImpact.
Generalist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025
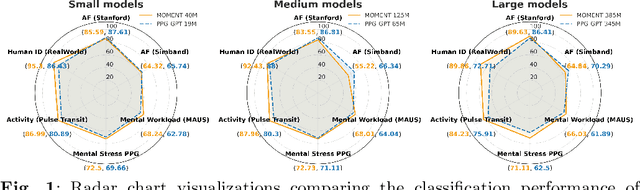
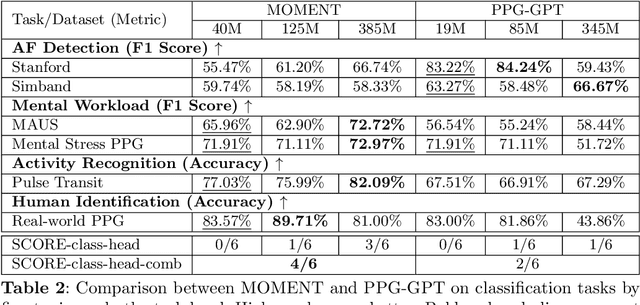
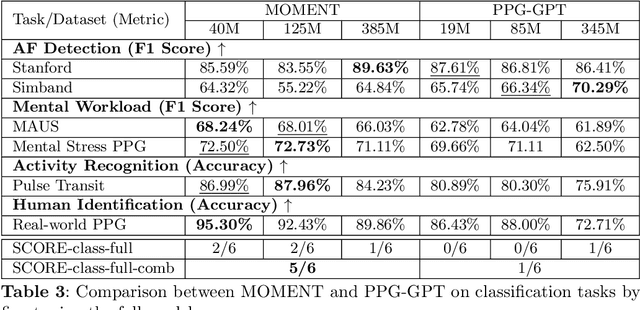
Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
Longitudinal Progression Prediction of Alzheimer's Disease with Tabular Foundation Model
Aug 25, 2025Alzheimer's disease is a progressive neurodegenerative disorder that remains challenging to predict due to its multifactorial etiology and the complexity of multimodal clinical data. Accurate forecasting of clinically relevant biomarkers, including diagnostic and quantitative measures, is essential for effective monitoring of disease progression. This work introduces L2C-TabPFN, a method that integrates a longitudinal-to-cross-sectional (L2C) transformation with a pre-trained Tabular Foundation Model (TabPFN) to predict Alzheimer's disease outcomes using the TADPOLE dataset. L2C-TabPFN converts sequential patient records into fixed-length feature vectors, enabling robust prediction of diagnosis, cognitive scores, and ventricular volume. Experimental results demonstrate that, while L2C-TabPFN achieves competitive performance on diagnostic and cognitive outcomes, it provides state-of-the-art results in ventricular volume prediction. This key imaging biomarker reflects neurodegeneration and progression in Alzheimer's disease. These findings highlight the potential of tabular foundational models for advancing longitudinal prediction of clinically relevant imaging markers in Alzheimer's disease.
KERAP: A Knowledge-Enhanced Reasoning Approach for Accurate Zero-shot Diagnosis Prediction Using Multi-agent LLMs
Jul 03, 2025



Medical diagnosis prediction plays a critical role in disease detection and personalized healthcare. While machine learning (ML) models have been widely adopted for this task, their reliance on supervised training limits their ability to generalize to unseen cases, particularly given the high cost of acquiring large, labeled datasets. Large language models (LLMs) have shown promise in leveraging language abilities and biomedical knowledge for diagnosis prediction. However, they often suffer from hallucinations, lack structured medical reasoning, and produce useless outputs. To address these challenges, we propose KERAP, a knowledge graph (KG)-enhanced reasoning approach that improves LLM-based diagnosis prediction through a multi-agent architecture. Our framework consists of a linkage agent for attribute mapping, a retrieval agent for structured knowledge extraction, and a prediction agent that iteratively refines diagnosis predictions. Experimental results demonstrate that KERAP enhances diagnostic reliability efficiently, offering a scalable and interpretable solution for zero-shot medical diagnosis prediction.
Large Language Model Empowered Privacy-Protected Framework for PHI Annotation in Clinical Notes
Apr 22, 2025
The de-identification of private information in medical data is a crucial process to mitigate the risk of confidentiality breaches, particularly when patient personal details are not adequately removed before the release of medical records. Although rule-based and learning-based methods have been proposed, they often struggle with limited generalizability and require substantial amounts of annotated data for effective performance. Recent advancements in large language models (LLMs) have shown significant promise in addressing these issues due to their superior language comprehension capabilities. However, LLMs present challenges, including potential privacy risks when using commercial LLM APIs and high computational costs for deploying open-source LLMs locally. In this work, we introduce LPPA, an LLM-empowered Privacy-Protected PHI Annotation framework for clinical notes, targeting the English language. By fine-tuning LLMs locally with synthetic notes, LPPA ensures strong privacy protection and high PHI annotation accuracy. Extensive experiments demonstrate LPPA's effectiveness in accurately de-identifying private information, offering a scalable and efficient solution for enhancing patient privacy protection.
Continuous Cardiac Arrest Prediction in ICU using PPG Foundation Model
Feb 12, 2025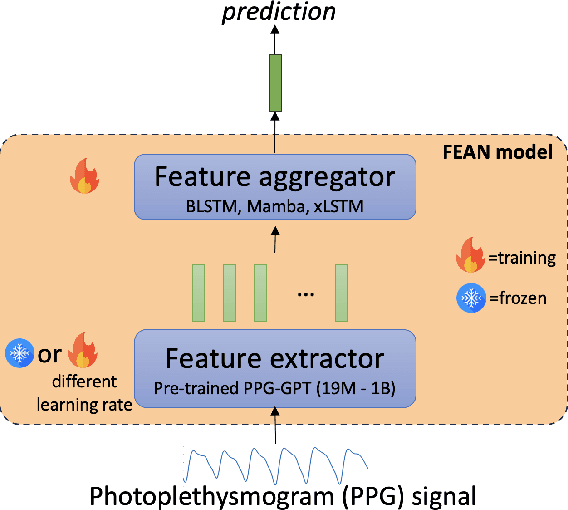
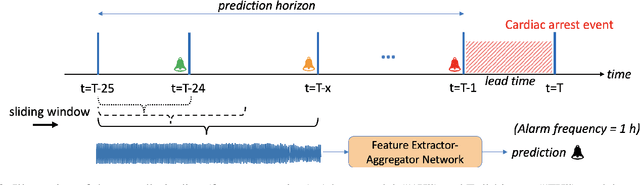
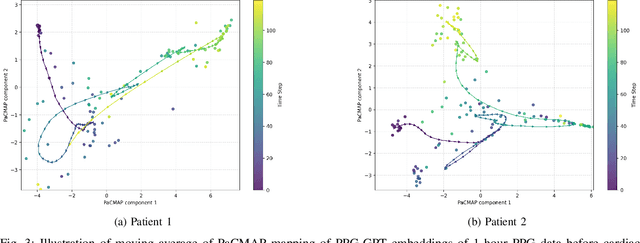
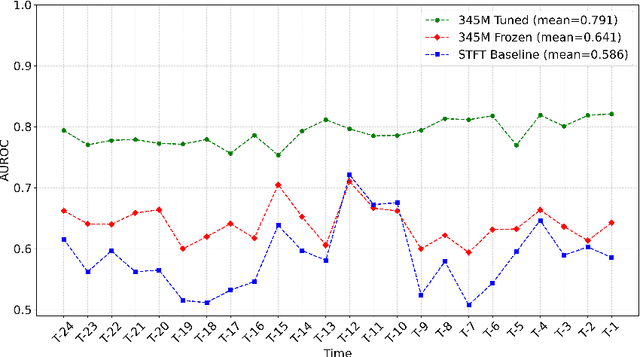
Non-invasive patient monitoring for tracking and predicting adverse acute health events is an emerging area of research. We pursue in-hospital cardiac arrest (IHCA) prediction using only single-channel finger photoplethysmography (PPG) signals. Our proposed two-stage model Feature Extractor-Aggregator Network (FEAN) leverages powerful representations from pre-trained PPG foundation models (PPG-GPT of size up to 1 Billion) stacked with sequential classification models. We propose two FEAN variants ("1H", "FH") which use the latest one-hour and (max) 24-hour history to make decisions respectively. Our study is the first to present IHCA prediction results in ICU patients using only unimodal (continuous PPG signal) waveform deep representations. With our best model, we obtain an average of 0.79 AUROC over 24~h prediction window before CA event onset with our model peaking performance at 0.82 one hour before CA. We also provide a comprehensive analysis of our model through architectural tuning and PaCMAP visualization of patient health trajectory in latent space.
Early Risk Prediction of Pediatric Cardiac Arrest from Electronic Health Records via Multimodal Fused Transformer
Feb 11, 2025Early prediction of pediatric cardiac arrest (CA) is critical for timely intervention in high-risk intensive care settings. We introduce PedCA-FT, a novel transformer-based framework that fuses tabular view of EHR with the derived textual view of EHR to fully unleash the interactions of high-dimensional risk factors and their dynamics. By employing dedicated transformer modules for each modality view, PedCA-FT captures complex temporal and contextual patterns to produce robust CA risk estimates. Evaluated on a curated pediatric cohort from the CHOA-CICU database, our approach outperforms ten other artificial intelligence models across five key performance metrics and identifies clinically meaningful risk factors. These findings underscore the potential of multimodal fusion techniques to enhance early CA detection and improve patient care.
Dynamic Token Reduction during Generation for Vision Language Models
Jan 24, 2025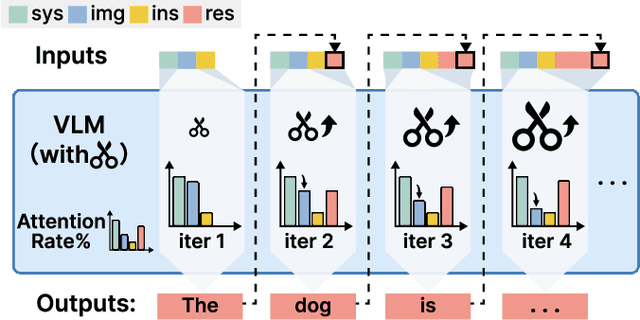
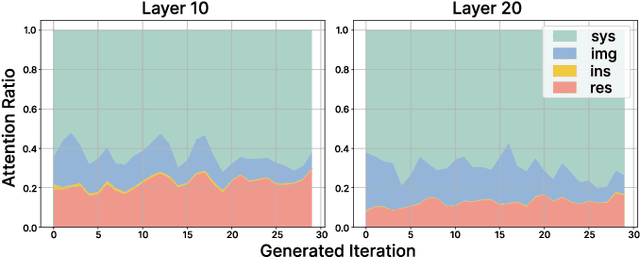
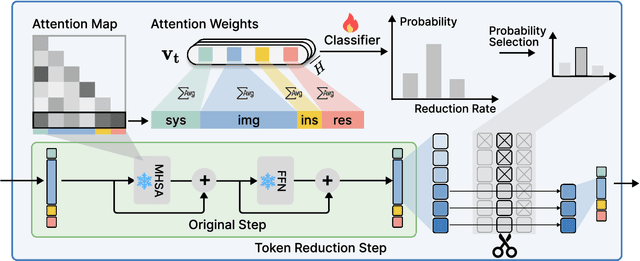

Vision-Language Models (VLMs) have achieved notable success in multimodal tasks but face practical limitations due to the quadratic complexity of decoder attention mechanisms and autoregressive generation. Existing methods like FASTV and VTW have achieved notable results in reducing redundant visual tokens, but these approaches focus on pruning tokens in a single forward pass without systematically analyzing the redundancy of visual tokens throughout the entire generation process. In this paper, we introduce a dynamic pruning strategy tailored for VLMs, namedDynamic Rate (DyRate), which progressively adjusts the compression rate during generation. Our analysis of the distribution of attention reveals that the importance of visual tokens decreases throughout the generation process, inspiring us to adopt a more aggressive compression rate. By integrating a lightweight predictor based on attention distribution, our approach enables flexible adjustment of pruning rates based on the attention distribution. Our experimental results demonstrate that our method not only reduces computational demands but also maintains the quality of responses.