 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Inference-Time Augmentation Framework in Physiological Signals: Application to PPG-Based AF Detection
Jun 09, 2026Objective: Accurate classification of physiological signals in real-world deployments is challenged by sensor noise, motion artifacts, and distribution shifts between training and deployment data. Inference-time augmentation (ITA), which applies augmentations during inference rather than retraining, offers a simple, model-agnostic mechanism to improve robustness. However, ITA application to physiological signals has remained narrow in scope, relying on limited augmentation methods with fixed, unoptimized parameters. This work proposes a unified ITA framework to address that gap. Approach: The framework incorporates 13 augmentation methods spanning time-domain, amplitude-domain, frequency-domain, and artifact-injection transformations, with hyperparameters optimized via Bayesian optimization. We evaluate on atrial fibrillation (AF) detection from 30-second PPG signals using GPT-PPG and ResNet across five datasets comprising more than 400 patients and ${\sim}$9,800 hours of recording. Main results: Standard ITA consistently improved AUROC (up to 8.5% for GPT-PPG and 0.7% for ResNet) and AUPRC (up to 10.6% for GPT-PPG and 0.8% for ResNet). Selective ITA further reduced average FPR by up to 4.4% (GPT-PPG) and 1.3% (ResNet) on non-AF datasets. Significance: These findings establish ITA as a practical, model-agnostic approach for improving PPG-based AF classification reliability in deployment settings where retraining is not feasible, with broader applicability to physiological signal analysis.
Prompt Amplification and Zero-Shot Late Fusion in Audio-Language Models for Speech Emotion Recognition
Mar 24, 2026Audio-Language Models (ALMs) are making strides in understanding speech and non-speech audio. However, domain-specialist Foundation Models (FMs) remain the best for closed-ended speech processing tasks such as Speech Emotion Recognition (SER). Using ALMs for Zero-shot SER is a popular choice, but their potential to work with specialists to achieve state-of-the-art (SOTA) performance remains unexplored. We propose ZS-Fuse, a late-fusion method that combines zero-shot emotion estimates from a dual-encoder ALM with specialist FMs. To handle ambiguity in emotions and sensitivity to prompt choice, 1) we use a simple prompt ensemble and 2) suggest a novel technique called prompt amplification, which repeats audio and text queries to discover stronger zero-shot capabilities. We demonstrate the efficacy of our technique by evaluating ZS-Fuse with three dual-encoder ALMs and two FMs, and report improvements over SOTA baselines, such as WavLM-Large, on three speech emotion recognition datasets.
Generalist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025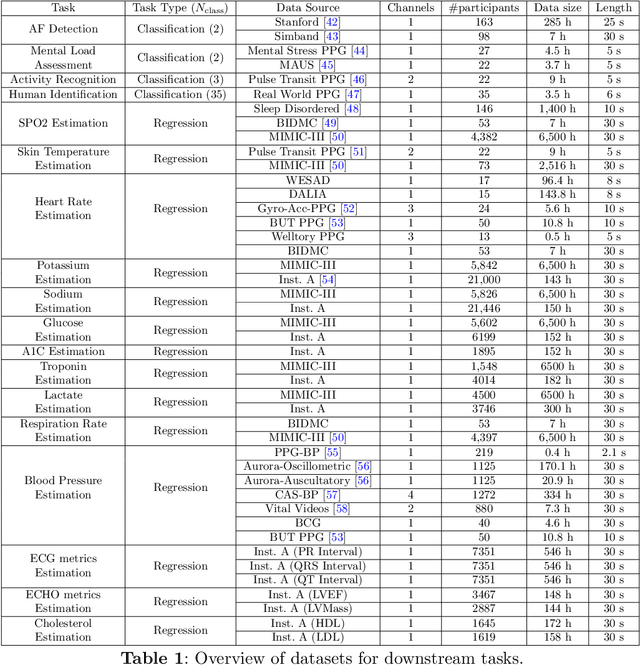
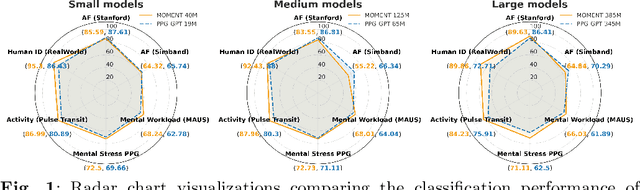
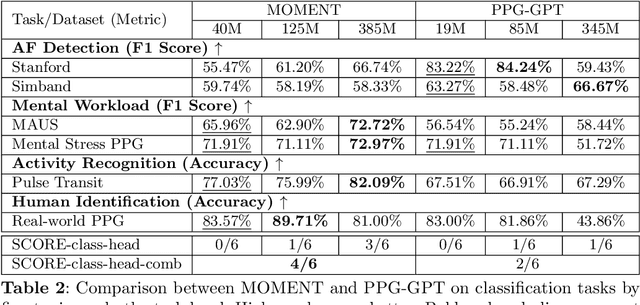
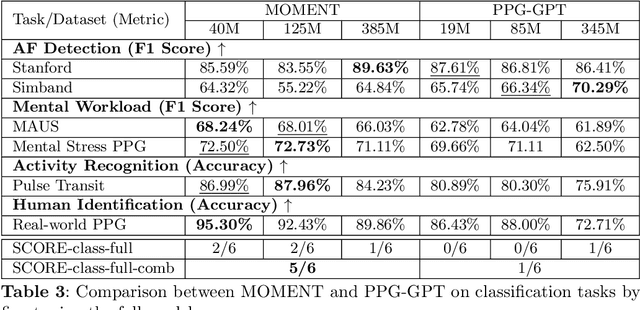
Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
Large Scale Retrieval for the LinkedIn Feed using Causal Language Models
Oct 16, 2025


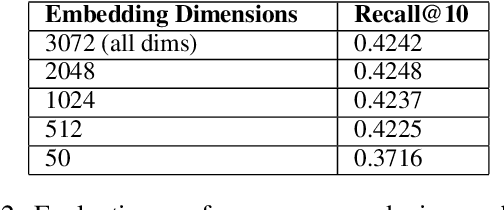
In large scale recommendation systems like the LinkedIn Feed, the retrieval stage is critical for narrowing hundreds of millions of potential candidates to a manageable subset for ranking. LinkedIn's Feed serves suggested content from outside of the member's network (based on the member's topical interests), where 2000 candidates are retrieved from a pool of hundreds of millions candidate with a latency budget of a few milliseconds and inbound QPS of several thousand per second. This paper presents a novel retrieval approach that fine-tunes a large causal language model (Meta's LLaMA 3) as a dual encoder to generate high quality embeddings for both users (members) and content (items), using only textual input. We describe the end to end pipeline, including prompt design for embedding generation, techniques for fine-tuning at LinkedIn's scale, and infrastructure for low latency, cost effective online serving. We share our findings on how quantizing numerical features in the prompt enables the information to get properly encoded in the embedding, facilitating greater alignment between the retrieval and ranking layer. The system was evaluated using offline metrics and an online A/B test, which showed substantial improvements in member engagement. We observed significant gains among newer members, who often lack strong network connections, indicating that high-quality suggested content aids retention. This work demonstrates how generative language models can be effectively adapted for real time, high throughput retrieval in industrial applications.
GPT-PPG: A GPT-based Foundation Model for Photoplethysmography Signals
Mar 11, 2025This study introduces a novel application of a Generative Pre-trained Transformer (GPT) model tailored for photoplethysmography (PPG) signals, serving as a foundation model for various downstream tasks. Adapting the standard GPT architecture to suit the continuous characteristics of PPG signals, our approach demonstrates promising results. Our models are pre-trained on our extensive dataset that contains more than 200 million 30s PPG samples. We explored different supervised fine-tuning techniques to adapt our model to downstream tasks, resulting in performance comparable to or surpassing current state-of-the-art (SOTA) methods in tasks like atrial fibrillation detection. A standout feature of our GPT model is its inherent capability to perform generative tasks such as signal denoising effectively, without the need for further fine-tuning. This success is attributed to the generative nature of the GPT framework.
Continuous Cardiac Arrest Prediction in ICU using PPG Foundation Model
Feb 12, 2025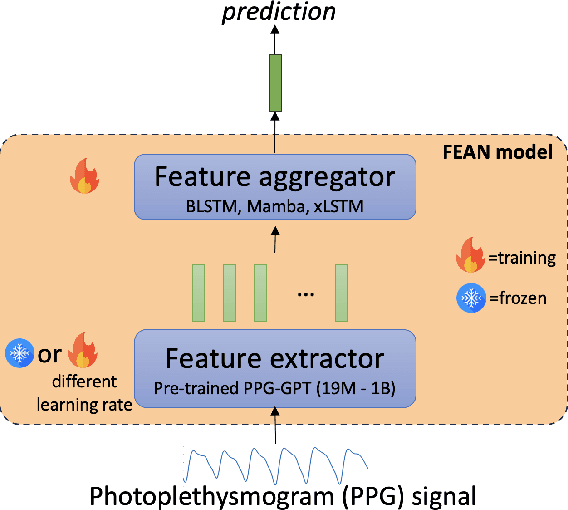
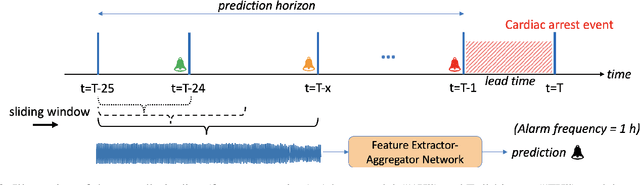
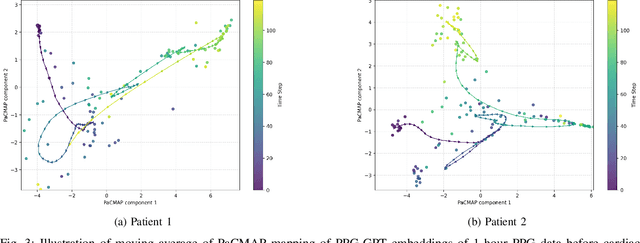
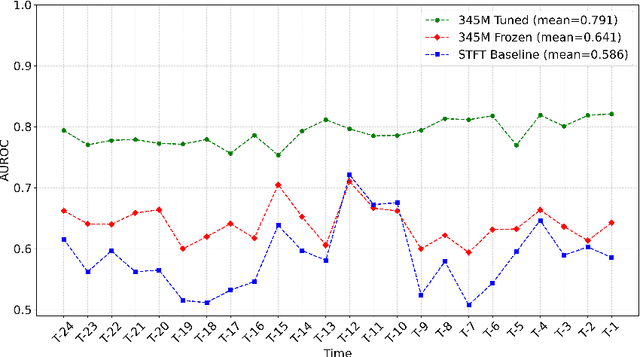
Non-invasive patient monitoring for tracking and predicting adverse acute health events is an emerging area of research. We pursue in-hospital cardiac arrest (IHCA) prediction using only single-channel finger photoplethysmography (PPG) signals. Our proposed two-stage model Feature Extractor-Aggregator Network (FEAN) leverages powerful representations from pre-trained PPG foundation models (PPG-GPT of size up to 1 Billion) stacked with sequential classification models. We propose two FEAN variants ("1H", "FH") which use the latest one-hour and (max) 24-hour history to make decisions respectively. Our study is the first to present IHCA prediction results in ICU patients using only unimodal (continuous PPG signal) waveform deep representations. With our best model, we obtain an average of 0.79 AUROC over 24~h prediction window before CA event onset with our model peaking performance at 0.82 one hour before CA. We also provide a comprehensive analysis of our model through architectural tuning and PaCMAP visualization of patient health trajectory in latent space.
Self-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023



Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
Time-domain speech super-resolution with GAN based modeling for telephony speaker verification
Sep 04, 2022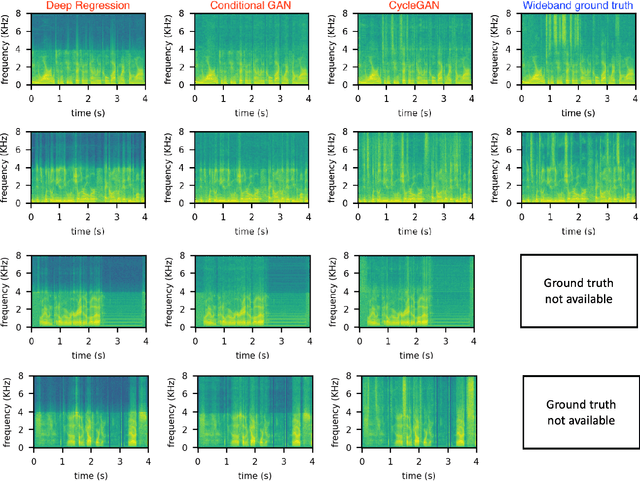
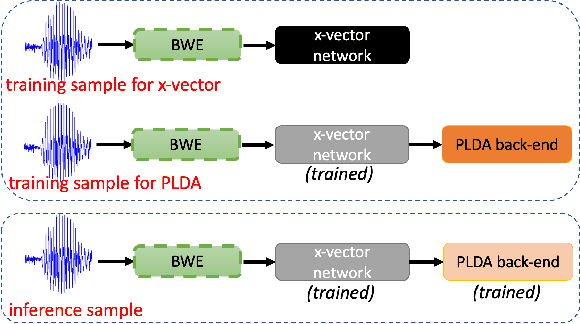
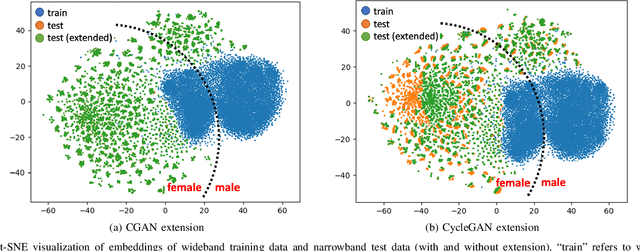
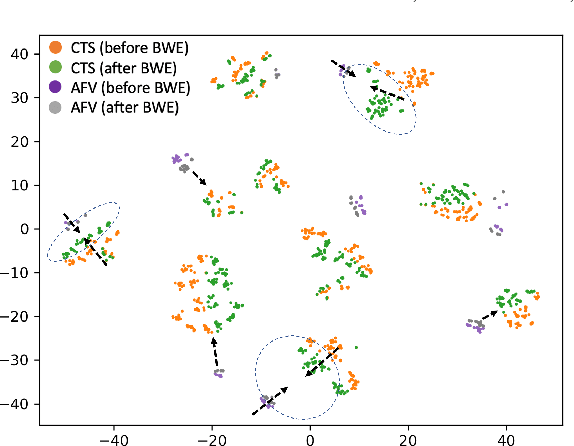
Automatic Speaker Verification (ASV) technology has become commonplace in virtual assistants. However, its performance suffers when there is a mismatch between the train and test domains. Mixed bandwidth training, i.e., pooling training data from both domains, is a preferred choice for developing a universal model that works for both narrowband and wideband domains. We propose complementing this technique by performing neural upsampling of narrowband signals, also known as bandwidth extension. Our main goal is to discover and analyze high-performing time-domain Generative Adversarial Network (GAN) based models to improve our downstream state-of-the-art ASV system. We choose GANs since they (1) are powerful for learning conditional distribution and (2) allow flexible plug-in usage as a pre-processor during the training of downstream task (ASV) with data augmentation. Prior works mainly focus on feature-domain bandwidth extension and limited experimental setups. We address these limitations by 1) using time-domain extension models, 2) reporting results on three real test sets, 2) extending training data, and 3) devising new test-time schemes. We compare supervised (conditional GAN) and unsupervised GANs (CycleGAN) and demonstrate average relative improvement in Equal Error Rate of 8.6% and 7.7%, respectively. For further analysis, we study changes in spectrogram visual quality, audio perceptual quality, t-SNE embeddings, and ASV score distributions. We show that our bandwidth extension leads to phenomena such as a shift of telephone (test) embeddings towards wideband (train) signals, a negative correlation of perceptual quality with downstream performance, and condition-independent score calibration.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
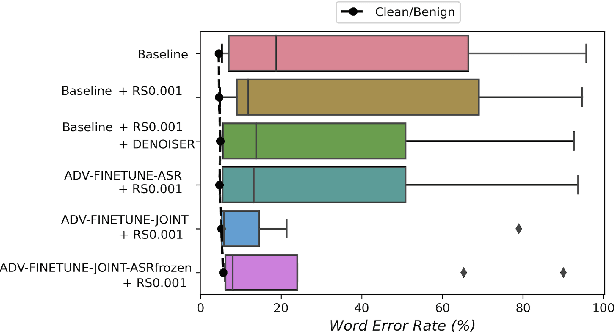

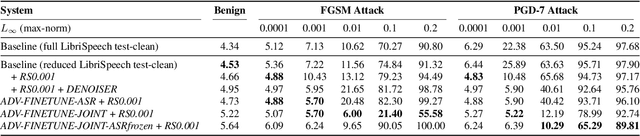
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
AdvEst: Adversarial Perturbation Estimation to Classify and Detect Adversarial Attacks against Speaker Identification
Apr 08, 2022
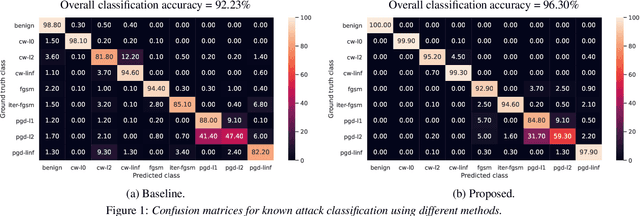

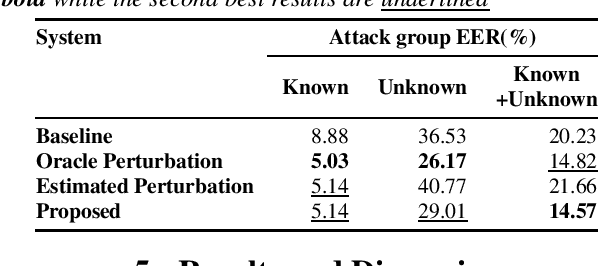
Adversarial attacks pose a severe security threat to the state-of-the-art speaker identification systems, thereby making it vital to propose countermeasures against them. Building on our previous work that used representation learning to classify and detect adversarial attacks, we propose an improvement to it using AdvEst, a method to estimate adversarial perturbation. First, we prove our claim that training the representation learning network using adversarial perturbations as opposed to adversarial examples (consisting of the combination of clean signal and adversarial perturbation) is beneficial because it eliminates nuisance information. At inference time, we use a time-domain denoiser to estimate the adversarial perturbations from adversarial examples. Using our improved representation learning approach to obtain attack embeddings (signatures), we evaluate their performance for three applications: known attack classification, attack verification, and unknown attack detection. We show that common attacks in the literature (Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), Carlini-Wagner (CW) with different Lp threat models) can be classified with an accuracy of ~96%. We also detect unknown attacks with an equal error rate (EER) of ~9%, which is absolute improvement of ~12% from our previous work.